commit 10e44239f6 upstream.
The recent change for USB-audio disconnection race fixes introduced a
mutex deadlock again. There is a circular dependency between
chip->shutdown_rwsem and pcm->open_mutex, depicted like below, when a
device is opened during the disconnection operation:
A. snd_usb_audio_disconnect() ->
card.c::register_mutex ->
chip->shutdown_rwsem (write) ->
snd_card_disconnect() ->
pcm.c::register_mutex ->
pcm->open_mutex
B. snd_pcm_open() ->
pcm->open_mutex ->
snd_usb_pcm_open() ->
chip->shutdown_rwsem (read)
Since the chip->shutdown_rwsem protection in the case A is required
only for turning on the chip->shutdown flag and it doesn't have to be
taken for the whole operation, we can reduce its window in
snd_usb_audio_disconnect().
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit aee77e4acc upstream.
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b00e69dee4 upstream.
This regression was spotted between Debian squeeze and Debian wheezy
kernels (respectively based on 2.6.32 and 3.2). More info about
Wake-on-LAN issues with Realtek's 816x chipsets can be found in the
following thread: http://marc.info/?t=132079219400004
Probable regression from d4ed95d796e5126bba51466dc07e287cebc8bd19;
more chipsets are likely affected.
Tested on top of a 3.2.23 kernel.
Reported-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Tested-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Hinted-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: Cyril Brulebois <kibi@debian.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5f5b331d5c upstream.
The issue occurs when eCryptfs is mounted with a cipher supported by
the crypto subsystem but not by eCryptfs. The mount succeeds and an
error does not occur until a write. This change checks for eCryptfs
cipher support at mount time.
Resolves Launchpad issue #338914, reported by Tyler Hicks in 03/2009.
https://bugs.launchpad.net/ecryptfs/+bug/338914
Signed-off-by: Tim Sally <tsally@atomicpeace.com>
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 069ddcda37 upstream.
When the eCryptfs mount options do not include '-o acl', but the lower
filesystem's mount options do include 'acl', the MS_POSIXACL flag is not
flipped on in the eCryptfs super block flags. This flag is what the VFS
checks in do_last() when deciding if the current umask should be applied
to a newly created inode's mode or not. When a default POSIX ACL mask is
set on a directory, the current umask is incorrectly applied to new
inodes created in the directory. This patch ignores the MS_POSIXACL flag
passed into ecryptfs_mount() and sets the flag on the eCryptfs super
block depending on the flag's presence on the lower super block.
Additionally, it is incorrect to allow a writeable eCryptfs mount on top
of a read-only lower mount. This missing check did not allow writes to
the read-only lower mount because permissions checks are still performed
on the lower filesystem's objects but it is best to simply not allow a
rw mount on top of ro mount. However, a ro eCryptfs mount on top of a rw
mount is valid and still allowed.
https://launchpad.net/bugs/1009207
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Stefan Beller <stefanbeller@googlemail.com>
Cc: John Johansen <john.johansen@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 60713a0ca7 ]
As documented in RFC4861 (Neighbor Discovery for IP version 6) 7.2.6.,
unsolicited neighbour advertisements should be sent to the all-nodes
multicast address.
Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit a3d744e995 ]
Due to a NULL dereference, the following patch is causing oops
in normal trafic condition:
commit c0de08d042
Author: Eric Leblond <eric@regit.org>
Date: Thu Aug 16 22:02:58 2012 +0000
af_packet: don't emit packet on orig fanout group
This buggy patch was a feature fix and has reached most stable
branches.
When skb->sk is NULL and when packet fanout is used, there is a
crash in match_fanout_group where skb->sk is accessed.
This patch fixes the issue by returning false as soon as the
socket is NULL: this correspond to the wanted behavior because
the kernel as to resend the skb to all the listening socket in
this case.
Signed-off-by: Eric Leblond <eric@regit.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 789336360e ]
When creating an L2TPv3 Ethernet session, if register_netdev() should fail for
any reason (for example, automatic naming for "l2tpeth%d" interfaces hits the
32k-interface limit), the netdev is freed in the error path. However, the
l2tp_eth_sess structure's dev pointer is left uncleared, and this results in
l2tp_eth_delete() then attempting to unregister the same netdev later in the
session teardown. This results in an oops.
To avoid this, clear the session dev pointer in the error path.
Signed-off-by: Tom Parkin <tparkin@katalix.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 8f363b77ee ]
Reading TCP stats when using TCP Illinois congestion control algorithm
can cause a divide by zero kernel oops.
The division by zero occur in tcp_illinois_info() at:
do_div(t, ca->cnt_rtt);
where ca->cnt_rtt can become zero (when rtt_reset is called)
Steps to Reproduce:
1. Register tcp_illinois:
# sysctl -w net.ipv4.tcp_congestion_control=illinois
2. Monitor internal TCP information via command "ss -i"
# watch -d ss -i
3. Establish new TCP conn to machine
Either it fails at the initial conn, or else it needs to wait
for a loss or a reset.
This is only related to reading stats. The function avg_delay() also
performs the same divide, but is guarded with a (ca->cnt_rtt > 0) at its
calling point in update_params(). Thus, simply fix tcp_illinois_info().
Function tcp_illinois_info() / get_info() is called without
socket lock. Thus, eliminate any race condition on ca->cnt_rtt
by using a local stack variable. Simply reuse info.tcpv_rttcnt,
as its already set to ca->cnt_rtt.
Function avg_delay() is not affected by this race condition, as
its called with the socket lock.
Cc: Petr Matousek <pmatouse@redhat.com>
Signed-off-by: Jesper Dangaard Brouer <brouer@redhat.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Acked-by: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 39707c2a3b ]
Driver anchors the tx urbs and defers the urb submission if
a transmit request comes when the interface is suspended.
Anchoring urb increments the urb reference count. These
deferred urbs are later accessed by calling usb_get_from_anchor()
for submission during interface resume. usb_get_from_anchor()
unanchors the urb but urb reference count remains same.
This causes the urb reference count to remain non-zero
after usb_free_urb() gets called and urb never gets freed.
Hence call usb_put_urb() after anchoring the urb to properly
balance the reference count for these deferred urbs. Also,
unanchor these deferred urbs during disconnect, to free them
up.
Signed-off-by: Hemant Kumar <hemantk@codeaurora.org>
Acked-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 14edd87dc6 ]
Commit a02e4b7dae4551(Demark default hoplimit as zero) only changes the
hoplimit checking condition and default value in ip6_dst_hoplimit, not
zeros all hoplimit default value.
Keep the zeroing ip6_template_metrics[RTAX_HOPLIMIT - 1] to force it as
const, cause as a37e6e344910(net: force dst_default_metrics to const
section)
Signed-off-by: Li RongQing <roy.qing.li@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit a3374c42aa ]
tcp_ioctl() tries to take into account if tcp socket received a FIN
to report correct number bytes in receive queue.
But its flaky because if the application ate the last skb,
we return 1 instead of 0.
Correct way to detect that FIN was received is to test SOCK_DONE.
Reported-by: Elliot Hughes <enh@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Neal Cardwell <ncardwell@google.com>
Cc: Tom Herbert <therbert@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 6d772ac557 ]
On some suspend/resume operations involving wimax device, we have
noticed some intermittent memory corruptions in netlink code.
Stéphane Marchesin tracked this corruption in netlink_update_listeners()
and suggested a patch.
It appears netlink_release() should use kfree_rcu() instead of kfree()
for the listeners structure as it may be used by other cpus using RCU
protection.
netlink_release() must set to NULL the listeners pointer when
it is about to be freed.
Also have to protect netlink_update_listeners() and
netlink_has_listeners() if listeners is NULL.
Add a nl_deref_protected() lockdep helper to properly document which
locks protects us.
Reported-by: Jonathan Kliegman <kliegs@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Stéphane Marchesin <marcheu@google.com>
Cc: Sam Leffler <sleffler@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b0a8cc58e6 upstream.
In kswapd(), set current->reclaim_state to NULL before returning, as
current->reclaim_state holds reference to variable on kswapd()'s stack.
In rare cases, while returning from kswapd() during memory offlining,
__free_slab() and freepages() can access the dangling pointer of
current->reclaim_state.
Signed-off-by: Takamori Yamaguchi <takamori.yamaguchi@jp.sony.com>
Signed-off-by: Aaditya Kumar <aaditya.kumar@ap.sony.com>
Acked-by: David Rientjes <rientjes@google.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6ce377afd1 upstream.
Commit 4439647 ("xfs: reset buffer pointers before freeing them") in
3.0-rc1 introduced a regression when recovering log buffers that
wrapped around the end of log. The second part of the log buffer at
the start of the physical log was being read into the header buffer
rather than the data buffer, and hence recovery was seeing garbage
in the data buffer when it got to the region of the log buffer that
was incorrectly read.
Reported-by: Torsten Kaiser <just.for.lkml@googlemail.com>
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Mark Tinguely <tinguely@sgi.com>
Signed-off-by: Ben Myers <bpm@sgi.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8bb4d9ce08 upstream.
There are uncovered cases whether the card refcount introduced by the
commit a0830dbd isn't properly increased or decreased:
- OSS PCM and mixer success paths
- When lookup function gets NULL
This patch fixes these places.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=50251
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ef4da45828 upstream.
VT1802 codec provides the invalid connection lists of NID 0x24 and
0x33 containing the routes to a non-exist widget 0x3e. This confuses
the auto-parser. Fix it up in the driver by overriding these
connections.
Reported-by: Massimo Del Fedele <max@veneto.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5b3761954d upstream.
In via_auto_fill_adc_nids(), the parser tries to fill dac_nids[] at
the point of the current line-out (i). When no valid path is found
for this output, this results in dac = 0, thus it creates a hole in
dac_nids[]. This confuses is_empty_dac() and trims the detected DAC
in later reference.
This patch fixes the bug by appending DAC properly to dac_nids[] in
via_auto_fill_adc_nids().
Reported-by: Massimo Del Fedele <max@veneto.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3300fb4f88 upstream.
Don't assume bank 0 is selected at device probe time. This may not be
the case. Force bank selection at first register access to guarantee
that we read the right registers upon driver loading.
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 16337e028a upstream.
Correctly enable the digital microphones with the right bits in the
right coeffecient registers on Cirrus CS4206/7 codecs. It also
prevents misconfiguring ADC1/2.
This fixes the digital mic on the Macbook Pro 10,1/Retina.
Based-on-patch-by: Alexander Stein <alexander.stein@systec-electronic.com>
Signed-off-by: Daniel J Blueman <daniel@quora.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 36960e440c upstream.
The userspace cifs.idmap program generally works with the wbclient libs
to generate binary SIDs in userspace. That program defines the struct
that holds these values as having a max of 15 subauthorities. The kernel
idmapping code however limits that value to 5.
When the kernel copies those values around though, it doesn't sanity
check the num_subauths value handed back from userspace or from the
server. It's possible therefore for userspace to hand us back a bogus
num_subauths value (or one that's valid, but greater than 5) that could
cause the kernel to walk off the end of the cifs_sid->sub_auths array.
Fix this by defining a new routine for copying sids and using that in
all of the places that copy it. If we end up with a sid that's longer
than expected then this approach will just lop off the "extra" subauths,
but that's basically what the code does today already. Better approaches
might be to fix this code to reject SIDs with >5 subauths, or fix it
to handle the subauths array dynamically.
At the same time, change the kernel to check the length of the data
returned by userspace. If it's shorter than struct cifs_sid, reject it
and return -EIO. If that happens we'll end up with fields that are
basically uninitialized.
Long term, it might make sense to redefine cifs_sid using a flexarray at
the end, to allow for variable-length subauth lists, and teach the code
to handle the case where the subauths array being passed in from
userspace is shorter than 5 elements.
Note too, that I don't consider this a security issue since you'd need
a compromised cifs.idmap program. If you have that, you can do all sorts
of nefarious stuff. Still, this is probably reasonable for stable.
Reviewed-by: Shirish Pargaonkar <shirishpargaonkar@gmail.com>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d5627acba9 upstream.
The sleeping code in iscsi_target_tx_thread() is susceptible to the classic
missed wakeup race:
- TX thread finishes handle_immediate_queue() and handle_response_queue(),
thinks both queues are empty.
- Another thread adds a queue entry and does wake_up_process(), which does
nothing because the TX thread is still awake.
- TX thread does schedule_timeout() and sleeps forever.
In practice this can kill an iSCSI connection if for example an initiator
does single-threaded writes and the target misses the wakeup window when
queueing an R2T; in this case the connection will be stuck until the
initiator loses patience and does some task management operation (or kills
the connection entirely).
Fix this by converting to wait_event_interruptible(), which does not
suffer from this sort of race.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Cc: Andy Grover <agrover@redhat.com>
Cc: Hannes Reinecke <hare@suse.de>
Cc: Christoph Hellwig <hch@lst.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3e03989b58 upstream.
The expression (max_sectors * block_size) might overflow a u32
(indeed, since iblock sets max_hw_sectors to UINT_MAX, it is
guaranteed to overflow and end up with a much-too-small result in many
common cases). Fix this by doing an equivalent calculation that
doesn't require multiplication.
While we're touching this code, avoid splitting a printk format across
two lines and use pr_info(...) instead of printk(KERN_INFO ...).
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0d0f9dfb31 upstream.
If the call to core_dev_release_virtual_lun0() fails, then nothing
sets ret to anything other than 0, so even though everything is
torn down and freed, target_core_init_configfs() will seem to succeed
and the module will be loaded. Fix this by passing the return value
on up the chain.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 97a5486826 upstream.
Since commit c7f404b ('vfs: new superblock methods to override
/proc/*/mount{s,info}'), nfs_path() is used to generate the mounted
device name reported back to userland.
nfs_path() always generates a trailing slash when the given dentry is
the root of an NFS mount, but userland may expect the original device
name to be returned verbatim (as it used to be). Make this
canonicalisation optional and change the callers accordingly.
[jrnieder@gmail.com: use flag instead of bool argument]
Reported-and-tested-by: Chris Hiestand <chiestand@salk.edu>
Reference: http://bugs.debian.org/669314
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2:
- Adjust context
- nfs_show_devname() still takes a pointer to struct vfsmount]
commit acce94e68a upstream.
In very busy v3 environment, rpc.mountd can respond to the NULL
procedure but not the MNT procedure in a timely manner causing
the MNT procedure to time out. The problem is the mount system
call returns EIO which causes the mount to fail, instead of
ETIMEDOUT, which would cause the mount to be retried.
This patch sets the RPC_TASK_SOFT|RPC_TASK_TIMEOUT flags to
the rpc_call_sync() call in nfs_mount() which causes
ETIMEDOUT to be returned on timed out connections.
Signed-off-by: Steve Dickson <steved@redhat.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8d96b10639 upstream.
The DNS resolver's use of the sunrpc cache involves a 'ttl' number
(relative) rather that a timeout (absolute). This confused me when
I wrote
commit c5b29f885a
"sunrpc: use seconds since boot in expiry cache"
and I managed to break it. The effect is that any TTL is interpreted
as 0, and nothing useful gets into the cache.
This patch removes the use of get_expiry() - which really expects an
expiry time - and uses get_uint() instead, treating the int correctly
as a ttl.
This fixes a regression that has been present since 2.6.37, causing
certain NFS accesses in certain environments to incorrectly fail.
Reported-by: Chuck Lever <chuck.lever@oracle.com>
Tested-by: Chuck Lever <chuck.lever@oracle.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2b1bc308f4 upstream.
If the state recovery machinery is triggered by the call to
nfs4_async_handle_error() then we can deadlock.
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2240a9e2d0 upstream.
If we do not release the sequence id in cases where we fail to get a
session slot, then we can deadlock if we hit a recovery scenario.
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2:
- Adjust context
- nfs4_setup_sequence() has an additional 'cache_reply' parameter]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 399f11c3d8 upstream.
Currently, we will schedule session recovery and then return to the
caller of nfs4_handle_exception. This works for most cases, but causes
a hang on the following test case:
Client Server
------ ------
Open file over NFS v4.1
Write to file
Expire client
Try to lock file
The server will return NFS4ERR_BADSESSION, prompting the client to
schedule recovery. However, the client will continue placing lock
attempts and the open recovery never seems to be scheduled. The
simplest solution is to wait for session recovery to run before retrying
the lock.
Signed-off-by: Bryan Schumaker <bjschuma@netapp.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 95a7d76897 upstream.
As Mukesh explained it, the MMUEXT_TLB_FLUSH_ALL allows the
hypervisor to do a TLB flush on all active vCPUs. If instead
we were using the generic one (which ends up being xen_flush_tlb)
we end up making the MMUEXT_TLB_FLUSH_LOCAL hypercall. But
before we make that hypercall the kernel will IPI all of the
vCPUs (even those that were asleep from the hypervisor
perspective). The end result is that we needlessly wake them
up and do a TLB flush when we can just let the hypervisor
do it correctly.
This patch gives around 50% speed improvement when migrating
idle guest's from one host to another.
Oracle-bug: 14630170
Tested-by: Jingjie Jiang <jingjie.jiang@oracle.com>
Suggested-by: Mukesh Rathor <mukesh.rathor@oracle.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3ccc60f9d8 upstream.
Microsoft Digital Media Keyboard 3000 has two interfaces, and the
second one has a report descriptor with a bug. The second collection
says:
05 01 -- global; usage page -- 01 -- Generic Desktop Controls
09 80 -- local; usage -- 80 -- System Control
a1 01 -- main; collection -- 01 -- application
85 03 -- global; report ID -- 03
19 00 -- local; Usage Minimum -- 00
29 ff -- local; Usage Maximum -- ff
15 00 -- global; Logical Minimum -- 0
26 ff 00 -- global; Logical Maximum -- ff
81 00 -- main; input
c0 -- main; End Collection
I.e. it makes us think that there are all kinds of usages of system
control. That the keyboard is a not only a keyboard, but also a
joystick, mouse, gamepad, keypad, etc. The same as for the Wireless
Desktop Receiver, this should be Physical Min/Max. So fix that
appropriately.
References: https://bugzilla.novell.com/show_bug.cgi?id=776834
Signed-off-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 32ed1911fc upstream.
The tsc40 driver announces it supports the pressure event, but will never
send one. The announcement will cause tslib to wait for such events and
sending all touch events with a pressure of 0. Removing the announcement
will make tslib fall back to emulating the pressure on touch events so
everything works as expected.
Signed-off-by: Rolf Eike Beer <eike-kernel@sf-tec.de>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 59ef28b1f1 upstream.
Masaki found and patched a kallsyms issue: the last symbol in a
module's symtab wasn't transferred. This is because we manually copy
the zero'th entry (which is always empty) then copy the rest in a loop
starting at 1, though from src[0]. His fix was minimal, I prefer to
rewrite the loops in more standard form.
There are two loops: one to get the size, and one to copy. Make these
identical: always count entry 0 and any defined symbol in an allocated
non-init section.
This bug exists since the following commit was introduced.
module: reduce symbol table for loaded modules (v2)
commit: 4a4962263f
LKML: http://lkml.org/lkml/2012/10/24/27
Reported-by: Masaki Kimura <masaki.kimura.kz@hitachi.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
[bwh: Backported to 3.2: we're still using a bitmap to compress the string
table]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6fe7cc71bb upstream.
The ath9k xmit functions for AMPDUs can send frames as non-aggregate in case
only one frame is currently available. The client will then answer using a
normal Ack instead of a BlockAck. This acknowledgement has no TID stored and
therefore the hardware is not able to provide us the corresponding TID.
The TID set by the hardware in the tx status descriptor has to be seen as
undefined and not as a valid TID value for normal acknowledgements. Doing
otherwise results in a massive amount of retransmissions and stalls of
connections.
Users may experience low bandwidth and complete connection stalls in
environments with transfers using multiple TIDs.
This regression was introduced in b11b160def
("ath9k: validate the TID in the tx status information").
Signed-off-by: Sven Eckelmann <sven@narfation.org>
Signed-off-by: Simon Wunderlich <siwu@hrz.tu-chemnitz.de>
Acked-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bf7e1abe43 upstream.
Some hardware has correct (!= 0xff) value of tssi_bounds[4] in the
EEPROM, but step is equal to 0xff. This results on ridiculous delta
calculations and completely broke TX power settings.
Reported-and-tested-by: Pavel Lucik <pavel.lucik@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a67baeb773 upstream.
map->kmap_ops allocated in gntdev_alloc_map() wasn't freed by
gntdev_put_map().
Add a gntdev_free_map() helper function to free everything allocated
by gntdev_alloc_map().
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d60e7ec18c upstream.
On floppy initialization, if something failed inside the loop we call
add_disk, there was no cleanup of previous iterations in the error
handling.
Signed-off-by: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8c6e30936a upstream.
bf->bf_next is only while buffers are chained as part of an A-MPDU
in the tx queue. When a tid queue is flushed (e.g. on tearing down
an aggregation session), frames can be enqueued again as normal
transmission, without bf_next being cleared. This can lead to the
old pointer being dereferenced again later.
This patch might fix crashes and "Failed to stop TX DMA!" messages.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6dbda2d00d upstream.
The code to allow EAPOL frames even when the station
isn't yet marked associated needs to check that the
incoming frame is long enough and due to paged RX it
also can't assume skb->data contains the right data,
it must use skb_copy_bits(). Fix this to avoid using
data that doesn't really exist.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9b395bc3be upstream.
A number of places in the mesh code don't check that
the frame data is present and in the skb header when
trying to access. Add those checks and the necessary
pskb_may_pull() calls. This prevents accessing data
that doesn't actually exist.
To do this, export ieee80211_get_mesh_hdrlen() to be
able to use it in mac80211.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4a4f1a5808 upstream.
Due to pskb_may_pull() checking the skb length, all
non-management frames are checked on input whether
their 802.11 header is fully present. Also add that
check for management frames and remove a check that
is now duplicate. This prevents accessing skb data
beyond the frame end.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7dd111e8ee upstream.
The mesh header can have address extension by a 4th
or a 5th and 6th address, but never both. Drop such
frames in 802.11 -> 802.3 conversion along with any
frames that have the wrong extension.
Reviewed-by: Javier Cardona <javier@cozybit.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit badecb001a upstream.
The 'ssid' field of the cfg80211_ibss_params is a u8 pointer and
its length is likely to be less than IEEE80211_MAX_SSID_LEN most
of the time.
This patch fixes the ssid copy in ieee80211_ibss_join() by using
the SSID length to prevent it from reading beyond the string.
Signed-off-by: Antonio Quartulli <ordex@autistici.org>
[rewrapped commit message, small rewording]
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f7fbf70ee9 upstream.
Per IEEE Std. 802.11-2012, Sec 8.2.4.4.1, the sequence Control field is
not present in control frames. We noticed this problem when processing
Block Ack Requests.
Signed-off-by: Javier Cardona <javier@cozybit.com>
Signed-off-by: Javier Lopez <jlopex@cozybit.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 555cb715be upstream.
Doing otherwise is wrong, and may wreak havoc on the mpp tables,
specially if the frame is encrypted.
Reported-by: Chaoxing Lin <Chaoxing.Lin@ultra-3eti.com>
Signed-off-by: Javier Cardona <javier@cozybit.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
[bwh: Backported to 3.2: we have a large block conditional on
IEEE80211_RX_RA_MATCH rather than a goto conditional on the opposite,
so delete the condition]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7840487cd6 upstream.
The i2c core driver will turn the platform device ID to busnum
When using platfrom device ID as -1, it means dynamically assigned
the busnum. When writing code, we need to make sure the busnum,
and call i2c_register_board_info(int busnum, ...) to register device
if using -1, we do not know the value of busnum
In order to solve this issue, set the platform device ID as a fix number
Here using 0 to match the busnum used in i2c_regsiter_board_info()
Signed-off-by: Bo Shen <voice.shen@atmel.com>
Acked-by: Jean Delvare <khali@linux-fr.org>
Signed-off-by: Nicolas Ferre <nicolas.ferre@atmel.com>
Acked-by: Jean-Christophe PLAGNIOL-VILLARD <plagnioj@jcrosoft.com>
Acked-by: Ludovic Desroches <ludovic.desroches@atmel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3d9a0183dd upstream.
Newer at91sam9g10 SoC revision can't be detected, so the kernel can't boot with
this kind of kernel panic:
"AT91: Impossible to detect the SOC type"
CPU: ARM926EJ-S [41069265] revision 5 (ARMv5TEJ), cr=00053177
CPU: VIVT data cache, VIVT instruction cache
Machine: Atmel AT91SAM9G10-EK
Ignoring tag cmdline (using the default kernel command line)
bootconsole [earlycon0] enabled
Memory policy: ECC disabled, Data cache writeback
Kernel panic - not syncing: AT91: Impossible to detect the SOC type
[<c00133d4>] (unwind_backtrace+0x0/0xe0) from [<c02366dc>] (panic+0x78/0x1cc)
[<c02366dc>] (panic+0x78/0x1cc) from [<c02fa35c>] (at91_map_io+0x90/0xc8)
[<c02fa35c>] (at91_map_io+0x90/0xc8) from [<c02f9860>] (paging_init+0x564/0x6d0)
[<c02f9860>] (paging_init+0x564/0x6d0) from [<c02f7914>] (setup_arch+0x464/0x704)
[<c02f7914>] (setup_arch+0x464/0x704) from [<c02f44f8>] (start_kernel+0x6c/0x2d4)
[<c02f44f8>] (start_kernel+0x6c/0x2d4) from [<20008040>] (0x20008040)
The reason for this is that the Debug Unit Chip ID Register has changed between
Engineering Sample and definitive revision of the SoC. Changing the check of
cidr to socid will address the problem. We do not integrate this check to the
list just above because we also have to make sure that the extended id is
disregarded.
Signed-off-by: Ivan Shugov <ivan.shugov@gmail.com>
[nicolas.ferre@atmel.com: change commit message]
Signed-off-by: Nicolas Ferre <nicolas.ferre@atmel.com>
Acked-by: Jean-Christophe PLAGNIOL-VILLARD <plagnioj@jcrosoft.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9efade1b3e upstream.
cryptd_queue_worker attempts to prevent simultaneous accesses to crypto
workqueue by cryptd_enqueue_request using preempt_disable/preempt_enable.
However cryptd_enqueue_request might be called from softirq context,
so add local_bh_disable/local_bh_enable to prevent data corruption and
panics.
Bug report at http://marc.info/?l=linux-crypto-vger&m=134858649616319&w=2
v2:
- Disable software interrupts instead of hardware interrupts
Reported-by: Gurucharan Shetty <gurucharan.shetty@gmail.com>
Signed-off-by: Jussi Kivilinna <jussi.kivilinna@mbnet.fi>
Signed-off-by: Herbert Xu <herbert@gondor.apana.org.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b6e0e543f7 upstream.
Like in the case of native hdmi, which is fixed already in
commit adf00b26d1
Author: Paulo Zanoni <paulo.r.zanoni@intel.com>
Date: Tue Sep 25 13:23:34 2012 -0300
drm/i915: make sure we write all the DIP data bytes
we need to clear the entire sdvo buffer to avoid upsetting the
display.
Since infoframe buffer writing is now a bit more elaborate, extract it
into it's own function. This will be useful if we ever get around to
properly update the ELD for sdvo. Also #define proper names for the
two buffer indexes with fixed usage.
v2: Cite the right commit above, spotted by Paulo Zanoni.
v3: I'm too stupid to paste the right commit.
v4: Ben Hutchings noticed that I've failed to handle an underflow in
my loop logic, breaking it for i >= length + 8. Since I've just lost C
programmer license, use his solution. Also, make the frustrated 0-base
buffer size a notch more clear.
Reported-and-tested-by: Jürg Billeter <j@bitron.ch>
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Cc: Paulo Zanoni <przanoni@gmail.com>
Cc: Ben Hutchings <ben@decadent.org.uk>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@gmail.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 81014b9d0b upstream.
At least the worst offenders:
- SDVO specifies that the encoder should compute the ecc. Testing also
shows that we must not send the ecc field, so copy the dip_infoframe
struct to a temporay place and avoid the ecc field. This way the avi
infoframe is exactly 17 bytes long, which agrees with what the spec
mandates as a minimal storage capacity (with the ecc field it would
be 18 bytes).
- Only 17 when sending the avi infoframe. The SDVO spec explicitly
says that sending more data than what the device announces results
in undefined behaviour.
- Add __attribute__((packed)) to the avi and spd infoframes, for
otherwise they're wrongly aligned. Noticed because the avi infoframe
ended up being 18 bytes large instead of 17. We haven't noticed this
yet because we don't use the uint16_t fields yet (which are the only
ones that would be wrongly aligned).
This regression has been introduce by
3c17fe4b8f is the first bad commit
commit 3c17fe4b8f
Author: David Härdeman <david@hardeman.nu>
Date: Fri Sep 24 21:44:32 2010 +0200
i915: enable AVI infoframe for intel_hdmi.c [v4]
Patch tested on my g33 with a sdvo hdmi adaptor.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Tested-by: Peter Ross <pross@xvid.org> (G35 SDVO-HDMI)
Reviewed-by: Eugeni Dodonov <eugeni.dodonov@intel.com>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a9193983f4 upstream.
The overlay on the i830M has a peculiar failure mode: It works the
first time around after boot-up, but consistenly hangs the second time
it's used.
Chris Wilson has dug out a nice errata:
"1.5.12 Clock Gating Disable for Display Register
Address Offset: 06200h–06203h
"Bit 3
Ovrunit Clock Gating Disable.
0 = Clock gating controlled by unit enabling logic
1 = Disable clock gating function
DevALM Errata ALM049: Overlay Clock Gating Must be Disabled: Overlay
& L2 Cache clock gating must be disabled in order to prevent device
hangs when turning off overlay.SW must turn off Ovrunit clock gating
(6200h) and L2 Cache clock gating (C8h)."
Now I've nowhere found that 0xc8 register and hence couldn't apply the
l2 cache workaround. But I've remembered that part of the magic that
the OVERLAY_ON/OFF commands are supposed to do is to rearrange cache
allocations so that the overlay scaler has some scratch space.
And while pondering how that could explain the hang the 2nd time we
enable the overlay, I've remembered that the old ums overlay code did
_not_ issue the OVERLAY_OFF cmd.
And indeed, disabling the OFF cmd results in the overlay working
flawlessly, so I guess we can workaround the lack of the above
workaround by simply never disabling the overlay engine once it's
enabled.
Note that we have the first part of the above w/a already implemented
in i830_init_clock_gating - leave that as-is to avoid surprises.
v2: Add a comment in the code.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47827
Tested-by: Rhys <rhyspuk@gmail.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- s/intel_ring_emit(ring, /OUT_RING(/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c4a9fafc77 upstream.
No driver initializes chan->max_antenna_gain to something sensible, and
the only place where it is being used right now is inside ath9k. This
leads to ath9k potentially using less tx power than it can use, which can
decrease performance/range in some rare cases.
Rather than going through every single driver, this patch initializes
chan->orig_mag in wiphy_register(), ignoring whatever value the driver
left in there. If a driver for some reason wishes to limit it independent
from regulatory rulesets, it can do so internally.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 115c9b8192 upstream.
Implement a new netlink attribute type IFLA_EXT_MASK. The mask
is a 32 bit value that can be used to indicate to the kernel that
certain extended ifinfo values are requested by the user application.
At this time the only mask value defined is RTEXT_FILTER_VF to
indicate that the user wants the ifinfo dump to send information
about the VFs belonging to the interface.
This patch fixes a bug in which certain applications do not have
large enough buffers to accommodate the extra information returned
by the kernel with large numbers of SR-IOV virtual functions.
Those applications will not send the new netlink attribute with
the interface info dump request netlink messages so they will
not get unexpectedly large request buffers returned by the kernel.
Modifies the rtnl_calcit function to traverse the list of net
devices and compute the minimum buffer size that can hold the
info dumps of all matching devices based upon the filter passed
in via the new netlink attribute filter mask. If no filter
mask is sent then the buffer allocation defaults to NLMSG_GOODSIZE.
With this change it is possible to add yet to be defined netlink
attributes to the dump request which should make it fairly extensible
in the future.
Signed-off-by: Greg Rose <gregory.v.rose@intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
[bwh: Backported to 3.2: drop the change in do_setlink() that reverts
commit f18da14565, which we never applied]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Fix warning about unused variable introduced by commit e681b66f2e
("USB: mos7840: remove invalid disconnect handling") upstream.
A subsequent fix which removed the disconnect function got rid of the
warning but that one was only backported to v3.6.
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0914f7961b upstream.
When disconnect callback is called, each component should wake up
sleepers and check card->shutdown flag for avoiding the endless sleep
blocking the proper resource release.
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a0830dbd4e upstream.
For more strict protection for wild disconnections, a refcount is
introduced to the card instance, and let it up/down when an object is
referred via snd_lookup_*() in the open ops.
The free-after-last-close check is also changed to check this refcount
instead of the empty list, too.
Reported-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 888ea7d5ac upstream.
Similar like the previous commit, cover with chip->shutdown_rwsem
and chip->shutdown checks.
Reported-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 34f3c89fda upstream.
Replace mutex with rwsem for codec->shutdown protection so that
concurrent accesses are allowed.
Also add the protection to snd_usb_autosuspend() and
snd_usb_autoresume(), too.
Reported-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 978520b75f upstream.
Close some races at disconnection of a USB audio device by adding the
chip->shutdown_mutex and chip->shutdown check at appropriate places.
The spots to put bandaids are:
- PCM prepare, hw_params and hw_free
- where the usb device is accessed for communication or get speed, in
mixer.c and others; the device speed is now cached in subs->speed
instead of accessing to chip->dev
The accesses in PCM open and close don't need the mutex protection
because these are already handled in the core PCM disconnection code.
The autosuspend/autoresume codes are still uncovered by this patch
because of possible mutex deadlocks. They'll be covered by the
upcoming change to rwsem.
Also the mixer codes are untouched, too. These will be fixed in
another patch, too.
Reported-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9b0573c07f upstream.
Fix races at PCM disconnection:
- while a PCM device is being opened or closed
- while the PCM state is being changed without lock in prepare,
hw_params, hw_free ops
Reported-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a007c4c3e9 upstream.
I don't think there's a practical difference for the range of values
these interfaces should see, but it would be safer to be unambiguous.
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e412e95a26 upstream.
This is to prevent nouveau from taking over the console on headless boards
such as Tesla.
Signed-off-by: Ben Skeggs <bskeggs@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9430738d80 upstream.
Signed-off-by: Ben Skeggs <bskeggs@redhat.com>
[jrnieder@gmail.com: backport to 3.2: make fbcon suspend/resume
handling conditional in a vague hope that this will approximate what
the original does for 3.3+]
Signed-off-by: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f6365201d8 upstream.
The X86_32-only disable_hlt/enable_hlt mechanism was used by the
32-bit floppy driver. Its effect was to replace the use of the
HLT instruction inside default_idle() with cpu_relax() - essentially
it turned off the use of HLT.
This workaround was commented in the code as:
"disable hlt during certain critical i/o operations"
"This halt magic was a workaround for ancient floppy DMA
wreckage. It should be safe to remove."
H. Peter Anvin additionally adds:
"To the best of my knowledge, no-hlt only existed because of
flaky power distributions on 386/486 systems which were sold to
run DOS. Since DOS did no power management of any kind,
including HLT, the power draw was fairly uniform; when exposed
to the much hhigher noise levels you got when Linux used HLT
caused some of these systems to fail.
They were by far in the minority even back then."
Alan Cox further says:
"Also for the Cyrix 5510 which tended to go castors up if a HLT
occurred during a DMA cycle and on a few other boxes HLT during
DMA tended to go astray.
Do we care ? I doubt it. The 5510 was pretty obscure, the 5520
fixed it, the 5530 is probably the oldest still in any kind of
use."
So, let's finally drop this.
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Josh Boyer <jwboyer@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Acked-by: "H. Peter Anvin" <hpa@zytor.com>
Acked-by: Alan Cox <alan@lxorguk.ukuu.org.uk>
Cc: Stephen Hemminger <shemminger@vyatta.com
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Link: http://lkml.kernel.org/n/tip-3rhk9bzf0x9rljkv488tloib@git.kernel.org
[ If anyone cares then alternative instruction patching could be
used to replace HLT with a one-byte NOP instruction. Much simpler. ]
Signed-off-by: Ingo Molnar <mingo@kernel.org>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Commit ff03261adc ('Bluetooth: Fix
sending a HCI Authorization Request over LE links', commit
d8343f1257 upstream) added an
call to smp_conn_security() from hci_conn_security(). The
former is only defined if CONFIG_BT_L2CAP=y.
This is not required in mainline since commit
f1e91e1640 ('Bluetooth: Always compile
SCO and L2CAP in Bluetooth Core') removed that option.
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit abce9ac292 upstream.
tpm_write calls tpm_transmit without checking the return value and
assigns the return value unconditionally to chip->pending_data, even if
it's an error value.
This causes three bugs.
So if we write to /dev/tpm0 with a tpm_param_size bigger than
TPM_BUFSIZE=0x1000 (e.g. 0x100a)
and a bufsize also bigger than TPM_BUFSIZE (e.g. 0x100a)
tpm_transmit returns -E2BIG which is assigned to chip->pending_data as
-7, but tpm_write returns that TPM_BUFSIZE bytes have been successfully
been written to the TPM, altough this is not true (bug #1).
As we did write more than than TPM_BUFSIZE bytes but tpm_write reports
that only TPM_BUFSIZE bytes have been written the vfs tries to write
the remaining bytes (in this case 10 bytes) to the tpm device driver via
tpm_write which then blocks at
/* cannot perform a write until the read has cleared
either via tpm_read or a user_read_timer timeout */
while (atomic_read(&chip->data_pending) != 0)
msleep(TPM_TIMEOUT);
for 60 seconds, since data_pending is -7 and nobody is able to
read it (since tpm_read luckily checks if data_pending is greater than
0) (#bug 2).
After that the remaining bytes are written to the TPM which are
interpreted by the tpm as a normal command. (bug #3)
So if the last bytes of the command stream happen to be a e.g.
tpm_force_clear this gets accidentally sent to the TPM.
This patch fixes all three bugs, by propagating the error code of
tpm_write and returning -E2BIG if the input buffer is too big,
since the response from the tpm for a truncated value is bogus anyway.
Moreover it returns -EBUSY to userspace if there is a response ready to be
read.
Signed-off-by: Peter Huewe <peter.huewe@infineon.com>
Signed-off-by: Kent Yoder <key@linux.vnet.ibm.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5b423f6a40 upstream.
Existing code assumes that del_timer returns true for alive conntrack
entries. However, this is not true if reliable events are enabled.
In that case, del_timer may return true for entries that were
just inserted in the dying list. Note that packets / ctnetlink may
hold references to conntrack entries that were just inserted to such
list.
This patch fixes the issue by adding an independent timer for
event delivery. This increases the size of the ecache extension.
Still we can revisit this later and use variable size extensions
to allocate this area on demand.
Tested-by: Oliver Smith <olipro@8.c.9.b.0.7.4.0.1.0.0.2.ip6.arpa>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Acked-by: David Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
This reverts 5ff39e971c which was commit
303a7ce920 upstream.
It is not necessary for kernel versions without per-netns RPC clients.
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 20f1de659b upstream.
Fix possible overflow of the buffer used for expanding environment
variables when building file list.
In the extremely unlikely case of an attacker having control over the
environment variables visible to gen_init_cpio, control over the
contents of the file gen_init_cpio parses, and gen_init_cpio was built
without compiler hardening, the attacker can gain arbitrary execution
control via a stack buffer overflow.
$ cat usr/crash.list
file foo ${BIG}${BIG}${BIG}${BIG}${BIG}${BIG} 0755 0 0
$ BIG=$(perl -e 'print "A" x 4096;') ./usr/gen_init_cpio usr/crash.list
*** buffer overflow detected ***: ./usr/gen_init_cpio terminated
This also replaces the space-indenting with tabs.
Patch based on existing fix extracted from grsecurity.
Signed-off-by: Kees Cook <keescook@chromium.org>
Cc: Michal Marek <mmarek@suse.cz>
Cc: Brad Spengler <spender@grsecurity.net>
Cc: PaX Team <pageexec@freemail.hu>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit eedce141cd upstream.
The genalloc code uses the bitmap API from include/linux/bitmap.h and
lib/bitmap.c, which is based on long values. Both bitmap_set from
lib/bitmap.c and bitmap_set_ll, which is the lockless version from
genalloc.c, use BITMAP_LAST_WORD_MASK to set the first bits in a long in
the bitmap.
That one uses (1 << bits) - 1, 0b111, if you are setting the first three
bits. This means that the API counts from the least significant bits
(LSB from now on) to the MSB. The LSB in the first long is bit 0, then.
The same works for the lookup functions.
The genalloc code uses longs for the bitmap, as it should. In
include/linux/genalloc.h, struct gen_pool_chunk has unsigned long
bits[0] as its last member. When allocating the struct, genalloc should
reserve enough space for the bitmap. This should be a proper number of
longs that can fit the amount of bits in the bitmap.
However, genalloc allocates an integer number of bytes that fit the
amount of bits, but may not be an integer amount of longs. 9 bytes, for
example, could be allocated for 70 bits.
This is a problem in itself if the Least Significat Bit in a long is in
the byte with the largest address, which happens in Big Endian machines.
This means genalloc is not allocating the byte in which it will try to
set or check for a bit.
This may end up in memory corruption, where genalloc will try to set the
bits it has not allocated. In fact, genalloc may not set these bits
because it may find them already set, because they were not zeroed since
they were not allocated. And that's what causes a BUG when
gen_pool_destroy is called and check for any set bits.
What really happens is that genalloc uses kmalloc_node with __GFP_ZERO
on gen_pool_add_virt. With SLAB and SLUB, this means the whole slab
will be cleared, not only the requested bytes. Since struct
gen_pool_chunk has a size that is a multiple of 8, and slab sizes are
multiples of 8, we get lucky and allocate and clear the right amount of
bytes.
Hower, this is not the case with SLOB or with older code that did memset
after allocating instead of using __GFP_ZERO.
So, a simple module as this (running 3.6.0), will cause a crash when
rmmod'ed.
[root@phantom-lp2 foo]# cat foo.c
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/genalloc.h>
MODULE_LICENSE("GPL");
MODULE_VERSION("0.1");
static struct gen_pool *foo_pool;
static __init int foo_init(void)
{
int ret;
foo_pool = gen_pool_create(10, -1);
if (!foo_pool)
return -ENOMEM;
ret = gen_pool_add(foo_pool, 0xa0000000, 32 << 10, -1);
if (ret) {
gen_pool_destroy(foo_pool);
return ret;
}
return 0;
}
static __exit void foo_exit(void)
{
gen_pool_destroy(foo_pool);
}
module_init(foo_init);
module_exit(foo_exit);
[root@phantom-lp2 foo]# zcat /proc/config.gz | grep SLOB
CONFIG_SLOB=y
[root@phantom-lp2 foo]# insmod ./foo.ko
[root@phantom-lp2 foo]# rmmod foo
------------[ cut here ]------------
kernel BUG at lib/genalloc.c:243!
cpu 0x4: Vector: 700 (Program Check) at [c0000000bb0e7960]
pc: c0000000003cb50c: .gen_pool_destroy+0xac/0x110
lr: c0000000003cb4fc: .gen_pool_destroy+0x9c/0x110
sp: c0000000bb0e7be0
msr: 8000000000029032
current = 0xc0000000bb0e0000
paca = 0xc000000006d30e00 softe: 0 irq_happened: 0x01
pid = 13044, comm = rmmod
kernel BUG at lib/genalloc.c:243!
[c0000000bb0e7ca0] d000000004b00020 .foo_exit+0x20/0x38 [foo]
[c0000000bb0e7d20] c0000000000dff98 .SyS_delete_module+0x1a8/0x290
[c0000000bb0e7e30] c0000000000097d4 syscall_exit+0x0/0x94
--- Exception: c00 (System Call) at 000000800753d1a0
SP (fffd0b0e640) is in userspace
Signed-off-by: Thadeu Lima de Souza Cascardo <cascardo@linux.vnet.ibm.com>
Cc: Paul Gortmaker <paul.gortmaker@windriver.com>
Cc: Benjamin Gaignard <benjamin.gaignard@stericsson.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ef5d437f71 upstream.
On s390 any write to a page (even from kernel itself) sets architecture
specific page dirty bit. Thus when a page is written to via buffered
write, HW dirty bit gets set and when we later map and unmap the page,
page_remove_rmap() finds the dirty bit and calls set_page_dirty().
Dirtying of a page which shouldn't be dirty can cause all sorts of
problems to filesystems. The bug we observed in practice is that
buffers from the page get freed, so when the page gets later marked as
dirty and writeback writes it, XFS crashes due to an assertion
BUG_ON(!PagePrivate(page)) in page_buffers() called from
xfs_count_page_state().
Similar problem can also happen when zero_user_segment() call from
xfs_vm_writepage() (or block_write_full_page() for that matter) set the
hardware dirty bit during writeback, later buffers get freed, and then
page unmapped.
Fix the issue by ignoring s390 HW dirty bit for page cache pages of
mappings with mapping_cap_account_dirty(). This is safe because for
such mappings when a page gets marked as writeable in PTE it is also
marked dirty in do_wp_page() or do_page_fault(). When the dirty bit is
cleared by clear_page_dirty_for_io(), the page gets writeprotected in
page_mkclean(). So pagecache page is writeable if and only if it is
dirty.
Thanks to Hugh Dickins for pointing out mapping has to have
mapping_cap_account_dirty() for things to work and proposing a cleaned
up variant of the patch.
The patch has survived about two hours of running fsx-linux on tmpfs
while heavily swapping and several days of running on out build machines
where the original problem was triggered.
Signed-off-by: Jan Kara <jack@suse.cz>
Cc: Martin Schwidefsky <schwidefsky@de.ibm.com>
Cc: Mel Gorman <mgorman@suse.de>
Cc: Hugh Dickins <hughd@google.com>
Cc: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: adjust context; in particular there is no local
'anon' in page_remove_rmap()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b40a79591c upstream.
flush_old_exec() clears PF_KTHREAD but forgets about PF_NOFREEZE.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Acked-by: Tejun Heo <tj@kernel.org>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
[bwh: Backported to 3.2: PF_FORKNOEXEC is cleared elsewhere]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 43a09f7fb0 upstream.
The command cancellation code doesn't check whether find_trb_seg()
couldn't find the segment that contains the TRB to be canceled. This
could cause a NULL pointer deference later in the function when next_trb
is called. It's unlikely to happen unless something is wrong with the
command ring pointers, so add some debugging in case it happens.
This patch should be backported to stable kernels as old as 3.0, that
contain the commit b63f4053cc "xHCI:
handle command after aborting the command ring".
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c323dc023b upstream.
BIOS vendors keep changing the BIOS versions. Only match the beginning
of the string to match all Lucid tablets with board name M11JB.
Signed-off-by: Anisse Astier <anisse@astier.eu>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e681b66f2e upstream.
Remove private zombie flag used to signal disconnect and to prevent
control urb from being submitted from interrupt urb completion handler.
The control urb will not be re-submitted as both the control urb and the
interrupt urb is killed on disconnect.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 28c3ae9a8c upstream.
The private int_urb is never allocated so the submission from the
control completion handler will always fail. Remove this odd piece of
broken code.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3eb55cc4ed upstream.
The driver set the usb-serial port pointers to NULL on errors in attach,
effectively preventing usb-serial core from decrementing the port ref
counters and releasing the port devices and associated data.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 084817d793 upstream.
Move interface data allocation to attach so that it is deallocated on
errors in usb-serial probe.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5260e458f5 upstream.
Make sure generic close is called at close.
The driver relies on the generic write implementation but did not call
generic close.
Note that the call to kill the read urb is not redundant, as mct_u232
uses an interrupt urb from the second port as the read urb and that
generic close therefore fails to kill it.
Compile-only tested.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ea0dbebffe upstream.
Make sure to allocate the control-message buffer dynamically as some
platforms cannot do DMA from stack.
Note that only the first byte of the old buffer was used.
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 910a578f7e upstream.
We copy head count to a 16 bit field, this works by chance on LE but on
BE guest gets 0. Fix it up.
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Tested-by: Alexander Graf <agraf@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 66081a7251 upstream.
The warning check for duplicate sysfs entries can cause a buffer overflow
when printing the warning, as strcat() doesn't check buffer sizes.
Use strlcat() instead.
Since strlcat() doesn't return a pointer to the passed buffer, unlike
strcat(), I had to convert the nested concatenation in sysfs_add_one() to
an admittedly more obscure comma operator construct, to avoid emitting code
for the concatenation if CONFIG_BUG is disabled.
Signed-off-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f878b657ce upstream.
Chris Perl reports that we're seeing races between the wakeup call in
xs_error_report and the connect attempts. Basically, Chris has shown
that in certain circumstances, the call to xs_error_report causes the
rpc_task that is responsible for reconnecting to wake up early, thus
triggering a disconnect and retry.
Since the sk->sk_error_report() calls in the socket layer are always
followed by a tcp_done() in the cases where we care about waking up
the rpc_tasks, just let the state_change callbacks take responsibility
for those wake ups.
Reported-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Tested-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4bc1e68ed6 upstream.
The call to xprt_disconnect_done() that is triggered by a successful
connection reset will trigger another automatic wakeup of all tasks
on the xprt->pending rpc_wait_queue. In particular it will cause an
early wake up of the task that called xprt_connect().
All we really want to do here is clear all the socket-specific state
flags, so we split that functionality out of xs_sock_mark_closed()
into a helper that can be called by xs_abort_connection()
Reported-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Tested-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b9d2bb2ee5 upstream.
This reverts commit 55420c24a0.
Now that we clear the connected flag when entering TCP_CLOSE_WAIT,
the deadlock described in this commit is no longer possible.
Instead, the resulting call to xs_tcp_shutdown() can interfere
with pending reconnection attempts.
Reported-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Tested-by: Chris Perl <chris.perl@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 168bfeef7b upstream.
If none of the elements in scrubrates[] matches, this loop will cause
__amd64_set_scrub_rate() to incorrectly use the n+1th element.
As the function is designed to use the final scrubrates[] element in the
case of no match, we can fix this bug by simply terminating the array
search at the n-1th element.
Boris: this code is fragile anyway, see here why:
http://marc.info/?l=linux-kernel&m=135102834131236&w=2
It will be rewritten more robustly soonish.
Reported-by: Denis Kirjanov <kirjanov@gmail.com>
Cc: Doug Thompson <dougthompson@xmission.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Borislav Petkov <borislav.petkov@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 627072b06c upstream.
The tile tool chain uses the .eh_frame information for backtracing.
The vmlinux build drops any .eh_frame sections at link time, but when
present in kernel modules, it causes a module load failure due to the
presence of unsupported pc-relative relocations. When compiling to
use compiler feedback support, the compiler by default omits .eh_frame
information, so we don't see this problem. But when not using feedback,
we need to explicitly suppress the .eh_frame.
Signed-off-by: Chris Metcalf <cmetcalf@tilera.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5f40b90972 upstream.
When booting a secondary CPU, the primary CPU hands two sets of page
tables via the secondary_data struct:
(1) swapper_pg_dir: a normal, cacheable, shared (if SMP) mapping
of the kernel image (i.e. the tables used by init_mm).
(2) idmap_pgd: an uncached mapping of the .idmap.text ELF
section.
The idmap is generally used when enabling and disabling the MMU, which
includes early CPU boot. In this case, the secondary CPU switches to
swapper as soon as it enters C code:
struct mm_struct *mm = &init_mm;
unsigned int cpu = smp_processor_id();
/*
* All kernel threads share the same mm context; grab a
* reference and switch to it.
*/
atomic_inc(&mm->mm_count);
current->active_mm = mm;
cpumask_set_cpu(cpu, mm_cpumask(mm));
cpu_switch_mm(mm->pgd, mm);
This causes a problem on ARMv7, where the identity mapping is treated as
strongly-ordered leading to architecturally UNPREDICTABLE behaviour of
exclusive accesses, such as those used by atomic_inc.
This patch re-orders the secondary_start_kernel function so that we
switch to swapper before performing any exclusive accesses.
Cc: David McKay <david.mckay@st.com>
Reported-by: Gilles Chanteperdrix <gilles.chanteperdrix@xenomai.org>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 84f98fdf78 upstream.
I have a Lenovo ThinkPad T430 and an UltraBase Series 3 docking
station.
Without this patch, if I plug my headphones into the jack on the
computer, everything works fine. The computer speakers mute and the
audio is played in the headphones. However, if I plug into the docking
station headphone jack the computer speakers are muted but there is no
audio in the headphones.
Addresses https://bugs.launchpad.net/bugs/1060372
Signed-off-by: Joseph Salisbury <joseph.salisbury@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a349e23d1c upstream.
In 32 bit guests, if a userspace process has %eax == -ERESTARTSYS
(-512) or -ERESTARTNOINTR (-513) when it is interrupted by an event
/and/ the process has a pending signal then %eip (and %eax) are
corrupted when returning to the main process after handling the
signal. The application may then crash with SIGSEGV or a SIGILL or it
may have subtly incorrect behaviour (depending on what instruction it
returned to).
The occurs because handle_signal() is incorrectly thinking that there
is a system call that needs to restarted so it adjusts %eip and %eax
to re-execute the system call instruction (even though user space had
not done a system call).
If %eax == -514 (-ERESTARTNOHAND (-514) or -ERESTART_RESTARTBLOCK
(-516) then handle_signal() only corrupted %eax (by setting it to
-EINTR). This may cause the application to crash or have incorrect
behaviour.
handle_signal() assumes that regs->orig_ax >= 0 means a system call so
any kernel entry point that is not for a system call must push a
negative value for orig_ax. For example, for physical interrupts on
bare metal the inverse of the vector is pushed and page_fault() sets
regs->orig_ax to -1, overwriting the hardware provided error code.
xen_hypervisor_callback() was incorrectly pushing 0 for orig_ax
instead of -1.
Classic Xen kernels pushed %eax which works as %eax cannot be both
non-negative and -RESTARTSYS (etc.), but using -1 is consistent with
other non-system call entry points and avoids some of the tests in
handle_signal().
There were similar bugs in xen_failsafe_callback() of both 32 and
64-bit guests. If the fault was corrected and the normal return path
was used then 0 was incorrectly pushed as the value for orig_ax.
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Acked-by: Jan Beulich <JBeulich@suse.com>
Acked-by: Ian Campbell <ian.campbell@citrix.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c985cb37f1 upstream.
Because of a change in the s390 arch backend of binutils (commit 23ecd77
"Pick the default arch depending on the target size" in binutils repo)
31 bit builds will fail since the linker would now try to create 64 bit
binary output.
Fix this by setting OUTPUT_ARCH to s390:31-bit instead of s390.
Thanks to Andreas Krebbel for figuring out the issue.
Fixes this build error:
LD init/built-in.o
s390x-4.7.2-ld: s390:31-bit architecture of input file
`arch/s390/kernel/head.o' is incompatible with s390:64-bit output
Cc: Andreas Krebbel <Andreas.Krebbel@de.ibm.com>
Signed-off-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 470809741a upstream.
This minor change adds a new system to which the "Fix Compliance Mode
on SN65LVPE502CP Hardware" patch has to be applied also.
System added:
Vendor: Hewlett-Packard. System Model: Z1
Signed-off-by: Alexis R. Cortes <alexis.cortes@ti.com>
Acked-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cd0b16c1c3 upstream.
If the filehandle is stale, or open access is denied for some reason,
nlm_fopen() may return one of the NLMv4-specific error codes nlm4_stale_fh
or nlm4_failed. These get passed right through nlm_lookup_file(),
and so when nlmsvc_retrieve_args() calls the latter, it needs to filter
the result through the cast_status() machinery.
Failure to do so, will trigger the BUG_ON() in encode_nlm_stat...
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Reported-by: Larry McVoy <lm@bitmover.com>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 71aa5ebe36 upstream.
Even when CONFIG_SND_DEBUG is not enabled, we don't want to
return an arbitrary memory location when the channel count is
larger than we expected.
Signed-off-by: David Henningsson <david.henningsson@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1f5320d597 upstream.
notify_on_release must be triggered when the last process in a cgroup is
move to another. But if the first(and only) process in a cgroup is moved to
another, notify_on_release is not triggered.
# mkdir /cgroup/cpu/SRC
# mkdir /cgroup/cpu/DST
#
# echo 1 >/cgroup/cpu/SRC/notify_on_release
# echo 1 >/cgroup/cpu/DST/notify_on_release
#
# sleep 300 &
[1] 8629
#
# echo 8629 >/cgroup/cpu/SRC/tasks
# echo 8629 >/cgroup/cpu/DST/tasks
-> notify_on_release for /SRC must be triggered at this point,
but it isn't.
This is because put_css_set() is called before setting CGRP_RELEASABLE
in cgroup_task_migrate(), and is a regression introduce by the
commit:74a1166d(cgroups: make procs file writable), which was merged
into v3.0.
Cc: Ben Blum <bblum@andrew.cmu.edu>
Acked-by: Li Zefan <lizefan@huawei.com>
Signed-off-by: Daisuke Nishimura <nishimura@mxp.nes.nec.co.jp>
Signed-off-by: Tejun Heo <tj@kernel.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8f7b8db6e0 upstream.
The channel switch command for 6000 series devices
is larger than the maximum inline command size of
320 bytes. The command is therefore refused with a
warning. Fix this by allocating the command and
using the NOCOPY mechanism.
Reviewed-by: Emmanuel Grumbach <emmanuel.grumbach@intel.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bf11315eed upstream.
The driver does not count space of radiotap fields when allocating skb for
radiotap packet. This leads to kernel panic with the following call trace:
...
[67607.676067] [<c152f90f>] error_code+0x67/0x6c
[67607.676067] [<c142f831>] ? skb_put+0x91/0xa0
[67607.676067] [<f8cf5e5b>] ? ipw_handle_promiscuous_tx+0x16b/0x2d0 [ipw2200]
[67607.676067] [<f8cf5e5b>] ipw_handle_promiscuous_tx+0x16b/0x2d0 [ipw2200]
[67607.676067] [<f8cf899b>] ipw_net_hard_start_xmit+0x8b/0x90 [ipw2200]
[67607.676067] [<f8741c5a>] libipw_xmit+0x55a/0x980 [libipw]
[67607.676067] [<c143d3e8>] dev_hard_start_xmit+0x218/0x4d0
...
This bug was found by VittGam.
https://bugzilla.kernel.org/show_bug.cgi?id=43255
Signed-off-by: Stanislav Yakovlev <stas.yakovlev@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4045f72bcf upstream.
This patch fix corruption which can manifest itself by following crash
when switching on rfkill switch with rt2x00 driver:
https://bugzilla.redhat.com/attachment.cgi?id=615362
Pointer key->u.ccmp.tfm of group key get corrupted in:
ieee80211_rx_h_michael_mic_verify():
/* update IV in key information to be able to detect replays */
rx->key->u.tkip.rx[rx->security_idx].iv32 = rx->tkip_iv32;
rx->key->u.tkip.rx[rx->security_idx].iv16 = rx->tkip_iv16;
because rt2x00 always set RX_FLAG_MMIC_STRIPPED, even if key is not TKIP.
We already check type of the key in different path in
ieee80211_rx_h_michael_mic_verify() function, so adding additional
check here is reasonable.
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0829184711 upstream.
radeon_i2c_fini() walks thru the list of I2C bus recs rdev->i2c_bus[]
to destroy each of them.
radeon_ext_tmds_enc_destroy() however also has code to destroy it's
associated I2C bus rec which has been obtained by radeon_i2c_lookup()
and is therefore also in the i2c_bus[] list.
This causes a double free resulting in a kernel panic when unloading
the radeon driver.
Removing destroy code from radeon_ext_tmds_enc_destroy() fixes this
problem.
agd5f: fix compiler warning
Signed-off-by: Egbert Eich <eich@suse.de>
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fdc858a466 upstream.
The sharpsl_pcmcia_ops structure gets passed into
sa11xx_drv_pcmcia_probe, where it gets accessed at run-time,
unlike all other pcmcia drivers that pass their structures
into platform_device_add_data, which makes a copy.
This means the gcc warning is valid and the structure
must not be marked as __initdata.
Without this patch, building collie_defconfig results in:
drivers/pcmcia/pxa2xx_sharpsl.c:22:31: fatal error: mach-pxa/hardware.h: No such file or directory
compilation terminated.
make[3]: *** [drivers/pcmcia/pxa2xx_sharpsl.o] Error 1
make[2]: *** [drivers/pcmcia] Error 2
make[1]: *** [drivers] Error 2
make: *** [sub-make] Error 2
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Cc: Dominik Brodowski <linux@dominikbrodowski.net>
Cc: Russell King <rmk+kernel@arm.linux.org.uk>
Cc: Pavel Machek <pavel@suse.cz>
Cc: linux-pcmcia@lists.infradead.org
Cc: Jochen Friedrich <jochen@scram.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1a7bbda5b1 upstream.
We actually do not do anything about it. Just return a default
value of zero and if the kernel tries to write anything but 0
we BUG_ON.
This fixes the case when an user tries to suspend the machine
and it blows up in save_processor_state b/c 'read_cr8' is set
to NULL and we get:
kernel BUG at /home/konrad/ssd/linux/arch/x86/include/asm/paravirt.h:100!
invalid opcode: 0000 [#1] SMP
Pid: 2687, comm: init.late Tainted: G O 3.6.0upstream-00002-gac264ac-dirty #4 Bochs Bochs
RIP: e030:[<ffffffff814d5f42>] [<ffffffff814d5f42>] save_processor_state+0x212/0x270
.. snip..
Call Trace:
[<ffffffff810733bf>] do_suspend_lowlevel+0xf/0xac
[<ffffffff8107330c>] ? x86_acpi_suspend_lowlevel+0x10c/0x150
[<ffffffff81342ee2>] acpi_suspend_enter+0x57/0xd5
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cd0608e71e upstream.
The hypervisor will trap it. However without this patch,
we would crash as the .read_tscp is set to NULL. This patch
fixes it and sets it to the native_read_tscp call.
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f0a996eeed upstream.
This fault was detected using the kgdb test suite on boot and it
crashes recursively due to the fact that CONFIG_KPROBES on mips adds
an extra die notifier in the page fault handler. The crash signature
looks like this:
kgdbts:RUN bad memory access test
KGDB: re-enter exception: ALL breakpoints killed
Call Trace:
[<807b7548>] dump_stack+0x20/0x54
[<807b7548>] dump_stack+0x20/0x54
The fix for now is to have kgdb return immediately if the fault type
is DIE_PAGE_FAULT and allow the kprobe code to decide what is supposed
to happen.
Cc: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Cc: David S. Miller <davem@davemloft.net>
Signed-off-by: Jason Wessel <jason.wessel@windriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 065a13e2cc upstream.
When sending a pairing request or response we should not just blindly
copy the value that the remote device sent. Instead we should at least
make sure to mask out any unknown bits. This is particularly critical
from the upcoming LE Secure Connections feature perspective as
incorrectly indicating support for it (by copying the remote value)
would cause a failure to pair with devices that support it.
Signed-off-by: Johan Hedberg <johan.hedberg@intel.com>
Acked-by: Marcel Holtmann <marcel@holtmann.org>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 91502f099d upstream.
Clang complains that we are assigning a variable to itself. This should
be using bad_sectors like the similar earlier check does.
Bug has been present since 3.1-rc1. It is minor but could
conceivably cause corruption or other bad behaviour.
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5aa8b57200 upstream.
For IPv6, sizeof(struct ipv6hdr) = 40, thus the following
expression will result negative:
datalen = pkt_dev->cur_pkt_size - 14 -
sizeof(struct ipv6hdr) - sizeof(struct udphdr) -
pkt_dev->pkt_overhead;
And, the check "if (datalen < sizeof(struct pktgen_hdr))" will be
passed as "datalen" is promoted to unsigned, therefore will cause
a crash later.
This is a quick fix by checking if "datalen" is negative. The following
patch will increase the default value of 'min_pkt_size' for IPv6.
This bug should exist for a long time, so Cc -stable too.
Cc: David S. Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f7f4b2322b upstream.
This caused the internal speaker to mute itself because it was
present, which happened after powersave.
It was found on Dell XPS 15 (L502x), ALC665.
Reported-by: Da Fox <da.fox.mail@gmail.com>
Signed-off-by: David Henningsson <david.henningsson@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7386cdbf2f upstream.
Git commit 09a1d34f85 "nohz: Make idle/iowait counter update
conditional" introduced a bug in regard to cpu hotplug. The effect is
that the number of idle ticks in the cpu summary line in /proc/stat is
still counting ticks for offline cpus.
Reproduction is easy, just start a workload that keeps all cpus busy,
switch off one or more cpus and then watch the idle field in top.
On a dual-core with one cpu 100% busy and one offline cpu you will get
something like this:
%Cpu(s): 48.7 us, 1.3 sy, 0.0 ni, 50.0 id, 0.0 wa, 0.0 hi, 0.0 si,
%0.0 st
The problem is that an offline cpu still has ts->idle_active == 1.
To fix this we should make sure that the cpu is online when calling
get_cpu_idle_time_us and get_cpu_iowait_time_us.
[Srivatsa: Rebased to current mainline]
Reported-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
Signed-off-by: Michal Hocko <mhocko@suse.cz>
Reviewed-by: Srivatsa S. Bhat <srivatsa.bhat@linux.vnet.ibm.com>
Signed-off-by: Srivatsa S. Bhat <srivatsa.bhat@linux.vnet.ibm.com>
Link: http://lkml.kernel.org/r/20121010061820.8999.57245.stgit@srivatsabhat.in.ibm.com
Cc: deepthi@linux.vnet.ibm.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c5e0b6dbad upstream.
The proper destructor should be called at the error path.
Signed-off-by: Takashi Iwai <tiwai@suse.de>
[bwh: Backported to 3.2: drop the change to nonexistent patch_cs4213()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dee1f973ca upstream.
We assumed that at the time we call ext4_convert_unwritten_extents_endio()
extent in question is fully inside [map.m_lblk, map->m_len] because
it was already split during submission. But this may not be true due to
a race between writeback vs fallocate.
If extent in question is larger than requested we will split it again.
Special precautions should being done if zeroout required because
[map.m_lblk, map->m_len] already contains valid data.
Signed-off-by: Dmitry Monakhov <dmonakhov@openvz.org>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 35c2a7f490 upstream.
Fuzzing with trinity oopsed on the 1st instruction of shmem_fh_to_dentry(),
u64 inum = fid->raw[2];
which is unhelpfully reported as at the end of shmem_alloc_inode():
BUG: unable to handle kernel paging request at ffff880061cd3000
IP: [<ffffffff812190d0>] shmem_alloc_inode+0x40/0x40
Oops: 0000 [#1] PREEMPT SMP DEBUG_PAGEALLOC
Call Trace:
[<ffffffff81488649>] ? exportfs_decode_fh+0x79/0x2d0
[<ffffffff812d77c3>] do_handle_open+0x163/0x2c0
[<ffffffff812d792c>] sys_open_by_handle_at+0xc/0x10
[<ffffffff83a5f3f8>] tracesys+0xe1/0xe6
Right, tmpfs is being stupid to access fid->raw[2] before validating that
fh_len includes it: the buffer kmalloc'ed by do_sys_name_to_handle() may
fall at the end of a page, and the next page not be present.
But some other filesystems (ceph, gfs2, isofs, reiserfs, xfs) are being
careless about fh_len too, in fh_to_dentry() and/or fh_to_parent(), and
could oops in the same way: add the missing fh_len checks to those.
Reported-by: Sasha Levin <levinsasha928@gmail.com>
Signed-off-by: Hugh Dickins <hughd@google.com>
Cc: Al Viro <viro@zeniv.linux.org.uk>
Cc: Sage Weil <sage@inktank.com>
Cc: Steven Whitehouse <swhiteho@redhat.com>
Cc: Christoph Hellwig <hch@infradead.org>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b8c4321f3d upstream.
Line 0 and 1 were both written to line 0 (on the display) and all subsequent
lines had an offset of -1. The result was that the last line on the display
was never overwritten by writes to /dev/fbN.
Signed-off-by: Alexander Holler <holler@ahsoftware.de>
Acked-by: Bernie Thompson <bernie@plugable.com>
Signed-off-by: Florian Tobias Schandinat <FlorianSchandinat@gmx.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 26cff4e2aa upstream.
Adding two (or more) timers with large values for "expires" (they have
to reside within tv5 in the same list) leads to endless looping
between cascade() and internal_add_timer() in case CONFIG_BASE_SMALL
is one and jiffies are crossing the value 1 << 18. The bug was
introduced between 2.6.11 and 2.6.12 (and survived for quite some
time).
This patch ensures that when cascade() is called timers within tv5 are
not added endlessly to their own list again, instead they are added to
the next lower tv level tv4 (as expected).
Signed-off-by: Christian Hildner <christian.hildner@siemens.com>
Reviewed-by: Jan Kiszka <jan.kiszka@siemens.com>
Link: http://lkml.kernel.org/r/98673C87CB31274881CFFE0B65ECC87B0F5FC1963E@DEFTHW99EA4MSX.ww902.siemens.net
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5c1b10ab7f upstream.
Properly account for I/O in transit before returning from the RESET call.
In the absense of this patch, we could have a situation where the host may
respond to a command that was issued prior to the issuance of the RESET
command at some arbitrary time after responding to the RESET command.
Currently, the host does not do anything with the RESET command.
Signed-off-by: K. Y. Srinivasan <kys@microsoft.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bc977749e9 upstream.
Currently it is possible to unmap one more block than user requested to
due to the off-by-one error in unmap_region(). This is probably due to
the fact that the end variable despite its name actually points to the
last block to unmap + 1. However in the condition it is handled as the
last block of the region to unmap.
The bug was not previously spotted probably due to the fact that the
region was not zeroed, which has changed with commit
be1dd78de5. With that commit we were able
to corrupt the ext4 file system on 256M scsi_debug device with LBPRZ
enabled using fstrim.
Since the 'end' semantic is the same in several functions there this
commit just fixes the condition to use the 'end' variable correctly in
that context.
Reported-by: Paolo Bonzini <pbonzini@redhat.com>
Signed-off-by: Lukas Czerner <lczerner@redhat.com>
Reviewed-by: Martin K. Petersen <martin.petersen@oracle.com>
Acked-by: Douglas Gilbert <dgilbert@interlog.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
[bwh: Backported to 3.2: adjust context; unwrap the if-statement]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 846a136881 upstream.
Michael Olbrich reported that his test program fails when built with
-O2 -mcpu=cortex-a8 -mfpu=neon, and a kernel which supports v6 and v7
CPUs:
volatile int x = 2;
volatile int64_t y = 2;
int main() {
volatile int a = 0;
volatile int64_t b = 0;
while (1) {
a = (a + x) % (1 << 30);
b = (b + y) % (1 << 30);
assert(a == b);
}
}
and two instances are run. When built for just v7 CPUs, this program
works fine. It uses the "vadd.i64 d19, d18, d16" VFP instruction.
It appears that we do not save the high-16 double VFP registers across
context switches when the kernel is built for v6 CPUs. Fix that.
Tested-By: Michael Olbrich <m.olbrich@pengutronix.de>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a520d52e99 upstream.
The Linux EC driver includes a mechanism to detect GPE storms,
and switch from interrupt-mode to polling mode. However, polling
mode sometimes doesn't work, so the workaround is problematic.
Also, different systems seem to need the threshold for detecting
the GPE storm at different levels.
ACPI_EC_STORM_THRESHOLD was initially 20 when it's created, and
was changed to 8 in 2.6.28 commit 06cf7d3c7 "ACPI: EC: lower interrupt storm
threshold" to fix kernel bug 11892 by forcing the laptop in that bug to
work in polling mode. However in bug 45151, it works fine in interrupt
mode if we lift the threshold back to 20.
This patch makes the threshold a module parameter so that user has a
flexible option to debug/workaround this issue.
The default is unchanged.
This is also a preparation patch to fix specific systems:
https://bugzilla.kernel.org/show_bug.cgi?id=45151
Signed-off-by: Feng Tang <feng.tang@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c99af3752b upstream.
Cloudlinux have a product called lve that includes a kernel module. This
was previously GPLed but is now under a proprietary license, but the
module continues to declare MODULE_LICENSE("GPL") and makes use of some
EXPORT_SYMBOL_GPL symbols. Forcibly taint it in order to avoid this.
Signed-off-by: Matthew Garrett <mjg59@srcf.ucam.org>
Cc: Alex Lyashkov <umka@cloudlinux.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 012a121184 upstream.
As detailed in the thread titled "viafb PLL/clock tweaking causes XO-1.5
instability," enabling or disabling the IGA1/IGA2 clocks causes occasional
stability problems during suspend/resume cycles on this platform.
This is rather odd, as the documentation suggests that clocks have two
states (on/off) and the default (stable) configuration is configured to
enable the clock only when it is needed. However, explicitly enabling *or*
disabling the clock triggers this system instability, suggesting that there
is a 3rd state at play here.
Leaving the clock enable/disable registers alone solves this problem.
This fixes spurious reboots during suspend/resume behaviour introduced by
commit b692a63a.
Signed-off-by: Daniel Drake <dsd@laptop.org>
Signed-off-by: Florian Tobias Schandinat <FlorianSchandinat@gmx.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cf9182e90b upstream.
Processes that open and close multiple files may end up setting this
oo_last_closed_stid without freeing what was previously pointed to.
This can result in a major leak, visible for example by watching the
nfsd4_stateids line of /proc/slabinfo.
Reported-by: Cyril B. <cbay@excellency.fr>
Tested-by: Cyril B. <cbay@excellency.fr>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit aaeb61a97b upstream.
`pc236_detach()` is called by the comedi core if it attempted to attach
a device and failed. `pc236_detach()` calls `pc236_intr_disable()` if
the comedi device private data pointer (`devpriv`) is non-null. This
test is insufficient as `pc236_intr_disable()` accesses hardware
registers and the attach routine may have failed before it has saved
their I/O base addresses.
Fix it by checking `dev->iobase` is non-zero before calling
`pc236_intr_disable()` as that means the I/O base addresses have been
saved and the hardware registers can be accessed. It also implies the
comedi device private data pointer is valid, so there is no need to
check it.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
[Ian Abbott: This patch is for the stable 3.0 kernel.]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 4c67525849 ]
After commit e2446eaa ("tcp_v4_send_reset: binding oif to iif in no
sock case").. tcp resets are always lost, when routing is asymmetric.
Yes, backing out that patch will result in misrouting of resets for
dead connections which used interface binding when were alive, but we
actually cannot do anything here. What's died that's died and correct
handling normal unbound connections is obviously a priority.
Comment to comment:
> This has few benefits:
> 1. tcp_v6_send_reset already did that.
It was done to route resets for IPv6 link local addresses. It was a
mistake to do so for global addresses. The patch fixes this as well.
Actually, the problem appears to be even more serious than guaranteed
loss of resets. As reported by Sergey Soloviev <sol@eqv.ru>, those
misrouted resets create a lot of arp traffic and huge amount of
unresolved arp entires putting down to knees NAT firewalls which use
asymmetric routing.
Signed-off-by: Alexey Kuznetsov <kuznet@ms2.inr.ac.ru>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 5175a5e76b ]
This is the revised patch for fixing rds-ping spinlock recursion
according to Venkat's suggestions.
RDS ping/pong over TCP feature has been broken for years(2.6.39 to
3.6.0) since we have to set TCP cork and call kernel_sendmsg() between
ping/pong which both need to lock "struct sock *sk". However, this
lock has already been hold before rds_tcp_data_ready() callback is
triggerred. As a result, we always facing spinlock resursion which
would resulting in system panic.
Given that RDS ping is only used to test the connectivity and not for
serious performance measurements, we can queue the pong transmit to
rds_wq as a delayed response.
Reported-by: Dan Carpenter <dan.carpenter@oracle.com>
CC: Venkat Venkatsubra <venkat.x.venkatsubra@oracle.com>
CC: David S. Miller <davem@davemloft.net>
CC: James Morris <james.l.morris@oracle.com>
Signed-off-by: Jie Liu <jeff.liu@oracle.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 48cc32d38a ]
6a32e4f9dd made the vlan code skip marking
vlan-tagged frames for not locally configured vlans as PACKET_OTHERHOST if
there was an rx_handler, as the rx_handler could cause the frame to be received
on a different (virtual) vlan-capable interface where that vlan might be
configured.
As rx_handlers do not necessarily return RX_HANDLER_ANOTHER, this could cause
frames for unknown vlans to be delivered to the protocol stack as if they had
been received untagged.
For example, if an ipv6 router advertisement that's tagged for a locally not
configured vlan is received on an interface with macvlan interfaces attached,
macvlan's rx_handler returns RX_HANDLER_PASS after delivering the frame to the
macvlan interfaces, which caused it to be passed to the protocol stack, leading
to ipv6 addresses for the announced prefix being configured even though those
are completely unusable on the underlying interface.
The fix moves marking as PACKET_OTHERHOST after the rx_handler so the
rx_handler, if there is one, sees the frame unchanged, but afterwards,
before the frame is delivered to the protocol stack, it gets marked whether
there is an rx_handler or not.
Signed-off-by: Florian Zumbiehl <florz@florz.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e1f165032c ]
The retry loop in neigh_resolve_output() and neigh_connected_output()
call dev_hard_header() with out reseting the skb to network_header.
This causes the retry to fail with skb_under_panic. The fix is to
reset the network_header within the retry loop.
Signed-off-by: Ramesh Nagappa <ramesh.nagappa@ericsson.com>
Reviewed-by: Shawn Lu <shawn.lu@ericsson.com>
Reviewed-by: Robert Coulson <robert.coulson@ericsson.com>
Reviewed-by: Billie Alsup <billie.alsup@ericsson.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a595c1ce4c upstream.
We weren't checking whether the resource was in use before calling
res_free(), so applications which called STREAMOFF on a v4l2 device that
wasn't already streaming would cause a BUG() to be hit (MythTV).
Reported-by: Larry Finger <larry.finger@lwfinger.net>
Reported-by: Jay Harbeston <jharbestonus@gmail.com>
Signed-off-by: Devin Heitmueller <dheitmueller@kernellabs.com>
Signed-off-by: Mauro Carvalho Chehab <mchehab@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 2856cc2e4d ]
On a 2-node machine with 256GB of ram we get 512 lines of
console output, which is just too much.
This mimicks Yinghai Lu's x86 commit c2b91e2eec
(x86_64/mm: check and print vmemmap allocation continuous) except that
we aren't ever going to get contiguous block pointers in between calls
so just print when the virtual address or node changes.
This decreases the output by an order of 16.
Also demote this to KERN_DEBUG.
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit a27032eee8 ]
There are multiple errors in how sys_sparc64_personality() handles
personality flags stored in top three bytes.
- directly comparing current->personality against PER_LINUX32 doesn't work
in cases when any of the personality flags stored in the top three bytes
are used.
- directly forcefully setting personality to PER_LINUX32 or PER_LINUX
discards any flags stored in the top three bytes
Fix the first one by properly using personality() macro to compare only
PER_MASK bytes.
Fix the second one by setting only the bits that should be set, instead of
overwriting the whole value.
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e793d8c674 ]
There was a serious disconnect in the logic happening in
sparc_pmu_disable_event() vs. sparc_pmu_enable_event().
Event disable is implemented by programming a NOP event into the PCR.
However, event enable was not reversing this operation. Instead, it
was setting the User/Priv/Hypervisor trace enable bits.
That's not sparc_pmu_enable_event()'s job, that's what
sparc_pmu_enable() and sparc_pmu_disable() do .
The intent of sparc_pmu_enable_event() is clear, since it first clear
out the event type encoding field. So fix this by OR'ing in the event
encoding rather than the trace enable bits.
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 08280e6c4c ]
If the MM is not active, only report the top-level PC. Do not try to
access the address space.
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 55c2770e41 ]
we want syscall_trace_leave() called on exit from any syscall;
skipping its call in case we'd done force_successful_syscall_return()
is broken...
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c07496fa61 upstream.
... we will botch up the bit17 swizzling. Furthermore tiled pwrite is
a (now) unused slowpath, so no one really cares.
This fixes the last swizzling issues I have with i-g-t on my bit17
swizzling i915G. No regression, it's been broken since the dawn of
gem, but it's nice for regression tracking when really _all_ i-g-t
tests work.
Actually this is not true, Chris Wilson noticed while reviewing this
patch that the commit
commit d9e86c0ee6
Author: Chris Wilson <chris@chris-wilson.co.uk>
Date: Wed Nov 10 16:40:20 2010 +0000
drm/i915: Pipelined fencing [infrastructure]
contained a functional change that broke things.
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[Luís Picciochi Oliveira: I picked the commit Daniel suggested and
edited it to affect the code that matched the same logical location on
the same function.]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 52f5509fe8 upstream.
This patch fixes a regression introduced by commit "e1000: do vlan
cleanup (799d531)".
Apparently some e1000 chips (not mine) are sensitive about the order of
setting vlan filter and vlan stripping/inserting functionality. So this
patch changes the order so it's the same as before vlan cleanup.
Reported-by: Ben Greear <greearb@candelatech.com>
Signed-off-by: Jiri Pirko <jpirko@redhat.com>
Tested-by: Ben Greear <greearb@candelatech.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
[Jonathan Nieder: It doesn't apply cleanly to kernels before
v3.3-rc1~182^2~581 (net: introduce and use netdev_features_t for
device features sets) but a backport is straightforward.]
Signed-off-by: Jonathan Nieder <jrnieder@gmail.com>
Tested-by: Andrey Jr. Melnikov <temnota@kmv.ru>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bf7a01bf79 upstream.
The NAND_CHIPOPTIONS_MSK has limited utility and is causing real bugs. It
silently masks off at least one flag that might be set by the driver
(NAND_NO_SUBPAGE_WRITE). This breaks the GPMI NAND driver and possibly
others.
Really, as long as driver writers exercise a small amount of care with
NAND_* options, this mask is not necessary at all; it was only here to
prevent certain options from accidentally being set by the driver. But the
original thought turns out to be a bad idea occasionally. Thus, kill it.
Note, this patch fixes some major gpmi-nand breakage.
Signed-off-by: Brian Norris <computersforpeace@gmail.com>
Tested-by: Huang Shijie <shijie8@gmail.com>
Cc: stable@vger.kernel.org
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
[Brian Norris: This is a backport for v3.2 stable.]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 09e05d4805 upstream.
ext3 users of data=journal mode with blocksize < pagesize were occasionally
hitting assertion failure in journal_commit_transaction() checking whether the
transaction has at least as many credits reserved as buffers attached. The
core of the problem is that when a file gets truncated, buffers that still need
checkpointing or that are attached to the committing transaction are left with
buffer_mapped set. When this happens to buffers beyond i_size attached to a
page stradding i_size, subsequent write extending the file will see these
buffers and as they are mapped (but underlying blocks were freed) things go
awry from here.
The assertion failure just coincidentally (and in this case luckily as we would
start corrupting filesystem) triggers due to journal_head not being properly
cleaned up as well.
Under some rare circumstances this bug could even hit data=ordered mode users.
There the assertion won't trigger and we would end up corrupting the
filesystem.
We fix the problem by unmapping buffers if possible (in lots of cases we just
need a buffer attached to a transaction as a place holder but it must not be
written out anyway). And in one case, we just have to bite the bullet and wait
for transaction commit to finish.
Reviewed-by: Josef Bacik <jbacik@fusionio.com>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3be324a94d upstream.
These are the hunks that I dropped when backporting for 3.2.24,
which are applicable now that we also have commit f34cd9ca
('samsung-laptop: don't handle backlight if handled by acpi/video').
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f34cd9ca93 upstream.
samsung-laptop is not at all related to ACPI, but since this interface
is not documented at all, and the driver has to use it at load to
understand how it works on the laptop, I think it's a good idea to
disable it if a better solution is available.
Signed-off-by: Corentin Chary <corentincj@iksaif.net>
Signed-off-by: Matthew Garrett <mjg@redhat.com>
[bwh: Backported to 3.2:
- Adjust context, and change return to goto, since we do not have commit
5dea7a2 ('samsung-laptop: move code into init/exit functions')
- Use static variable since we do not have commit a6df489
('samsung-laptop: put all local variables in a single structure')]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5276e16bb6 upstream.
When using the xt_set.h header in userspace, one will get these gcc
reports:
ipset/ip_set.h:184:1: error: unknown type name "u16"
In file included from libxt_SET.c:21:0:
netfilter/xt_set.h:61:2: error: unknown type name "u32"
netfilter/xt_set.h:62:2: error: unknown type name "u32"
Signed-off-by: Jan Engelhardt <jengelh@medozas.de>
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 15a13bbdff upstream.
This fixes a resume regression introduced in
commit 7dd4906586
Author: Chris Wilson <chris@chris-wilson.co.uk>
Date: Wed Mar 21 10:48:18 2012 +0000
drm/i915: Mark untiled BLT commands as fenced on gen2/3
which fixed fencing tracking for untiled blt commands.
A side effect of that patch was that now also untiled objects have a
non-zero obj->last_fenced_seqno to track when a fence can be set up
after a pipelined tiling change. Unfortunately this was only cleared
by the fence setup and teardown code, resulting in tons of untiled but
inactive objects with non-zero last_fenced_seqno.
Now after resume we completely reset the seqno tracking, both on the
driver side (by setting dev_priv->next_seqno = 1) and on the hw side
(by allocating a new hws page, which contains the seqnos). Hilarity
and indefinite waits ensued from the stale seqnos in
obj->last_fenced_seqno from before the suspend.
The fix is to properly clear the fencing tracking state like we
already do for the normal gpu rendering while moving objects off the
active list.
Reported-and-tested-by: "Rafael J. Wysocki" <rjw@sisk.pl>
Cc: Jiri Slaby <jslaby@suse.cz>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7dd4906586 upstream.
The BLT commands on gen2/3 utilize the fence registers and so we cannot
modify any fences for the object whilst those commands are in flight.
Currently we marked tiled commands as occupying a fence, but forgot to
restrict the untiled commands from preventing a fence being assigned
before they were completed.
One side-effect is that we ten have to double check that a fence was
allocated for a fenced buffer during move-to-active.
Reported-by: Jiri Slaby <jirislaby@gmail.com>
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=43427
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47990
Reviewed-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Testcase: i-g-t/tests/gem_tiled_after_untiled_blt
Tested-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2: The nesting of if-statements in the old
i915_gem_execbuffer_reserve() differs from pin_and_fence_object(),
so don't move the assignment of obj->pending_fenced_gpu_access but
adjust the boolean expression as recommended by Daniel Vetter.]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c9c4b6f6c2 upstream.
It looks like the desktop variants of i915 and i945 also have the DCC
register to control dram channel interleave and cpu side bit6
swizzling.
Unfortunately internal Cspec/ConfigDB documentation for these ancient chips
have already been dropped and there seem to be no archives. Also
somebody thought the swizzling behaviour is surely a worthy secret to
keep and redacted any mention of these fields from the published Intel
datasheets.
I suspect the hw engineers were really proud of the page coloring
they've achieved in their first dual channel dram controller with
bit17 - after all Bspec explains in great length the optimal layout of
page frame numbers modulo 4 for the color and depth buffers, too.
Later on when they've started to work on VT-d they shamefully
discoverd their stupidity and tried to cover the tracks ...
Tested-by: Daniel Vetter <daniel.vetter@ffwll.ch> (i915g)
Tested-by: Pavel Ondračka <pavel.ondracka@email.cz> (i945g)
Tested-by: Chris Wilson <chris@chris-wilson.co.uk>
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=42625
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b63f4053cc upstream.
According to xHCI spec section 4.6.1.1 and section 4.6.1.2,
after aborting a command on the command ring, xHC will
generate a command completion event with its completion
code set to Command Ring Stopped at least. If a command is
currently executing at the time of aborting a command, xHC
also generate a command completion event with its completion
code set to Command Abort. When the command ring is stopped,
software may remove, add, or rearrage Command Descriptors.
To cancel a command, software will initialize a command
descriptor for the cancel command, and add it into a
cancel_cmd_list of xhci. When the command ring is stopped,
software will find the command trbs described by command
descriptors in cancel_cmd_list and modify it to No Op
command. If software can't find the matched trbs, we can
think it had been finished.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
[bwh: Backported to 3.2: inc_deq() needs an additional 'consumer' argument;
Jonathan Nieder worked out that this should be false]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3a3847e007 upstream.
As reported by Steven Rostedt, e1000 has a lockdep splat added
during the recent merge window. The issue is that
cancel_delayed_work is called while holding our private mutex.
There is no reason that I can see to hold the mutex during pci
shutdown, it was more just paranoia that I put the mutex_lock
around the call to e1000_down.
In a quick survey lots of drivers handle locking differently when
being called by the pci layer. The assumption here is that we
don't need the mutexes' protection in this function because
the driver could not be unloaded while in the shutdown handler
which is only called at reboot or poweroff.
Reported-by: Steven Rostedt <rostedt@goodmis.org>
Signed-off-by: Jesse Brandeburg <jesse.brandeburg@intel.com>
Tested-by: Steven Rostedt <rostedt@goodmis.org>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 82e6bfe2fb upstream.
Commit v2.6.19-rc1~1272^2~41 tells us that r->cost != 0 can happen when
a running state is saved to userspace and then reinstated from there.
Make sure that private xt_limit area is initialized with correct values.
Otherwise, random matchings due to use of uninitialized memory.
Signed-off-by: Jan Engelhardt <jengelh@inai.de>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2614f86490 upstream.
In __nf_ct_expect_check, the function refresh_timer returns 1
if a matching expectation is found and its timer is successfully
refreshed. This results in nf_ct_expect_related returning 0.
Note that at this point:
- the passed expectation is not inserted in the expectation table
and its timer was not initialized, since we have refreshed one
matching/existing expectation.
- nf_ct_expect_alloc uses kmem_cache_alloc, so the expectation
timer is in some undefined state just after the allocation,
until it is appropriately initialized.
This can be a problem for the SIP helper during the expectation
addition:
...
if (nf_ct_expect_related(rtp_exp) == 0) {
if (nf_ct_expect_related(rtcp_exp) != 0)
nf_ct_unexpect_related(rtp_exp);
...
Note that nf_ct_expect_related(rtp_exp) may return 0 for the timer refresh
case that is detailed above. Then, if nf_ct_unexpect_related(rtcp_exp)
returns != 0, nf_ct_unexpect_related(rtp_exp) is called, which does:
spin_lock_bh(&nf_conntrack_lock);
if (del_timer(&exp->timeout)) {
nf_ct_unlink_expect(exp);
nf_ct_expect_put(exp);
}
spin_unlock_bh(&nf_conntrack_lock);
Note that del_timer always returns false if the timer has been
initialized. However, the timer was not initialized since setup_timer
was not called, therefore, the expectation timer remains in some
undefined state. If I'm not missing anything, this may lead to the
removal an unexistent expectation.
To fix this, the optimization that allows refreshing an expectation
is removed. Now nf_conntrack_expect_related looks more consistent
to me since it always add the expectation in case that it returns
success.
Thanks to Patrick McHardy for participating in the discussion of
this patch.
I think this may be the source of the problem described by:
http://marc.info/?l=netfilter-devel&m=134073514719421&w=2
Reported-by: Rafal Fitt <rafalf@aplusc.com.pl>
Acked-by: Patrick McHardy <kaber@trash.net>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f22eb25cf5 upstream.
Via-headers are parsed beginning at the first character after the Via-address.
When the address is translated first and its length decreases, the offset to
start parsing at is incorrect and header parameters might be missed.
Update the offset after translating the Via-address to fix this.
Signed-off-by: Patrick McHardy <kaber@trash.net>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3f509c689a upstream.
We're hitting bug while trying to reinsert an already existing
expectation:
kernel BUG at kernel/timer.c:895!
invalid opcode: 0000 [#1] SMP
[...]
Call Trace:
<IRQ>
[<ffffffffa0069563>] nf_ct_expect_related_report+0x4a0/0x57a [nf_conntrack]
[<ffffffff812d423a>] ? in4_pton+0x72/0x131
[<ffffffffa00ca69e>] ip_nat_sdp_media+0xeb/0x185 [nf_nat_sip]
[<ffffffffa00b5b9b>] set_expected_rtp_rtcp+0x32d/0x39b [nf_conntrack_sip]
[<ffffffffa00b5f15>] process_sdp+0x30c/0x3ec [nf_conntrack_sip]
[<ffffffff8103f1eb>] ? irq_exit+0x9a/0x9c
[<ffffffffa00ca738>] ? ip_nat_sdp_media+0x185/0x185 [nf_nat_sip]
We have to remove the RTP expectation if the RTCP expectation hits EBUSY
since we keep trying with other ports until we succeed.
Reported-by: Rafal Fitt <rafalf@aplusc.com.pl>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 07153c6ec0 upstream.
It was reported that the Linux kernel sometimes logs:
klogd: [2629147.402413] kernel BUG at net / netfilter /
nf_conntrack_proto_tcp.c: 447!
klogd: [1072212.887368] kernel BUG at net / netfilter /
nf_conntrack_proto_tcp.c: 392
ipv4_get_l4proto() in nf_conntrack_l3proto_ipv4.c and tcp_error() in
nf_conntrack_proto_tcp.c should catch malformed packets, so the errors
at the indicated lines - TCP options parsing - should not happen.
However, tcp_error() relies on the "dataoff" offset to the TCP header,
calculated by ipv4_get_l4proto(). But ipv4_get_l4proto() does not check
bogus ihl values in IPv4 packets, which then can slip through tcp_error()
and get caught at the TCP options parsing routines.
The patch fixes ipv4_get_l4proto() by invalidating packets with bogus
ihl value.
The patch closes netfilter bugzilla id 771.
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8f6189684e upstream.
Make stop scheduler class do the same accounting as other classes,
Migration threads can be caught in the act while doing exec balancing,
leading to the below due to use of unmaintained ->se.exec_start. The
load that triggered this particular instance was an apparently out of
control heavily threaded application that does system monitoring in
what equated to an exec bomb, with one of the VERY frequently migrated
tasks being ps.
%CPU PID USER CMD
99.3 45 root [migration/10]
97.7 53 root [migration/12]
97.0 57 root [migration/13]
90.1 49 root [migration/11]
89.6 65 root [migration/15]
88.7 17 root [migration/3]
80.4 37 root [migration/8]
78.1 41 root [migration/9]
44.2 13 root [migration/2]
Signed-off-by: Mike Galbraith <mgalbraith@suse.de>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1344051854.6739.19.camel@marge.simpson.net
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
[Steven Rostedt: backport for 3.2.]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e85c597469 upstream.
Dial back the aggressiveness of the controller lockup detection thread.
Currently it will declare the controller to be locked up if it goes
for 10 seconds with no interrupts and no change in the heartbeat
register. Dial back this to 30 seconds with no heartbeat change, and
also snoop the ioctl path and if a firmware flash command is detected,
dial it back further to 4 minutes until the firmware flash command
completes. The reason for this is that during the firmware flash
operation, the controller apparently doesn't update the heartbeat
register as frequently as it is supposed to, and we can get a false
positive.
Signed-off-by: Stephen M. Cameron <scameron@beardog.cce.hp.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 00442ad04a upstream.
Commit cc9a6c8776 ("cpuset: mm: reduce large amounts of memory barrier
related damage v3") introduced a potential memory corruption.
shmem_alloc_page() uses a pseudo vma and it has one significant unique
combination, vma->vm_ops=NULL and vma->policy->flags & MPOL_F_SHARED.
get_vma_policy() does NOT increase a policy ref when vma->vm_ops=NULL
and mpol_cond_put() DOES decrease a policy ref when a policy has
MPOL_F_SHARED. Therefore, when a cpuset update race occurs,
alloc_pages_vma() falls in 'goto retry_cpuset' path, decrements the
reference count and frees the policy prematurely.
Signed-off-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Christoph Lameter <cl@linux.com>
Cc: Josh Boyer <jwboyer@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 63f74ca21f upstream.
When shared_policy_replace() fails to allocate new->policy is not freed
correctly by mpol_set_shared_policy(). The problem is that shared
mempolicy code directly call kmem_cache_free() in multiple places where
it is easy to make a mistake.
This patch creates an sp_free wrapper function and uses it. The bug was
introduced pre-git age (IOW, before 2.6.12-rc2).
[mgorman@suse.de: Editted changelog]
Signed-off-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Christoph Lameter <cl@linux.com>
Cc: Josh Boyer <jwboyer@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b22d127a39 upstream.
shared_policy_replace() use of sp_alloc() is unsafe. 1) sp_node cannot
be dereferenced if sp->lock is not held and 2) another thread can modify
sp_node between spin_unlock for allocating a new sp node and next
spin_lock. The bug was introduced before 2.6.12-rc2.
Kosaki's original patch for this problem was to allocate an sp node and
policy within shared_policy_replace and initialise it when the lock is
reacquired. I was not keen on this approach because it partially
duplicates sp_alloc(). As the paths were sp->lock is taken are not that
performance critical this patch converts sp->lock to sp->mutex so it can
sleep when calling sp_alloc().
[kosaki.motohiro@jp.fujitsu.com: Original patch]
Signed-off-by: Mel Gorman <mgorman@suse.de>
Acked-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Reviewed-by: Christoph Lameter <cl@linux.com>
Cc: Josh Boyer <jwboyer@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 869833f2c5 upstream.
Dave Jones' system call fuzz testing tool "trinity" triggered the
following bug error with slab debugging enabled
=============================================================================
BUG numa_policy (Not tainted): Poison overwritten
-----------------------------------------------------------------------------
INFO: 0xffff880146498250-0xffff880146498250. First byte 0x6a instead of 0x6b
INFO: Allocated in mpol_new+0xa3/0x140 age=46310 cpu=6 pid=32154
__slab_alloc+0x3d3/0x445
kmem_cache_alloc+0x29d/0x2b0
mpol_new+0xa3/0x140
sys_mbind+0x142/0x620
system_call_fastpath+0x16/0x1b
INFO: Freed in __mpol_put+0x27/0x30 age=46268 cpu=6 pid=32154
__slab_free+0x2e/0x1de
kmem_cache_free+0x25a/0x260
__mpol_put+0x27/0x30
remove_vma+0x68/0x90
exit_mmap+0x118/0x140
mmput+0x73/0x110
exit_mm+0x108/0x130
do_exit+0x162/0xb90
do_group_exit+0x4f/0xc0
sys_exit_group+0x17/0x20
system_call_fastpath+0x16/0x1b
INFO: Slab 0xffffea0005192600 objects=27 used=27 fp=0x (null) flags=0x20000000004080
INFO: Object 0xffff880146498250 @offset=592 fp=0xffff88014649b9d0
The problem is that the structure is being prematurely freed due to a
reference count imbalance. In the following case mbind(addr, len) should
replace the memory policies of both vma1 and vma2 and thus they will
become to share the same mempolicy and the new mempolicy will have the
MPOL_F_SHARED flag.
+-------------------+-------------------+
| vma1 | vma2(shmem) |
+-------------------+-------------------+
| |
addr addr+len
alloc_pages_vma() uses get_vma_policy() and mpol_cond_put() pair for
maintaining the mempolicy reference count. The current rule is that
get_vma_policy() only increments refcount for shmem VMA and
mpol_conf_put() only decrements refcount if the policy has
MPOL_F_SHARED.
In above case, vma1 is not shmem vma and vma->policy has MPOL_F_SHARED!
The reference count will be decreased even though was not increased
whenever alloc_page_vma() is called. This has been broken since commit
[52cd3b07: mempolicy: rework mempolicy Reference Counting] in 2008.
There is another serious bug with the sharing of memory policies.
Currently, mempolicy rebind logic (it is called from cpuset rebinding)
ignores a refcount of mempolicy and override it forcibly. Thus, any
mempolicy sharing may cause mempolicy corruption. The bug was
introduced by commit [68860ec1: cpusets: automatic numa mempolicy
rebinding].
Ideally, the shared policy handling would be rewritten to either
properly handle COW of the policy structures or at least reference count
MPOL_F_SHARED based exclusively on information within the policy.
However, this patch takes the easier approach of disabling any policy
sharing between VMAs. Each new range allocated with sp_alloc will
allocate a new policy, set the reference count to 1 and drop the
reference count of the old policy. This increases the memory footprint
but is not expected to be a major problem as mbind() is unlikely to be
used for fine-grained ranges. It is also inefficient because it means
we allocate a new policy even in cases where mbind_range() could use the
new_policy passed to it. However, it is more straight-forward and the
change should be invisible to the user.
[mgorman@suse.de: Edited changelog]
Reported-by: Dave Jones <davej@redhat.com>,
Cc: Christoph Lameter <cl@linux.com>,
Reviewed-by: Christoph Lameter <cl@linux.com>
Signed-off-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Cc: Josh Boyer <jwboyer@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d6cf86d8f2 upstream.
A value of efi.runtime_version is checked before calling
update_capsule()/query_variable_info() as follows.
But it isn't initialized anywhere.
<snip>
static efi_status_t virt_efi_query_variable_info(u32 attr,
u64 *storage_space,
u64 *remaining_space,
u64 *max_variable_size)
{
if (efi.runtime_version < EFI_2_00_SYSTEM_TABLE_REVISION)
return EFI_UNSUPPORTED;
<snip>
This patch initializes a value of efi.runtime_version at boot time.
Signed-off-by: Seiji Aguchi <seiji.aguchi@hds.com>
Acked-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Matt Fleming <matt.fleming@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 62444b7462 upstream.
- Stop the displays from accessing the FB
- Block CPU access
- Turn off MC client access
This should fix issues some users have seen, especially
with UEFI, when changing the MC FB location that result
in hangs or display corruption.
v2: fix crtc enabled check noticed by Luca Tettamanti
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2:
- Drop DCE6 cases
- Call evergreen_mc_wait_for_idle() directly
- Add dce4_wait_for_vblank() (commits 3ae19b750b
and 4a15903db0) and call it directly
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 64e6651dcc upstream.
Since eCryptfs only calls fput() on the lower file in
ecryptfs_release(), eCryptfs should call the lower filesystem's
->flush() from ecryptfs_flush().
If the lower filesystem implements ->flush(), then eCryptfs should try
to flush out any dirty pages prior to calling the lower ->flush(). If
the lower filesystem does not implement ->flush(), then eCryptfs has no
need to do anything in ecryptfs_flush() since dirty pages are now
written out to the lower filesystem in ecryptfs_release().
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7149f2558d upstream.
Fixes a regression caused by:
821f749 eCryptfs: Revert to a writethrough cache model
That patch reverted some code (specifically, 32001d6f) that was
necessary to properly handle open() -> mmap() -> close() -> dirty pages
-> munmap(), because the lower file could be closed before the dirty
pages are written out.
Rather than reapplying 32001d6f, this approach is a better way of
ensuring that the lower file is still open in order to handle writing
out the dirty pages. It is called from ecryptfs_release(), while we have
a lock on the lower file pointer, just before the lower file gets the
final fput() and we overwrite the pointer.
https://launchpad.net/bugs/1047261
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Artemy Tregubenko <me@arty.name>
Tested-by: Artemy Tregubenko <me@arty.name>
Tested-by: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 821f7494a7 upstream.
A change was made about a year ago to get eCryptfs to better utilize its
page cache during writes. The idea was to do the page encryption
operations during page writeback, rather than doing them when initially
writing into the page cache, to reduce the number of page encryption
operations during sequential writes. This meant that the encrypted page
would only be written to the lower filesystem during page writeback,
which was a change from how eCryptfs had previously wrote to the lower
filesystem in ecryptfs_write_end().
The change caused a few eCryptfs-internal bugs that were shook out.
Unfortunately, more grave side effects have been identified that will
force changes outside of eCryptfs. Because the lower filesystem isn't
consulted until page writeback, eCryptfs has no way to pass lower write
errors (ENOSPC, mainly) back to userspace. Additionaly, it was reported
that quotas could be bypassed because of the way eCryptfs may sometimes
open the lower filesystem using a privileged kthread.
It would be nice to resolve the latest issues, but it is best if the
eCryptfs commits be reverted to the old behavior in the meantime.
This reverts:
32001d6f "eCryptfs: Flush file in vma close"
5be79de2 "eCryptfs: Flush dirty pages in setattr"
57db4e8d "ecryptfs: modify write path to encrypt page in writepage"
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Tested-by: Colin King <colin.king@canonical.com>
Cc: Colin King <colin.king@canonical.com>
Cc: Thieu Le <thieule@google.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e3ccaa9761 upstream.
Historically, eCryptfs has only initialized lower files in the
ecryptfs_create() path. Lower file initialization is the act of writing
the cryptographic metadata from the inode's crypt_stat to the header of
the file. The ecryptfs_open() path already expects that metadata to be
in the header of the file.
A number of users have reported empty lower files in beneath their
eCryptfs mounts. Most of the causes for those empty files being left
around have been addressed, but the presence of empty files causes
problems due to the lack of proper cryptographic metadata.
To transparently solve this problem, this patch initializes empty lower
files in the ecryptfs_open() error path. If the metadata is unreadable
due to the lower inode size being 0, plaintext passthrough support is
not in use, and the metadata is stored in the header of the file (as
opposed to the user.ecryptfs extended attribute), the lower file will be
initialized.
The number of nested conditionals in ecryptfs_open() was getting out of
hand, so a helper function was created. To avoid the same nested
conditional problem, the conditional logic was reversed inside of the
helper function.
https://launchpad.net/bugs/911507
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Cc: John Johansen <john.johansen@canonical.com>
Cc: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8bc2d3cf61 upstream.
ecryptfs_create() creates a lower inode, allocates an eCryptfs inode,
initializes the eCryptfs inode and cryptographic metadata attached to
the inode, and then writes the metadata to the header of the file.
If an error was to occur after the lower inode was created, an empty
lower file would be left in the lower filesystem. This is a problem
because ecryptfs_open() refuses to open any lower files which do not
have the appropriate metadata in the file header.
This patch properly unlinks the lower inode when an error occurs in the
later stages of ecryptfs_create(), reducing the chance that an empty
lower file will be left in the lower filesystem.
https://launchpad.net/bugs/872905
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Cc: John Johansen <john.johansen@canonical.com>
Cc: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 68766a2edc upstream.
In case we detect a problem and bail out, we fail to set "ret" to a
nonzero value, and udf_load_logicalvol will mistakenly report success.
Signed-off-by: Nikola Pajkovsky <npajkovs@redhat.com>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 49999ab27e upstream.
In autofs4_d_automount(), if a mount fail occurs the AUTOFS_INF_PENDING
mount pending flag is not cleared.
One effect of this is when using the "browse" option, directory entry
attributes show up with all "?"s due to the incorrect callback and
subsequent failure return (when in fact no callback should be made).
Signed-off-by: Ian Kent <ikent@redhat.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 790198f74c upstream.
Fix two bugs of the /dev/fw* character device concerning the
FW_CDEV_IOC_GET_INFO ioctl with nonzero fw_cdev_get_info.bus_reset.
(Practically all /dev/fw* clients issue this ioctl right after opening
the device.)
Both bugs are caused by sizeof(struct fw_cdev_event_bus_reset) being 36
without natural alignment and 40 with natural alignment.
1) Memory corruption, affecting i386 userland on amd64 kernel:
Userland reserves a 36 bytes large buffer, kernel writes 40 bytes.
This has been first found and reported against libraw1394 if
compiled with gcc 4.7 which happens to order libraw1394's stack such
that the bug became visible as data corruption.
2) Information leak, affecting all kernel architectures except i386:
4 bytes of random kernel stack data were leaked to userspace.
Hence limit the respective copy_to_user() to the 32-bit aligned size of
struct fw_cdev_event_bus_reset.
Reported-by: Simon Kirby <sim@hostway.ca>
Signed-off-by: Stefan Richter <stefanr@s5r6.in-berlin.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 36e4f20af8 upstream.
Commit 0c176d52b0 ("mm: hugetlb: fix pgoff computation when unmapping
page from vma") fixed pgoff calculation but it has replaced it by
vma_hugecache_offset() which is not approapriate for offsets used for
vma_prio_tree_foreach() because that one expects index in page units
rather than in huge_page_shift.
Johannes said:
: The resulting index may not be too big, but it can be too small: assume
: hpage size of 2M and the address to unmap to be 0x200000. This is regular
: page index 512 and hpage index 1. If you have a VMA that maps the file
: only starting at the second huge page, that VMAs vm_pgoff will be 512 but
: you ask for offset 1 and miss it even though it does map the page of
: interest. hugetlb_cow() will try to unmap, miss the vma, and retry the
: cow until the allocation succeeds or the skipped vma(s) go away.
Signed-off-by: Michal Hocko <mhocko@suse.cz>
Acked-by: Hillf Danton <dhillf@gmail.com>
Cc: Mel Gorman <mel@csn.ul.ie>
Cc: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: David Rientjes <rientjes@google.com>
Acked-by: Johannes Weiner <hannes@cmpxchg.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0c176d52b0 upstream.
The computation for pgoff is incorrect, at least with
(vma->vm_pgoff >> PAGE_SHIFT)
involved. It is fixed with the available method if HPAGE_SIZE is
concerned in page cache lookup.
[akpm@linux-foundation.org: use vma_hugecache_offset() directly, per Michal]
Signed-off-by: Hillf Danton <dhillf@gmail.com>
Cc: Mel Gorman <mel@csn.ul.ie>
Cc: Michal Hocko <mhocko@suse.cz>
Reviewed-by: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: David Rientjes <rientjes@google.com>
Reviewed-by: Michal Hocko <mhocko@suse.cz>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 027ef6c878 upstream.
In many places !pmd_present has been converted to pmd_none. For pmds
that's equivalent and pmd_none is quicker so using pmd_none is better.
However (unless we delete pmd_present) we should provide an accurate
pmd_present too. This will avoid the risk of code thinking the pmd is non
present because it's under __split_huge_page_map, see the pmd_mknotpresent
there and the comment above it.
If the page has been mprotected as PROT_NONE, it would also lead to a
pmd_present false negative in the same way as the race with
split_huge_page.
Because the PSE bit stays on at all times (both during split_huge_page and
when the _PAGE_PROTNONE bit get set), we could only check for the PSE bit,
but checking the PROTNONE bit too is still good to remember pmd_present
must always keep PROT_NONE into account.
This explains a not reproducible BUG_ON that was seldom reported on the
lists.
The same issue is in pmd_large, it would go wrong with both PROT_NONE and
if it races with split_huge_page.
Signed-off-by: Andrea Arcangeli <aarcange@redhat.com>
Acked-by: Rik van Riel <riel@redhat.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Cc: Hugh Dickins <hughd@google.com>
Cc: Mel Gorman <mgorman@suse.de>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ec4d9f626d upstream.
In fuzzing with trinity, lockdep protested "possible irq lock inversion
dependency detected" when isolate_lru_page() reenabled interrupts while
still holding the supposedly irq-safe tree_lock:
invalidate_inode_pages2
invalidate_complete_page2
spin_lock_irq(&mapping->tree_lock)
clear_page_mlock
isolate_lru_page
spin_unlock_irq(&zone->lru_lock)
isolate_lru_page() is correct to enable interrupts unconditionally:
invalidate_complete_page2() is incorrect to call clear_page_mlock() while
holding tree_lock, which is supposed to nest inside lru_lock.
Both truncate_complete_page() and invalidate_complete_page() call
clear_page_mlock() before taking tree_lock to remove page from radix_tree.
I guess invalidate_complete_page2() preferred to test PageDirty (again)
under tree_lock before committing to the munlock; but since the page has
already been unmapped, its state is already somewhat inconsistent, and no
worse if clear_page_mlock() moved up.
Reported-by: Sasha Levin <levinsasha928@gmail.com>
Deciphered-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Hugh Dickins <hughd@google.com>
Acked-by: Mel Gorman <mel@csn.ul.ie>
Cc: Rik van Riel <riel@redhat.com>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Michel Lespinasse <walken@google.com>
Cc: Ying Han <yinghan@google.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9d7d6e363b upstream.
read_persistent_clock uses a global variable, use a spinlock to
ensure non-atomic updates to the variable don't overlap and cause
time to move backwards.
Signed-off-by: Colin Cross <ccross@android.com>
Signed-off-by: R Sricharan <r.sricharan@ti.com>
Signed-off-by: Tony Lindgren <tony@atomide.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5feb54a1ab upstream.
We can use up to four bus-clocks; but on module remove, we didn't
disable the fourth bus clock.
Signed-off-by: Jaehoon Chung <jh80.chung@samsung.com>
Signed-off-by: Kyungmin Park <kyungmin.park@samsung.com>
Signed-off-by: Chris Ball <cjb@laptop.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d4f1e48bd1 upstream.
When the loopback timer handler is running, calling del_timer() (for STOP
trigger) will not wait for the handler to complete before deactivating the
timer. The timer gets rescheduled in the handler as usual. Then a subsequent
START trigger will try to start the timer using add_timer() with a timer pending
leading to a kernel panic.
Serialize the calls to add_timer() and del_timer() using a spin lock to avoid
this.
Signed-off-by: Omair Mohammed Abdullah <omair.m.abdullah@linux.intel.com>
Signed-off-by: Vinod Koul <vinod.koul@linux.intel.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e4db0952e5 upstream.
The Lenovo IdeaPad U310 has an internal mic where the right channel
is phase inverted.
Signed-off-by: Felix Kaechele <felix@fetzig.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 18dcd3044e upstream.
The internal mic input is phase inverted on one channel.
To avoid people in userspace summing the channels together
and get zero result, use a separate mixer control for the
inverted channel.
BugLink: https://bugs.launchpad.net/bugs/903853
Signed-off-by: David Henningsson <david.henningsson@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
[bwh: Backported to 3.2:
- Adjust context
- Change both invocations of apply_pin_fixup()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7c4a6106d6 upstream.
Fix multicast packet transmit logic to account for repetitive transmission
of single skb:
- correct check for available buffers (this bug may produce NULL pointer
crash dump in case of heavy traffic);
- update skb user count (incorrect user counter causes a warning dump from
net_tx_action routine during multicast transfers in systems with three or
more rionet participants).
Signed-off-by: Alexandre Bounine <alexandre.bounine@idt.com>
Cc: Matt Porter <mporter@kernel.crashing.org>
Cc: David S. Miller <davem@davemloft.net>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f96972f2dc upstream.
As kernel_power_off() calls disable_nonboot_cpus(), we may also want to
have kernel_restart() call disable_nonboot_cpus(). Doing so can help
machines that require boot cpu be the last alive cpu during reboot to
survive with kernel restart.
This fixes one reboot issue seen on imx6q (Cortex-A9 Quad). The machine
requires that the restart routine be run on the primary cpu rather than
secondary ones. Otherwise, the secondary core running the restart
routine will fail to come to online after reboot.
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0f6d93aa9d upstream.
The ACARD driver calls udelay() with a value > 2000, which leads to to
the following compilation error on ARM:
ERROR: "__bad_udelay" [drivers/scsi/atp870u.ko] undefined!
make[1]: *** [__modpost] Error 1
This is because udelay is defined on ARM, roughly speaking, as
#define udelay(n) ((n) > 2000 ? __bad_udelay() : \
__const_udelay((n) * ((2199023U*HZ)>>11)))
The argument to __const_udelay is the number of jiffies to wait divided
by 4, but this does not work unless the multiplication does not
overflow, and that is what the build error is designed to prevent. The
intended behavior can be achieved by using mdelay to call udelay
multiple times in a loop.
[jrnieder@gmail.com: adding context]
Signed-off-by: Martin Michlmayr <tbm@cyrius.com>
Signed-off-by: Jonathan Nieder <jrnieder@gmail.com>
Cc: James Bottomley <James.Bottomley@HansenPartnership.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c353acba28 upstream.
The call if_changed mechanism does not work when the command contains
backslashes. This basically is an issue with lzo and bzip2 compressed
kernels. The compressed binaries do not contain the uncompressed image
size, so these use size_append to append the size. This results in
backslashes in the executed command. With this if_changed always
detects a change in the command and rebuilds the compressed image even
if nothing has changed.
Fix this by escaping backslashes in make-cmd
Signed-off-by: Sascha Hauer <s.hauer@pengutronix.de>
Signed-off-by: Jan Luebbe <jlu@pengutronix.de>
Cc: Sam Ravnborg <sam@ravnborg.org>
Cc: Bernhard Walle <bernhard@bwalle.de>
Cc: Michal Marek <mmarek@suse.cz>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0eb5a35801 upstream.
Do the same as commit a03a202e95 ("dmaengine: failure to get a
specific DMA channel is not critical") to get rid of the following
messages during kernel boot:
dmaengine_get: failed to get dma1chan0: (-22)
dmaengine_get: failed to get dma1chan1: (-22)
dmaengine_get: failed to get dma1chan2: (-22)
dmaengine_get: failed to get dma1chan3: (-22)
..
Signed-off-by: Fabio Estevam <fabio.estevam@freescale.com>
Cc: Vinod Koul <vinod.koul@intel.com>
Cc: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: also apply changes to this logging statement
from commit 6343325023 ('dmaengine: Cleanup logging messages')]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f8f2ac9a76 upstream.
I can't even find how I figured this might be needed anymore. But sure
enough, the value I'm reading back on platforms doesn't match what the
docs recommends.
It seemed to fix Chris' GT1 in limited testing as well.
Tested-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Ben Widawsky <ben@bwidawsk.net>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2: open-code _MASKED_BIT_{ENABLE,DISABLE}]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 74d44445af upstream.
... since finish_page_flip needs the vblank timestamp generated
in drm_handle_vblank. Somehow all the gmch platforms get it right,
but all the pch platform irq handlers get is wrong. Hooray for copy&
pasting!
Currently this gets papered over by a gross hack in finish_page_flip.
A second patch will remove that.
Note that without this, the new timestamp sanity checks in flip_test
occasionally get tripped up, hence the cc: stable tag.
Reviewed-by: mario.kleiner@tuebingen.mpg.de
Tested-by: Imre Deak <imre.deak@intel.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2: no loop over pipes in ivybridge_irq_handler(),
so make a similar change to that in ironlake_irq_handler()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ca16f580a5 upstream.
We usually got away with ->next on the final entry being NULL, but it
finally bit me.
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
[bwh: Backported to 3.2: adjust filename]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cf0eb28d3b upstream.
This patch increases the default for nopin_timeout to 15 seconds (wait
between sending a new NopIN ping) and nopin_response_timeout to 30 seconds
(wait for NopOUT response before failing the connection) in order to avoid
false positives by iSCSI Initiators who are not always able (under load) to
respond to NopIN echo PING requests within the current 5 second window.
False positives have been observed recently using Open-iSCSI code on v3.3.x
with heavy large-block READ workloads over small MTU 1 Gb/sec ports, and
increasing these values to more reasonable defaults significantly reduces
the possibility of false positive NopIN response timeout events under
this specific workload.
Historically these have been set low to initiate connection recovery as
soon as possible if we don't hear a ping back, but for modern v3.x code
on 1 -> 10 Gb/sec ports these new defaults make alot more sense.
Cc: Christoph Hellwig <hch@lst.de>
Cc: Andy Grover <agrover@redhat.com>
Cc: Mike Christie <michaelc@cs.wisc.edu>
Cc: Hannes Reinecke <hare@suse.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8464dd52d3 upstream.
On some systems, e.g., kzm9g, MMCIF interfaces can produce spurious
interrupts without any active request. To prevent the Oops, that results
in such cases, don't dereference the mmc request pointer until we make
sure, that we are indeed processing such a request.
Reported-by: Tetsuyuki Kobayashi <koba@kmckk.co.jp>
Signed-off-by: Guennadi Liakhovetski <g.liakhovetski@gmx.de>
Signed-off-by: Chris Ball <cjb@laptop.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c4c8eeb4df upstream.
In some cases mmc_suspend_host() is not able to claim the
host and proceed with the suspend process. The core returns
-EBUSY to the host controller driver. Unfortunately, the
host controller driver does not pass on this information
to the PM core and hence the system suspend process continues.
ret = mmc_suspend_host(host->mmc);
if (ret) {
host->suspended = 0;
if (host->pdata->resume) {
ret = host->pdata->resume(dev, host->slot_id);
The return status from mmc_suspend_host() is overwritten by return
status from host->pdata->resume. So the original return status is lost.
In these cases the MMC core gets to an unexpected state
during resume and multiple issues related to MMC crop up.
1. Host controller driver starts accessing the device registers
before the clocks are enabled which leads to a prefetch abort.
2. A file copy thread which was launched before suspend gets
stuck due to the host not being reclaimed during resume.
To avoid such problems pass on the -EBUSY status to the PM core
from the host controller driver. With this change, MMC core
suspend might still fail but it does not end up making the
system unusable. Suspend gets aborted and the user can try
suspending the system again.
Signed-off-by: Vaibhav Bedia <vaibhav.bedia@ti.com>
Signed-off-by: Hebbar, Gururaja <gururaja.hebbar@ti.com>
Acked-by: Venkatraman S <svenkatr@ti.com>
Signed-off-by: Chris Ball <cjb@laptop.org>
[bwh: Backported to 3.2:
- Adjust context, indentation
- s/dev/\&pdev->dev/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b1e0d8b70f upstream.
The correct syntax for gcc -x is "gcc -x assembler", not
"gcc -xassembler". Even though the latter happens to work, the former
is what is documented in the manual page and thus what gcc wrappers
such as icecream do expect.
This isn't a cosmetic change. The missing space prevents icecream from
recognizing compilation tasks it can't handle, leading to silent kernel
miscompilations.
Besides me, credits go to Michael Matz and Dirk Mueller for
investigating the miscompilation issue and tracking it down to this
incorrect -x parameter syntax.
Signed-off-by: Jean Delvare <jdelvare@suse.de>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: Bernhard Walle <bernhard@bwalle.de>
Cc: Michal Marek <mmarek@suse.cz>
Cc: Ralf Baechle <ralf@linux-mips.org>
Signed-off-by: Michal Marek <mmarek@suse.cz>
[bwh: Backported to 3.2: drop unneeded change to arch/x86/Makefile]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 875de98623 upstream.
"echo -e" is a GNU extension. When cross-compiling the kernel on a
BSD-like operating system (Mac OS X in my case), this doesn't work.
One could install a GNU version of echo, put that in the $PATH before
the system echo and use "/usr/bin/env echo", but the solution with
printf is simpler.
Since it is no disadvantage on Linux, I hope that gets accepted even if
cross-compiling the Linux kernel on another Unix operating system is
quite a rare use case.
Signed-off-by: Bernhard Walle <bernhard@bwalle.de>
Andreas Bießmann <andreas@biessmann.de>
Signed-off-by: Michal Marek <mmarek@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 904753da18 upstream.
Fix a potential multiple spin-unlock -> deadlock scenario during the
overflow check within iscsit_build_sendtargets_resp() as found by
sparse static checking.
Signed-off-by: Christoph Hellwig <hch@lst.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 38b11bae6b upstream.
We've had reports in the past about this specific case, so it's time to
go ahead and explicitly set cache_dynamic_acls=1 for generate_node_acls=1
(TPG demo-mode) operation.
During normal generate_node_acls=0 operation with explicit NodeACLs ->
se_node_acl memory is persistent to the configfs group located at
/sys/kernel/config/target/$TARGETNAME/$TPGT/acls/$INITIATORNAME, so in
the generate_node_acls=1 case we want the reservation logic to reference
existing per initiator IQN se_node_acl memory (not to generate a new
se_node_acl), so go ahead and always set cache_dynamic_acls=1 when
TPG demo-mode is enabled.
Reported-by: Ronnie Sahlberg <ronniesahlberg@gmail.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b32f4c7ed8 upstream.
This patch re-adds the ability to optionally run in buffered FILEIO mode
(eg: w/o O_DSYNC) for device backends in order to once again use the
Linux buffered cache as a write-back storage mechanism.
This logic was originally dropped with mainline v3.5-rc commit:
commit a4dff3043c
Author: Nicholas Bellinger <nab@linux-iscsi.org>
Date: Wed May 30 16:25:41 2012 -0700
target/file: Use O_DSYNC by default for FILEIO backends
This difference with this patch is that fd_create_virtdevice() now
forces the explicit setting of emulate_write_cache=1 when buffered FILEIO
operation has been enabled.
(v2: Switch to FDBD_HAS_BUFFERED_IO_WCE + add more detailed
comment as requested by hch)
Reported-by: Ferry <iscsitmp@bananateam.nl>
Cc: Christoph Hellwig <hch@lst.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5bb61643f6 upstream.
This was meant to be the purpose of the
intel_crtc_wait_for_pending_flips() function which is called whilst
preparing the CRTC for a modeset or before disabling. However, as Ville
Syrjala pointed out, we set the pending flip notification on the old
framebuffer that is no longer attached to the CRTC by the time we come
to flush the pending operations. Instead, we can simply wait on the
pending unpin work to be finished on this CRTC, knowning that the
hardware has therefore finished modifying the registers, before proceeding
with our direct access.
Fixes i-g-t/flip_test on non-pch platforms. pch platforms simply
schedule the flip immediately when the pipe is disabled, leading
to other funny issues.
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
[danvet: Added i-g-t note and cc: stable]
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fe6e1e8d9f upstream.
If applications use flock to protect its write range, generic NFS
will not do read-modify-write cycle at page cache level. Therefore
LD should know how to handle non-sector aligned writes. Otherwise
there will be data corruption.
Signed-off-by: Peng Tao <tao.peng@emc.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to Linux 3.2:
- Adjust context
- s/wdata->pages\.npages/wdata->npages/
- s/header->pnfs_error/wdata->pnfs_error/
- Drop change in missing out_mds exit path]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 303a7ce920 upstream.
Taking hostname from uts namespace if not safe, because this cuold be
performind during umount operation on child reaper death. And in this case
current->nsproxy is NULL already.
Signed-off-by: Stanislav Kinsbursky <skinsbursky@parallels.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9b796d06d5 upstream.
srp_free_req() uses the scsi_cmnd structure contents to unmap
buffers, so we must invoke srp_free_req() before we release
ownership of that structure.
Signed-off-by: Bart Van Assche <bvanassche@acm.org>
Acked-by: David Dillow <dillowda@ornl.gov>
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bea1e22df4 upstream.
Fix a crash in ipoib_mcast_join_task(). (with help from Or Gerlitz)
Commit c8c2afe360 ("IPoIB: Use rtnl lock/unlock when changing device
flags") added a call to rtnl_lock() in ipoib_mcast_join_task(), which
is run from the ipoib_workqueue, and hence the workqueue can't be
flushed from the context of ipoib_stop().
In the current code, ipoib_stop() (which doesn't flush the workqueue)
calls ipoib_mcast_dev_flush(), which goes and deletes all the
multicast entries. This takes place without any synchronization with
a possible running instance of ipoib_mcast_join_task() for the same
ipoib device, leading to a crash due to NULL pointer dereference.
Fix this by making sure that the workqueue is flushed before
ipoib_mcast_dev_flush() is called. To make that possible, we move the
RTNL-lock wrapped code to ipoib_mcast_join_finish().
Signed-off-by: Patrick McHardy <kaber@trash.net>
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bb0a13a134 upstream.
If override size is too big, the module was actually loaded instead of
failing, because retval was not set.
This lead to memory corruption with the use of the freed structs nandsim
and nand_chip.
Signed-off-by: Richard Genoud <richard.genoud@gmail.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 74d83beaa2 upstream.
JFFS2 was designed without thought for OOB bitflips, it seems, but they
can occur and will be reported to JFFS2 via mtd_read_oob()[1]. We don't
want to fail on these transactions, since the data was corrected.
[1] Few drivers report bitflips for OOB-only transactions. With such
drivers, this patch should have no effect.
Signed-off-by: Brian Norris <computersforpeace@gmail.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4d3d688da8 upstream.
Unloading the omap2 nand driver missed to release the memory region which will
result in not being able to request it again if one want to load the driver
later on.
This patch fixes following error when loading omap2 module after unloading:
---8<---
~ $ rmmod omap2
~ $ modprobe omap2
[ 37.420928] omap2-nand: probe of omap2-nand.0 failed with error -16
~ $
--->8---
This error was introduced in 67ce04bf27 which
was the first commit of this driver.
Signed-off-by: Andreas Bießmann <andreas@biessmann.de>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c51803ddba upstream.
We may cause a memory leak when the @types has more then one parser.
Take the `default_mtd_part_types` for example. The default_mtd_part_types has
two parsers now: `cmdlinepart` and `ofpart`.
Assume the following case:
The kernel command line sets the partitions like:
#gpmi-nand:20m(boot),20m(kernel),1g(rootfs),-(user)
But the devicetree file(such as arch/arm/boot/dts/imx28-evk.dts) also sets
the same partitions as the kernel command line does.
In the current code, the partitions parsed out by the `ofpart` will
overwrite the @pparts which has already set by the `cmdlinepart` parser,
and the the partitions parsed out by the `cmdlinepart` is missed.
A memory leak occurs.
So we should break the code as soon as we parse out the partitions,
In actually, this patch makes a priority order between the parsers.
If one parser has already parsed out the partitions successfully,
it's no need to use another parser anymore.
Signed-off-by: Huang Shijie <shijie8@gmail.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d1f55c680e upstream.
Update driver autcpu12-nvram.c so it compiles; map_read32/map_write32
no longer exist in the kernel so the driver is totally broken.
Additionally, map_info name passed to simple_map_init is incorrect.
Signed-off-by: Alexander Shiyan <shc_work@mail.ru>
Acked-by: Arnd Bergmann <arnd@arndb.de>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 824efd3741 upstream.
Commit c039450 (Input: synaptics - handle out of bounds values from the
hardware) caused any hardware reported values over 7167 to be treated as
a wrapped-around negative value. It turns out that some firmware uses
the value 8176 to indicate a finger near the edge of the touchpad whose
actual position cannot be determined. This value now gets treated as
negative, which can cause pointer jumps and broken edge scrolling on
these machines.
I only know of one touchpad which reports negative values, and this
hardware never reports any value lower than -8 (i.e. 8184). Moving the
threshold for treating a value as negative up to 8176 should work fine
then for any hardware we currently know about, and since we're dealing
with unspecified behavior it's probably the best we can do. The special
8176 value is also likely to result in sudden jumps in position, so
let's also clamp this to the maximum specified value for the axis.
BugLink: http://bugs.launchpad.net/bugs/1046512https://bugzilla.kernel.org/show_bug.cgi?id=46371
Signed-off-by: Seth Forshee <seth.forshee@canonical.com>
Reviewed-by: Daniel Kurtz <djkurtz@chromium.org>
Tested-by: Alan Swanson <swanson@ukfsn.org>
Tested-by: Arteom <arutemus@gmail.com>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e1878957b4 upstream.
Correct a direct dereference of I/O memory to use an appropriate I/O
memory access function. Note that the pointer being dereferenced is not
currently tagged with `__iomem` but I plan to correct that for 3.7.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fe04ddf7c2 upstream.
There were reports of users destroying their Fedora installs by a kernel
tarball that replaces the /lib -> /usr/lib symlink. Let's remove the
toplevel directories from the tarball to prevent this from happening.
Reported-by: Andi Kleen <andi@firstfloor.org>
Suggested-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Michal Marek <mmarek@suse.cz>
[bwh: Fold in commit 3ce9e53e78 to avoid
conflicts]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2e3b3b105a upstream.
SI asics store voltage information differently so we
don't have a way to deal with it properly yet.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0c96c65b48 upstream.
The dithering introduced in
commit 3b5c78a35c
Author: Adam Jackson <ajax@redhat.com>
Date: Tue Dec 13 15:41:00 2011 -0800
drm/i915/dp: Dither down to 6bpc if it makes the mode fit
stores the INTEL_MODE_DP_FORCE_6BPC flag in the private_flags of the
adjusted mode, while i9xx_crtc_mode_set() and ironlake_crtc_mode_set() use
the original mode, without the flag, so it would never have any
effect. However, the BPC was clamped by VBT settings, making things work by
coincidence, until that part was removed in
commit 4344b813f1
Author: Daniel Vetter <daniel.vetter@ffwll.ch>
Date: Fri Aug 10 11:10:20 2012 +0200
Use adjusted_mode instead of mode when checking for
INTEL_MODE_DP_FORCE_6BPC to make the flag have effect.
v2: Don't forget to fix this in i9xx_crtc_mode_set() also, pointed out by
Daniel both before and after sending the first patch.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=47621
CC: Adam Jackson <ajax@redhat.com>
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- intel_choose_pipe_bpp_dither() doesn't take a drm_framebuffer argument]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f34f9d186d upstream.
In !CORE_DUMP_USE_REGSET case, if elf_note_info_init fails to allocate
memory for info->fields, it frees already allocated stuff and returns
error to its caller, fill_note_info. Which in turn returns error to its
caller, elf_core_dump. Which jumps to cleanup label and calls
free_note_info, which will happily try to free all info->fields again.
BOOM.
This is the fix.
Signed-off-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Denys Vlasenko <vda.linux@googlemail.com>
Cc: Venu Byravarasu <vbyravarasu@nvidia.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b71fc079b5 upstream.
Code tracking when transaction needs to be committed on fdatasync(2) forgets
to handle a situation when only inode's i_size is changed. Thus in such
situations fdatasync(2) doesn't force transaction with new i_size to disk
and that can result in wrong i_size after a crash.
Fix the issue by updating inode's i_datasync_tid whenever its size is
updated.
Reported-by: Kristian Nielsen <knielsen@knielsen-hq.org>
Signed-off-by: Jan Kara <jack@suse.cz>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6a08f447fa upstream.
ext4_special_inode_operations have their own ifdef CONFIG_EXT4_FS_XATTR
to mask those methods. And ext4_iget also always sets it, so there is
an inconsistency.
Signed-off-by: Bernd Schubert <bernd.schubert@itwm.fraunhofer.de>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c5dd553b9f upstream.
This works around a few glitches in the ST version of the PL011
serial driver when using very high baud rates, as we do in the
Ux500: 3, 3.25, 4 and 4.05 Mbps.
Problem Observed/rootcause:
When using high baud-rates, and the baudrate*8 is getting close to
the provided clock frequency (so a division factor close to 1), when
using bursts of characters (so they are abutted), then it seems as if
there is not enough time to detect the beginning of the start-bit which
is a timing reference for the entire character, and thus the sampling
moment of character bits is moving towards the end of each bit, instead
of the middle.
Fix:
Increase slightly the RX baud rate of the UART above the theoretical
baudrate by 5%. This will definitely give more margin time to the
UART_RX to correctly sample the data at the middle of the bit period.
Also fix the ages old copy-paste error in the very stressed comment,
it's referencing the registers used in the PL010 driver rather than
the PL011 ones.
Signed-off-by: Guillaume Jaunet <guillaume.jaunet@stericsson.com>
Signed-off-by: Christophe Arnal <christophe.arnal@stericsson.com>
Signed-off-by: Matthias Locher <matthias.locher@stericsson.com>
Signed-off-by: Rajanikanth HV <rajanikanth.hv@stericsson.com>
Cc: Bibek Basu <bibek.basu@stericsson.com>
Cc: Par-Gunnar Hjalmdahl <par-gunnar.hjalmdahl@stericsson.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 26e8220adb upstream.
Apparently the same card model has two IDs, so this patch
complements the commit 39aced68d6
adding the missing one.
Signed-off-by: Flavio Leitner <fbl@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust filename]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b655c2c478 upstream.
`s626_enc_insn_config()` is incorrectly dereferencing `insn->data` which
is a pointer to user memory. It should be dereferencing the separate
`data` parameter that points to a copy of the data in kernel memory.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Reviewed-by: H Hartley Sweeten <hsweeten@visionengravers.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f066055a34 upstream.
Proper block swap for inodes with full journaling enabled is
truly non obvious task. In order to be on a safe side let's
explicitly disable it for now.
Signed-off-by: Dmitry Monakhov <dmonakhov@openvz.org>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 03bd8b9b89 upstream.
- Remove usless checks, because it is too late to check that inode != NULL
at the moment it was referenced several times.
- Double lock routines looks very ugly and locking ordering relays on
order of i_ino, but other kernel code rely on order of pointers.
Let's make them simple and clean.
- check that inodes belongs to the same SB as soon as possible.
Signed-off-by: Dmitry Monakhov <dmonakhov@openvz.org>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit adf00b26d1 upstream.
... even if the actual infoframe is smaller than the maximum possible
size.
If we don't write all the 32 DIP data bytes the InfoFrame ECC may not
be correctly calculated in some cases (e.g., when changing the port),
and this will lead to black screens on HDMI monitors. The ECC value is
generated by the hardware.
I don't see how this should break anything since we're writing 0 and
that should be the correct value, so this patch should be safe.
Notice that on IVB and older we actually have 64 bytes available for
VIDEO_DIP_DATA, but only bytes 0-31 actually store infoframe data: the
others are either read-only ECC values or marked as "reserved". On HSW
we only have 32 bytes, and the ECC value is stored on its own separate
read-only register. See BSpec.
This patch fixes bug #46761, which is marked as a regression
introduced by commit 4e89ee174b:
drm/i915: set the DIP port on ibx_write_infoframe
Before commit 4e89 we were just failing to send AVI infoframes when we
needed to change the port, which can lead to black screens in some
cases. After commit 4e89 we started sending infoframes, but with a
possibly wrong ECC value. After this patch I hope we start sending
correct infoframes.
Version 2:
- Improve commit message
- Try to make the code more clear
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=46761
Signed-off-by: Paulo Zanoni <paulo.r.zanoni@intel.com>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@gmail.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2: only two write_infoframe functions to be modified]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9d9740f099 upstream.
On IVB and older, we basically have two registers: the control and the
data register. We write a few consecutitve times to the control
register, and we need these writes to arrive exactly in the specified
order.
Also, when we're changing the data register, we need to guarantee that
anything written to the control register already arrived (since
changing the control register can change where the data register
points to). Also, we need to make sure all the writes to the data
register happen exactly in the specified order, and we also *can't*
read the data register during this process, since reading and/or
writing it will change the place it points to.
So invoke the "better safe than sorry" rule and just be careful and
put barriers everywhere :)
On HSW we still have a control register that we write many times, but
we have many data registers.
Demanded-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Paulo Zanoni <paulo.r.zanoni@intel.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- There are only two write_infoframe functions to be modified
- The other VIDEO_DIP_CTL writes are in entirely different functions]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 80fab3b244 upstream.
When a device with an isochronous endpoint is behind a hub plugged into
the Intel Panther Point xHCI host controller, and the driver submits
multiple frames per URB, the xHCI driver will set the Block Event
Interrupt (BEI) flag on all but the last TD for the URB. This causes
the host controller to place an event on the event ring, but not send an
interrupt. When the last TD for the URB completes, BEI is cleared, and
we get an interrupt for the whole URB.
However, under a Panther Point xHCI host controller, if the parent hub
is unplugged when one or more events from transfers with BEI set are on
the event ring, a port status change event is placed on the event ring,
but no interrupt is generated. This means URBs stop completing, and the
USB device disconnect is not noticed. Something like a USB headset will
cause mplayer to hang when the device is disconnected.
If another transfer is sent (such as running `sudo lsusb -v`), the next
transfer event seems to "unstick" the event ring, the xHCI driver gets
an interrupt, and the disconnect is reported to the USB core.
The fix is not to use the BEI flag under the Panther Point xHCI host.
This will impact power consumption and system responsiveness, because
the xHCI driver will receive an interrupt for every frame in all
isochronous URBs instead of once per URB.
Intel chipset developers confirm that this bug will be hit if the BEI
flag is used on any endpoint, not just ones that are behind a hub.
This patch should be backported to kernels as old as 3.0, that contain
the commit 69e848c209 "Intel xhci: Support
EHCI/xHCI port switching."
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 046b6802c8 upstream.
Currently, ASPM is disabled for all WLAN+BT combo chipsets
when BTCOEX is enabled. This is incorrect since the workaround
is required only for WB195, which is a AR9285+AR3011 combo
solution. Fix this by checking for the HW version when enabling
the workaround.
Signed-off-by: Sujith Manoharan <c_manoha@qca.qualcomm.com>
Tested-by: Paul Stewart <pstew@chromium.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: ath9k_hw_get_btcoex_scheme() function is missing]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fc54ab7295 upstream.
The _OSC method may exist in module level code,
so it must be called after ACPI_FULL_INITIALIZATION
On some new platforms with Zero-Power-Optical-Disk-Drive (ZPODD)
support, this fix is necessary to save power.
Signed-off-by: Lin Ming <ming.m.lin@intel.com>
Tested-by: Aaron Lu <aaron.lu@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 457a73d346 upstream.
In 71c731a: usb: host: xhci: Fix Compliance Mode on SN65LVPE502CP Hardware
when extracting DMI strings (vendor or product_name) to mark them as quirk
we may get NULL pointer in case of non-x86 systems which won't define
CONFIG_DMI. Hence susbsequent strstr() calls crash while driver probing.
So, returning 'false' here in case we get a NULL vendor or product_name.
This is tested with ARM (exynos) system.
This patch should be backported to stable kernels as old as 3.6, that
contain the commit 71c731a296 "usb: host:
xhci: Fix Compliance Mode on SN65LVPE502CP Hardware"
Signed-off-by: Vivek Gautam <gautam.vivek@samsung.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Reported-by: Sebastian Gottschall (DD-WRT) <s.gottschall@dd-wrt.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a6e097dfdf upstream.
The Intel XHCI specification says that after clearing the run/stop bit
the controller may take up to 16ms to halt. We've seen a device take
14ms, which with the current timeout of 10ms causes the kernel to
abort the suspend. Increasing the timeout to the recommended value
fixes the problem.
This patch should be backported to kernels as old as 2.6.37, that
contain the commit 5535b1d5f8 "USB: xHCI:
PCI power management implementation".
Signed-off-by: Michael Spang <spang@chromium.org>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e47f8976d8 upstream.
A quote from SPC-4: "While in the unavailable primary target port
asymmetric access state, the device server shall support those of
the following commands that it supports while in the active/optimized
state: [ ... ] d) SET TARGET PORT GROUPS; [ ... ]". Hence enable
sending STPG to a target port group that is in the unavailable state.
Signed-off-by: Bart Van Assche <bvanassche@acm.org>
Reviewed-by: Mike Christie <michaelc@cs.wisc.edu>
Acked-by: Hannes Reinecke <hare@suse.de>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bc3f02a795 upstream.
John reports:
BUG: soft lockup - CPU#2 stuck for 23s! [kworker/u:8:2202]
[..]
Call Trace:
[<ffffffff8141782a>] scsi_remove_target+0xda/0x1f0
[<ffffffff81421de5>] sas_rphy_remove+0x55/0x60
[<ffffffff81421e01>] sas_rphy_delete+0x11/0x20
[<ffffffff81421e35>] sas_port_delete+0x25/0x160
[<ffffffff814549a3>] mptsas_del_end_device+0x183/0x270
...introduced by commit 3b661a9 "[SCSI] fix hot unplug vs async scan race".
Don't restart lookup of more stargets in the multi-target case, just
arrange to traverse the list once, on the assumption that new targets
are always added at the end. There is no guarantee that the target will
change state in scsi_target_reap() so we can end up spinning if we
restart.
Acked-by: Jack Wang <jack_wang@usish.com>
LKML-Reference: <CAEhu1-6wq1YsNiscGMwP4ud0Q+MrViRzv=kcWCQSBNc8c68N5Q@mail.gmail.com>
Reported-by: John Drescher <drescherjm@gmail.com>
Tested-by: John Drescher <drescherjm@gmail.com>
Signed-off-by: Dan Williams <djbw@fb.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 225c56960f upstream.
The length field in the host config packet is only 16-bit long, so
passing it 0x10000 (64K which is our standard PAGE_SIZE) doesn't
work and result in an empty config from the server.
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Acked-by: Robert Jennings <rcj@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d436de8ce2 upstream.
__scsi_remove_device (e.g. due to dev_loss_tmo) calls
zfcp_scsi_slave_destroy which in turn sends a close LUN FSF request to
the adapter. After 30 seconds without response,
zfcp_erp_timeout_handler kicks the ERP thread failing the close LUN
ERP action. zfcp_erp_wait in zfcp_erp_lun_shutdown_wait and thus
zfcp_scsi_slave_destroy returns and then scsi_device is no longer
valid. Sometime later the response to the close LUN FSF request may
finally come in. However, commit
b62a8d9b45
"[SCSI] zfcp: Use SCSI device data zfcp_scsi_dev instead of zfcp_unit"
introduced a number of attempts to unconditionally access struct
zfcp_scsi_dev through struct scsi_device causing a use-after-free.
This leads to an Oops due to kernel page fault in one of:
zfcp_fsf_abort_fcp_command_handler, zfcp_fsf_open_lun_handler,
zfcp_fsf_close_lun_handler, zfcp_fsf_req_trace,
zfcp_fsf_fcp_handler_common.
Move dereferencing of zfcp private data zfcp_scsi_dev allocated in
scsi_device via scsi_transport_reserve_device after the check for
potentially aborted FSF request and thus no longer valid scsi_device.
Only then assign sdev_to_zfcp(sdev) to the local auto variable struct
zfcp_scsi_dev *zfcp_sdev.
Signed-off-by: Martin Peschke <mpeschke@linux.vnet.ibm.com>
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d99b601b63 upstream.
Upstream commit f3450c7b91
"[SCSI] zfcp: Replace local reference counting with common kref"
accidentally dropped a reference count check before tearing down
zfcp_ports that are potentially in use by zfcp_units.
Even remote ports in use can be removed causing
unreachable garbage objects zfcp_ports with zfcp_units.
Thus units won't come back even after a manual port_rescan.
The kref of zfcp_port->dev.kobj is already used by the driver core.
We cannot re-use it to track the number of zfcp_units.
Re-introduce our own counter for units per port
and check on port_remove.
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Reviewed-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ca579c9f13 upstream.
If list_for_each_entry, etc complete a traversal of the list, the iterator
variable ends up pointing to an address at an offset from the list head,
and not a meaningful structure. Thus this value should not be used after
the end of the iterator. Replace port->adapter->scsi_host by
adapter->scsi_host.
This problem was found using Coccinelle (http://coccinelle.lip6.fr/).
Oversight in upsteam commit of v2.6.37
a1ca48319a
"[SCSI] zfcp: Move ACL/CFDC code to zfcp_cfdc.c"
which merged the content of zfcp_erp_port_access_changed().
Signed-off-by: Julia Lawall <Julia.Lawall@lip6.fr>
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Reviewed-by: Martin Peschke <mpeschke@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cb45214960 upstream.
If the mapping of FCP device bus ID and corresponding subchannel
is modified while the Linux image is suspended, the resume of FCP
devices can fail. During resume, zfcp gets callbacks from cio regarding
the modified subchannels but they can be arbitrarily mixed with the
restore/resume callback. Since the cio callbacks would trigger
adapter recovery, zfcp could wakeup before the resume callback.
Therefore, ignore the cio callbacks regarding subchannels while
being suspended. We can safely do so, since zfcp does not deal itself
with subchannels. For problem determination purposes, we still trace the
ignored callback events.
The following kernel messages could be seen on resume:
kernel: <WWPN>: parent <FCP device bus ID> should not be sleeping
As part of adapter reopen recovery, zfcp performs auto port scanning
which can erroneously try to register new remote ports with
scsi_transport_fc and the device core code complains about the parent
(adapter) still sleeping.
kernel: zfcp.3dff9c: <FCP device bus ID>:\
Setting up the QDIO connection to the FCP adapter failed
<last kernel message repeated 3 more times>
kernel: zfcp.574d43: <FCP device bus ID>:\
ERP cannot recover an error on the FCP device
In such cases, the adapter gave up recovery and remained blocked along
with its child objects: remote ports and LUNs/scsi devices. Even the
adapter shutdown as part of giving up recovery failed because the ccw
device state remained disconnected. Later, the corresponding remote
ports ran into dev_loss_tmo. As a result, the LUNs were erroneously
not available again after resume.
Even a manually triggered adapter recovery (e.g. sysfs attribute
failed, or device offline/online via sysfs) could not recover the
adapter due to the remaining disconnected state of the corresponding
ccw device.
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 01e60527f0 upstream.
The pl vector has scount elements, i.e. pl[scount-1] is the last valid
element. For maximum sized requests, payload->counter == scount after
the last loop iteration. Therefore, do bounds checking first (with
boolean shortcut) to not access the invalid element pl[scount].
Do not trust the maximum sbale->scount value from the HBA
but ensure we won't access the pl vector out of our allocated bounds.
While at it, clean up scoping and prevent unnecessary memset.
Minor fix for 86a9668a8d
"[SCSI] zfcp: support for hardware data router"
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Reviewed-by: Martin Peschke <mpeschke@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0100998dbf upstream.
Duplicate fssrh_2 from a54ca0f62f
"[SCSI] zfcp: Redesign of the debug tracing for HBA records."
complicates distinction of generic status read response from
local link up.
Duplicate fsscth1 from 2c55b750a8
"[SCSI] zfcp: Redesign of the debug tracing for SAN records."
complicates distinction of good common transport response from
invalid port handle.
Signed-off-by: Steffen Maier <maier@linux.vnet.ibm.com>
Reviewed-by: Martin Peschke <mpeschke@linux.vnet.ibm.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a10d206ef1 upstream.
Each grace period is supposed to have at least one callback waiting
for that grace period to complete. However, if CONFIG_NO_HZ=n, an
extra callback-free grace period is no big problem -- it will chew up
a tiny bit of CPU time, but it will complete normally. In contrast,
CONFIG_NO_HZ=y kernels have the potential for all the CPUs to go to
sleep indefinitely, in turn indefinitely delaying completion of the
callback-free grace period. Given that nothing is waiting on this grace
period, this is also not a problem.
That is, unless RCU CPU stall warnings are also enabled, as they are
in recent kernels. In this case, if a CPU wakes up after at least one
minute of inactivity, an RCU CPU stall warning will result. The reason
that no one noticed until quite recently is that most systems have enough
OS noise that they will never remain absolutely idle for a full minute.
But there are some embedded systems with cut-down userspace configurations
that consistently get into this situation.
All this begs the question of exactly how a callback-free grace period
gets started in the first place. This can happen due to the fact that
CPUs do not necessarily agree on which grace period is in progress.
If a CPU still believes that the grace period that just completed is
still ongoing, it will believe that it has callbacks that need to wait for
another grace period, never mind the fact that the grace period that they
were waiting for just completed. This CPU can therefore erroneously
decide to start a new grace period. Note that this can happen in
TREE_RCU and TREE_PREEMPT_RCU even on a single-CPU system: Deadlock
considerations mean that the CPU that detected the end of the grace
period is not necessarily officially informed of this fact for some time.
Once this CPU notices that the earlier grace period completed, it will
invoke its callbacks. It then won't have any callbacks left. If no
other CPU has any callbacks, we now have a callback-free grace period.
This commit therefore makes CPUs check more carefully before starting a
new grace period. This new check relies on an array of tail pointers
into each CPU's list of callbacks. If the CPU is up to date on which
grace periods have completed, it checks to see if any callbacks follow
the RCU_DONE_TAIL segment, otherwise it checks to see if any callbacks
follow the RCU_WAIT_TAIL segment. The reason that this works is that
the RCU_WAIT_TAIL segment will be promoted to the RCU_DONE_TAIL segment
as soon as the CPU is officially notified that the old grace period
has ended.
This change is to cpu_needs_another_gp(), which is called in a number
of places. The only one that really matters is in rcu_start_gp(), where
the root rcu_node structure's ->lock is held, which prevents any
other CPU from starting or completing a grace period, so that the
comparison that determines whether the CPU is missing the completion
of a grace period is stable.
Reported-by: Becky Bruce <bgillbruce@gmail.com>
Reported-by: Subodh Nijsure <snijsure@grid-net.com>
Reported-by: Paul Walmsley <paul@pwsan.com>
Signed-off-by: Paul E. McKenney <paul.mckenney@linaro.org>
Signed-off-by: Paul E. McKenney <paulmck@linux.vnet.ibm.com>
Tested-by: Paul Walmsley <paul@pwsan.com> # OMAP3730, OMAP4430
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f25590f39d upstream.
This patch adds a missing iscsi_reject->ffffffff assignment within
iscsit_send_reject() code to properly follow RFC-3720 Section 10.17
Bytes 16 -> 19 for the PDU format definition of ISCSI_OP_REJECT.
We've not seen any initiators care about this bytes in practice, but
as Ronnie reported this was causing trouble with wireshark packet
decoding lets go ahead and fix this up now.
Reported-by: Ronnie Sahlberg <ronniesahlberg@gmail.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c638eb2872 upstream.
The three Pantech devices UML190 (106c:3716), UML290 (106c:3718) and
P4200 (106c:3721) all use the same subclasses to identify vendor
specific functions. Replace the existing device specific entries
with generic vendor matching, adding support for the P4200.
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Cc: Thomas Schäfer <tschaefer@t-online.de>
Acked-by: Dan Williams <dcbw@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c8cad4c89e upstream.
When `do_cmd_ioctl()` allocates memory for the kernel copy of a channel
list, it frees any previously allocated channel list in
`async->cmd.chanlist` and replaces it with the new one. However, if the
device is ever removed (or "detached") the cleanup code in
`cleanup_device()` in "drivers.c" does not free this memory so it is
lost.
A sensible place to free the kernel copy of the channel list is in
`do_become_nonbusy()` as at that point the comedi asynchronous command
associated with the channel list is no longer valid. Free the channel
list in `do_become_nonbusy()` instead of `do_cmd_ioctl()` and clear the
pointer to prevent it being freed more than once.
Note that `cleanup_device()` could be called at an inappropriate time
while the comedi device is open, but that's a separate bug not related
to this this patch.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 00d4e7362e upstream.
In ext4_nonda_switch(), if the file system is getting full we used to
call writeback_inodes_sb_if_idle(). The problem is that we can be
holding i_mutex already, and this causes a potential deadlock when
writeback_inodes_sb_if_idle() when it tries to take s_umount. (See
lockdep output below).
As it turns out we don't need need to hold s_umount; the fact that we
are in the middle of the write(2) system call will keep the superblock
pinned. Unfortunately writeback_inodes_sb() checks to make sure
s_umount is taken, and the VFS uses a different mechanism for making
sure the file system doesn't get unmounted out from under us. The
simplest way of dealing with this is to just simply grab s_umount
using a trylock, and skip kicking the writeback flusher thread in the
very unlikely case that we can't take a read lock on s_umount without
blocking.
Also, we now check the cirteria for kicking the writeback thread
before we decide to whether to fall back to non-delayed writeback, so
if there are any outstanding delayed allocation writes, we try to get
them resolved as soon as possible.
[ INFO: possible circular locking dependency detected ]
3.6.0-rc1-00042-gce894ca #367 Not tainted
-------------------------------------------------------
dd/8298 is trying to acquire lock:
(&type->s_umount_key#18){++++..}, at: [<c02277d4>] writeback_inodes_sb_if_idle+0x28/0x46
but task is already holding lock:
(&sb->s_type->i_mutex_key#8){+.+...}, at: [<c01ddcce>] generic_file_aio_write+0x5f/0xd3
which lock already depends on the new lock.
2 locks held by dd/8298:
#0: (sb_writers#2){.+.+.+}, at: [<c01ddcc5>] generic_file_aio_write+0x56/0xd3
#1: (&sb->s_type->i_mutex_key#8){+.+...}, at: [<c01ddcce>] generic_file_aio_write+0x5f/0xd3
stack backtrace:
Pid: 8298, comm: dd Not tainted 3.6.0-rc1-00042-gce894ca #367
Call Trace:
[<c015b79c>] ? console_unlock+0x345/0x372
[<c06d62a1>] print_circular_bug+0x190/0x19d
[<c019906c>] __lock_acquire+0x86d/0xb6c
[<c01999db>] ? mark_held_locks+0x5c/0x7b
[<c0199724>] lock_acquire+0x66/0xb9
[<c02277d4>] ? writeback_inodes_sb_if_idle+0x28/0x46
[<c06db935>] down_read+0x28/0x58
[<c02277d4>] ? writeback_inodes_sb_if_idle+0x28/0x46
[<c02277d4>] writeback_inodes_sb_if_idle+0x28/0x46
[<c026f3b2>] ext4_nonda_switch+0xe1/0xf4
[<c0271ece>] ext4_da_write_begin+0x27/0x193
[<c01dcdb0>] generic_file_buffered_write+0xc8/0x1bb
[<c01ddc47>] __generic_file_aio_write+0x1dd/0x205
[<c01ddce7>] generic_file_aio_write+0x78/0xd3
[<c026d336>] ext4_file_write+0x480/0x4a6
[<c0198c1d>] ? __lock_acquire+0x41e/0xb6c
[<c0180944>] ? sched_clock_cpu+0x11a/0x13e
[<c01967e9>] ? trace_hardirqs_off+0xb/0xd
[<c018099f>] ? local_clock+0x37/0x4e
[<c0209f2c>] do_sync_write+0x67/0x9d
[<c0209ec5>] ? wait_on_retry_sync_kiocb+0x44/0x44
[<c020a7b9>] vfs_write+0x7b/0xe6
[<c020a9a6>] sys_write+0x3b/0x64
[<c06dd4bd>] syscall_call+0x7/0xb
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a519fc7a70 upstream.
Instead of doing a shutdown() call, we need to do an actual close().
Ditto if/when the server is sending us junk RPC headers.
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Tested-by: Simon Kirby <sim@hostway.ca>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5d06e3df28 upstream.
`parse_insn()` is dereferencing the user-space pointer `insn->data`
directly when handling the `INSN_INTTRIG` comedi instruction. It
shouldn't be using `insn->data` at all; it should be using the separate
`data` pointer passed to the function. Fix it.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ee66401bb9 upstream.
Foxconn devices has a vendor specific class of device, we will match them
differently now.
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1965f66e7d upstream.
For bridges with "secondary > subordinate", i.e., invalid bus number
apertures, we don't enumerate anything behind the bridge unless the
user specified "pci=assign-busses".
This patch makes us automatically try to reassign the downstream bus
numbers in this case (just for that bridge, not for all bridges as
"pci=assign-busses" does).
We don't discover all the devices on the Intel DP43BF motherboard
without this change (or "pci=assign-busses") because its BIOS configures
a bridge as:
pci 0000:00:1e.0: PCI bridge to [bus 20-08] (subtractive decode)
[bhelgaas: changelog, change message to dev_info]
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=18412
Bugzilla: https://bugzilla.redhat.com/show_bug.cgi?id=625754
Reported-by: Brian C. Huffman <bhuffman@graze.net>
Reported-by: VL <vl.homutov@gmail.com>
Tested-by: VL <vl.homutov@gmail.com>
Signed-off-by: Yinghai Lu <yinghai@kernel.org>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3aa6249759 upstream.
Currently, when try_to_grab_pending() grabs a delayed work item, it
leaves its linked work items alone on the delayed_works. The linked
work items are always NO_COLOR and will cause future
cwq_activate_first_delayed() increase cwq->nr_active incorrectly, and
may cause the whole cwq to stall. For example,
state: cwq->max_active = 1, cwq->nr_active = 1
one work in cwq->pool, many in cwq->delayed_works.
step1: try_to_grab_pending() removes a work item from delayed_works
but leaves its NO_COLOR linked work items on it.
step2: Later on, cwq_activate_first_delayed() activates the linked
work item increasing ->nr_active.
step3: cwq->nr_active = 1, but all activated work items of the cwq are
NO_COLOR. When they finish, cwq->nr_active will not be
decreased due to NO_COLOR, and no further work items will be
activated from cwq->delayed_works. the cwq stalls.
Fix it by ensuring the target work item is activated before stealing
PENDING in try_to_grab_pending(). This ensures that all the linked
work items are activated without incorrectly bumping cwq->nr_active.
tj: Updated comment and description.
Signed-off-by: Lai Jiangshan <laijs@cn.fujitsu.com>
Signed-off-by: Tejun Heo <tj@kernel.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2e12bc29fc upstream.
domain_update_iommu_coherency() currently defaults to setting domains
as coherent when the domain is not attached to any iommus. This
allows for a window in domain_context_mapping_one() where such a
domain can update context entries non-coherently, and only after
update the domain capability to clear iommu_coherency.
This can be seen using KVM device assignment on VT-d systems that
do not support coherency in the ecap register. When a device is
added to a guest, a domain is created (iommu_coherency = 0), the
device is attached, and ranges are mapped. If we then hot unplug
the device, the coherency is updated and set to the default (1)
since no iommus are attached to the domain. A subsequent attach
of a device makes use of the same dmar domain (now marked coherent)
updates context entries with coherency enabled, and only disables
coherency as the last step in the process.
To fix this, switch domain_update_iommu_coherency() to use the
safer, non-coherent default for domains not attached to iommus.
Signed-off-by: Alex Williamson <alex.williamson@redhat.com>
Tested-by: Donald Dutile <ddutile@redhat.com>
Acked-by: Donald Dutile <ddutile@redhat.com>
Acked-by: Chris Wright <chrisw@sous-sol.org>
Signed-off-by: Joerg Roedel <joerg.roedel@amd.com>
[bwh: Backported to 3.2: dmar_domain::iommu_bmp is a single unsigned long
not an array, so add &]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit feadf7c0a1 upstream.
The EEH core is talking with the PCI device driver to determine the
action (purely reset, or PCI device removal). During the period, the
driver might be unloaded and in turn causes kernel crash as follows:
EEH: Detected PCI bus error on PHB#4-PE#10000
EEH: This PCI device has failed 3 times in the last hour
lpfc 0004:01:00.0: 0:2710 PCI channel disable preparing for reset
Unable to handle kernel paging request for data at address 0x00000490
Faulting instruction address: 0xd00000000e682c90
cpu 0x1: Vector: 300 (Data Access) at [c000000fc75ffa20]
pc: d00000000e682c90: .lpfc_io_error_detected+0x30/0x240 [lpfc]
lr: d00000000e682c8c: .lpfc_io_error_detected+0x2c/0x240 [lpfc]
sp: c000000fc75ffca0
msr: 8000000000009032
dar: 490
dsisr: 40000000
current = 0xc000000fc79b88b0
paca = 0xc00000000edb0380 softe: 0 irq_happened: 0x00
pid = 3386, comm = eehd
enter ? for help
[c000000fc75ffca0] c000000fc75ffd30 (unreliable)
[c000000fc75ffd30] c00000000004fd3c .eeh_report_error+0x7c/0xf0
[c000000fc75ffdc0] c00000000004ee00 .eeh_pe_dev_traverse+0xa0/0x180
[c000000fc75ffe70] c00000000004ffd8 .eeh_handle_event+0x68/0x300
[c000000fc75fff00] c0000000000503a0 .eeh_event_handler+0x130/0x1a0
[c000000fc75fff90] c000000000020138 .kernel_thread+0x54/0x70
1:mon>
The patch increases the reference of the corresponding driver modules
while EEH core does the negotiation with PCI device driver so that the
corresponding driver modules can't be unloaded during the period and
we're safe to refer the callbacks.
Reported-by: Alexey Kardashevskiy <aik@ozlabs.ru>
Signed-off-by: Gavin Shan <shangw@linux.vnet.ibm.com>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
[bwh: Backported to 3.2:
- Adjust context
- Reporting functions return int (success = 0), not void * (success = NULL)
- Assume that the 'dev' arguments are non-null]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 37bb7899ca upstream.
This patch fixes error cases within target_core_init_configfs() to
properly set ret = -ENOMEM before jumping to the out_global exception
path.
This was originally discovered with the following Coccinelle semantic
match information:
Convert a nonnegative error return code to a negative one, as returned
elsewhere in the function. A simplified version of the semantic match
that finds this problem is as follows: (http://coccinelle.lip6.fr/)
// <smpl>
(
if@p1 (\(ret < 0\|ret != 0\))
{ ... return ret; }
|
ret@p1 = 0
)
... when != ret = e1
when != &ret
*if(...)
{
... when != ret = e2
when forall
return ret;
}
// </smpl>
Signed-off-by: Peter Senna Tschudin <peter.senna@gmail.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 40fe4f8967 upstream.
softsynth_read() reads a character at a time from the init string;
when it finds the null terminator it sets the initialized flag but
then repeats the last character.
Additionally, if the read() buffer is not big enough for the init
string, the next read() will start reading from the beginning again.
So the caller may never progress to reading anything else.
Replace the simple initialized flag with the current position in
the init string, carried over between calls. Switch to reading
real data once this reaches the null terminator.
(This assumes that the length of the init string can't change, which
seems to be the case. Really, the string and position belong together
in a per-file private struct.)
Tested-by: Samuel Thibault <sthibault@debian.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 4b961180ef upstream.
ite_dev::rdev is currently initialised in ite_probe() after
rc_register_device() returns. If a newly registered device is opened
quickly enough, we may enable interrupts and try to use ite_dev::rdev
before it has been initialised. Move it up to the earliest point we
can, right after calling rc_allocate_device().
Reported-and-tested-by: YunQiang Su <wzssyqa@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Mauro Carvalho Chehab <mchehab@redhat.com>
commit 21e89afd32 upstream.
It turns out Smart Array logical drives do not support target
reset and when the target reset fails, the logical drive will
be taken off line. Symptoms look like this:
hpsa 0000:03:00.0: Abort request on C1:B0:T0:L0
hpsa 0000:03:00.0: resetting device 1:0:0:0
hpsa 0000:03:00.0: cp ffff880037c56000 is reported invalid (probably means target device no longer present)
hpsa 0000:03:00.0: resetting device failed.
sd 1:0:0:0: Device offlined - not ready after error recovery
sd 1:0:0:0: rejecting I/O to offline device
EXT3-fs error (device sdb1): read_block_bitmap:
LUN reset is supported though, and is what we should be using.
Target reset is also disruptive in shared SAS situations,
for example, an external MSA1210m which does support target
reset attached to Smart Arrays in multiple hosts -- a target
reset from one host is disruptive to other hosts as all LUNs
on the target will be reset and will abort all outstanding i/os
back to all the attached hosts. So we should use LUN reset,
not target reset.
Tested this with Smart Array logical drives and with tape drives.
Not sure how this bug survived since 2009, except it must be very
rare for a Smart Array to require more than 30s to complete a request.
Signed-off-by: Stephen M. Cameron <scameron@beardog.cce.hp.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6e4468b9a0 upstream.
The patch is used to cancel command when the command isn't
acknowledged and a timeout occurs.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b92cc66c04 upstream.
Software have to abort command ring and cancel command
when a command is failed or hang. Otherwise, the command
ring will hang up and can't handle the others. An example
of a command that may hang is the Address Device Command,
because waiting for a SET_ADDRESS request to be acknowledged
by a USB device is outside of the xHC's ability to control.
To cancel a command, software will initialize a command
descriptor for the cancel command, and add it into a
cancel_cmd_list of xhci.
Sarah: Fixed missing newline on "Have the command ring been stopped?"
debugging statement.
This patch should be backported to kernels as old as 3.0, that contain
the commit 7ed603ecf8 "xhci: Add an
assertion to check for virt_dev=0 bug." That commit papers over a NULL
pointer dereference, and this patch fixes the underlying issue that
caused the NULL pointer dereference.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c181bc5b5d upstream.
Adding cmd_ring_state for command ring. It helps to verify
the current command ring state for controlling the command
ring operations.
This patch should be backported to kernels as old as 3.0. The commit
7ed603ecf8 "xhci: Add an assertion to
check for virt_dev=0 bug." papers over the NULL pointer dereference that
I now believe is related to a timed out Set Address command. This (and
the four patches that follow it) contain the real fix that also allows
VIA USB 3.0 hubs to consistently re-enumerate during the plug/unplug
stress tests.
Signed-off-by: Elric Fu <elricfu1@gmail.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Tested-by: Miroslav Sabljic <miroslav.sabljic@avl.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5af98bb06d upstream.
Eric Fu reports a problem with his VIA host controller fetching a zeroed
event ring pointer on resume from suspend. The host should have been
halted, but we can't be sure because that code ignores the return value
from xhci_halt(). Print a warning when the host controller refuses to
halt within XHCI_MAX_HALT_USEC (currently 16 seconds).
(Update: it turns out that the VIA host controller is reporting a halted
state when it fetches the zeroed event ring pointer. However, we still
need this warning for other host controllers.)
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 947ca1856a upstream.
DEADLOCK will be report while running a kernel with NUMA and LOCKDEP enabled,
the process of this fake report is:
kmem_cache_free() //free obj in cachep
-> cache_free_alien() //acquire cachep's l3 alien lock
-> __drain_alien_cache()
-> free_block()
-> slab_destroy()
-> kmem_cache_free() //free slab in cachep->slabp_cache
-> cache_free_alien() //acquire cachep->slabp_cache's l3 alien lock
Since the cachep and cachep->slabp_cache's l3 alien are in the same lock class,
fake report generated.
This should not happen since we already have init_lock_keys() which will
reassign the lock class for both l3 list and l3 alien.
However, init_lock_keys() was invoked at a wrong position which is before we
invoke enable_cpucache() on each cache.
Since until set slab_state to be FULL, we won't invoke enable_cpucache()
on caches to build their l3 alien while creating them, so although we invoked
init_lock_keys(), the l3 alien lock class won't change since we don't have
them until invoked enable_cpucache() later.
This patch will invoke init_lock_keys() after we done enable_cpucache()
instead of before to avoid the fake DEADLOCK report.
Michael traced the problem back to a commit in release 3.0.0:
commit 30765b92ad
Author: Peter Zijlstra <peterz@infradead.org>
Date: Thu Jul 28 23:22:56 2011 +0200
slab, lockdep: Annotate the locks before using them
Fernando found we hit the regular OFF_SLAB 'recursion' before we
annotate the locks, cure this.
The relevant portion of the stack-trace:
> [ 0.000000] [<c085e24f>] rt_spin_lock+0x50/0x56
> [ 0.000000] [<c04fb406>] __cache_free+0x43/0xc3
> [ 0.000000] [<c04fb23f>] kmem_cache_free+0x6c/0xdc
> [ 0.000000] [<c04fb2fe>] slab_destroy+0x4f/0x53
> [ 0.000000] [<c04fb396>] free_block+0x94/0xc1
> [ 0.000000] [<c04fc551>] do_tune_cpucache+0x10b/0x2bb
> [ 0.000000] [<c04fc8dc>] enable_cpucache+0x7b/0xa7
> [ 0.000000] [<c0bd9d3c>] kmem_cache_init_late+0x1f/0x61
> [ 0.000000] [<c0bba687>] start_kernel+0x24c/0x363
> [ 0.000000] [<c0bba0ba>] i386_start_kernel+0xa9/0xaf
Reported-by: Fernando Lopez-Lezcano <nando@ccrma.Stanford.EDU>
Acked-by: Pekka Enberg <penberg@kernel.org>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1311888176.2617.379.camel@laptop
Signed-off-by: Ingo Molnar <mingo@elte.hu>
The commit moved init_lock_keys() before we build up the alien, so we
failed to reclass it.
Acked-by: Christoph Lameter <cl@linux.com>
Tested-by: Paul E. McKenney <paulmck@linux.vnet.ibm.com>
Signed-off-by: Michael Wang <wangyun@linux.vnet.ibm.com>
Signed-off-by: Pekka Enberg <penberg@kernel.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6bb22fea25 upstream.
Linux native exit codes are 8-bit unsigned values. exit(-1) results
in an exit code of 255, which is usually reserved for shells reporting
'command not found'. Use the portable value EXIT_FAILURE. (Not that
this matters much for a daemon.)
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: K. Y. Srinivasan <kys@microsoft.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: drop changes to exit() calls not in this version]
commit 7083909023 upstream.
Some of the EFI variable attributes are missing from print out from
/sys/firmware/efi/vars/*/attributes. This patch adds those in. It also
updates code to use pre-defined constants for masking current value
of attributes.
Signed-off-by: Khalid Aziz <khalid.aziz@hp.com>
Reviewed-by: Kees Cook <keescook@chromium.org>
Acked-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 193819cf2e upstream.
Without this patch, these PEB are not scrubbed until we put data in them.
Bitflip can accumulate latter and we can loose the EC header (but VID header
should be intact and allow to recover data).
Signed-off-by: Matthieu Castet <matthieu.castet@parrot.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit abb3e01103 upstream.
Currently UBI fails in autoresize when it is in R/O mode (e.g., because the
underlying MTD device is R/O). This patch fixes the issue - we just skip
autoresize and print a warning.
Reported-by: Pali Rohár <pali.rohar@gmail.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 88ed2a6061 upstream.
Uplink (TX) network data will go through gsm_dlci_data_output_framed
there is a bug where if memory allocation fails, the skb which
has already been pulled off the list will be lost.
In addition TX skbs were being processed in LIFO order
Fixed the memory leak, and changed to FIFO order processing
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Tested-by: Kappel, LaurentX <laurentx.kappel@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 329e56780e upstream.
Drivers are supposed to use the dev_* versions of the kfree_skb
interfaces. In a couple of cases we were called with IRQs
disabled as well which kfree_skb() does not expect.
Replaced kfree_skb calls w/ dev_kfree_skb and dev_kfree_skb_any
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Tested-by: Yin, Fengwei <fengwei.yin@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b4338e1efc upstream.
gsm_data_kick was recently modified to allow messages on the
tx queue bound for DLCI0 to flow even during FCOFF conditions.
Unfortunately we introduced a bug discovered by code inspection
where subsequent list traversers can access freed memory if
the DLCI0 messages were not all at the head of the list.
Replaced singly linked tx list w/ a list_head and used
provided interfaces for traversing and deleting members.
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Tested-by: Yin, Fengwei <fengwei.yin@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5e44708f75 upstream.
There were some locking holes in the management of the MUX's
message queue for 2 code paths:
1) gsmld_write_wakeup
2) receipt of CMD_FCON flow-control message
In both cases gsm_data_kick is called w/o locking so it can collide
with other other instances of gsm_data_kick (pulling messages tx_tail)
or potentially other instances of __gsm_data_queu (adding messages to tx_head)
Changed to take the tx_lock in these 2 cases
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Tested-by: Yin, Fengwei <fengwei.yin@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 10c6c383e4 upstream.
The design of uplink flow control in the mux driver is
that for constipated channels data will backup into the
per-channel fifos, and any messages that make it to the
outbound message queue will still go out.
Code was added to also stop messages that were in the outbound
queue but this requires filtering through all the messages on the
queue for stopped dlcis and changes some of the mux logic unneccessarily.
The message fiiltering was removed to be in line w/ the original design
as the message filtering does not provide any solution.
Extra debug messages used during investigation were also removed.
Signed-off-by: samix.lebsir <samix.lebsir@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c01af4fec2 upstream.
- Correcting handling of FCon/FCoff in order to respect 27.010 spec
- Consider FCon/off will overide all dlci flow control except for
dlci0 as we must be able to send control frames.
- Dlci constipated handling according to FC, RTC and RTR values.
- Modifying gsm_dlci_data_kick and gsm_dlci_data_sweep according
to dlci constipated value
Signed-off-by: Frederic Berat <fredericx.berat@intel.com>
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 192b6041e7 upstream.
gsm_dlci_data_kick will not call any output function if tx_bytes > THRESH_LO
furthermore it will call the output function only once if tx_bytes == 0
If the size of the IP writes are on the order of THRESH_LO
we can get into a situation where skbs accumulate on the outbound list
being starved for events to call the output function.
gsm_dlci_data_kick now calls the sweep function when tx_bytes==0
Signed-off-by: Russ Gorby <russ.gorby@intel.com>
Tested-by: Kappel, LaurentX <laurentx.kappel@intel.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7e8ac7b23b upstream.
In 3GPP27.010 5.8.1, it defined:
The TE multiplexer initiates the establishment of the multiplexer control channel by sending a SABM frame on DLCI 0 using the procedures of clause 5.4.1.
Once the multiplexer channel is established other DLCs may be established using the procedures of clause 5.4.1.
This patch implement 5.8.1 in MUX level, it make sure DLC0 is the first channel to be setup.
[or for those not familiar with the specification: it was possible to try
and open a data connection while the control channel was not yet fully
open, which is a spec violation and confuses some modems]
Signed-off-by: xiaojin <jin.xiao@intel.com>
Tested-by: Yin, Fengwei <fengwei.yin@intel.com>
[tweaked the order we check things and error code]
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e9490e93c1 upstream.
Change the BUG_ON to WARN_ON and return in case of tty->read_buf==NULL. We want to track a
couple of long standing reports of this but at the same time we can avoid killing the box.
Signed-off-by: Stanislav Kozina <skozina@redhat.com>
Signed-off-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ee8b593aff upstream.
If a user provides a buffer larger than a tty->write_buf chunk and
passes '\r' at the end of the buffer, we touch an out-of-bound memory.
Add a check there to prevent this.
Signed-off-by: Jiri Slaby <jslaby@suse.cz>
Cc: Samo Pogacnik <samo_pogacnik@t-2.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 959d1af8cf upstream.
WORK_STRUCT_PENDING is used to claim ownership of a work item and
process_one_work() releases it before starting execution. When
someone else grabs PENDING, all pre-release updates to the work item
should be visible and all updates made by the new owner should happen
afterwards.
Grabbing PENDING uses test_and_set_bit() and thus has a full barrier;
however, clearing doesn't have a matching wmb. Given the preceding
spin_unlock and use of clear_bit, I don't believe this can be a
problem on an actual machine and there hasn't been any related report
but it still is theretically possible for clear_pending to permeate
upwards and happen before work->entry update.
Add an explicit smp_wmb() before work_clear_pending().
Signed-off-by: Tejun Heo <tj@kernel.org>
Cc: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7bb9c75436 upstream.
The code responsible for reading the version of the mirror bbt was
incorrectly using the descriptor of the main bbt.
Pass the mirror bbt descriptor to 'scan_read_raw' when reading the
version of the mirror bbt.
Signed-off-by: Shmulik Ladkani <shmulik.ladkani@gmail.com>
Acked-by: Sebastian Andrzej Siewior <bigeasy@linutronix.de>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6d70a74ffd upstream.
The oem parameter image embedded in the efi variable is at an offset
from the start of the variable. However, in the failure path we try to
free the 'orom' pointer which is only valid when the paramaters are
being read from the legacy option-rom space.
Since failure to load the oem parameters is unlikely and we keep the
memory around in the success case just defer all de-allocation to devm.
Reported-by: Don Morris <don.morris@hp.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit cf9ecf4b63 ]
On the earliest TSO capable devices, TSO was accomplished through
firmware. The TSO cannot coexist with ASF management firmware though.
The tg3 driver determines whether or not ASF is enabled by calling
tg3_get_eeprom_hw_cfg(), which checks a particular bit of NIC memory.
Commit dabc5c670d, entitled "tg3: Move
TSO_CAPABLE assignment", accidentally moved the code that determines
TSO capabilities earlier than the call to tg3_get_eeprom_hw_cfg(). As a
consequence, the driver was attempting to determine TSO capabilities
before it had all the data it needed to make the decision.
This patch fixes the problem by revisiting and reevaluating the decision
after tg3_get_eeprom_hw_cfg() is called.
Signed-off-by: Matt Carlson <mcarlson@broadcom.com>
Signed-off-by: Michael Chan <mchan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 8babe8cc65 ]
In order for the network layer to see that AoE requires
no checksumming in a generic way, the packets must be
marked as requiring no checksum, so we make this requirement
explicit with the assertion.
Signed-off-by: Ed Cashin <ecashin@coraid.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit c0d680e577 ]
A change in a series of VLAN-related changes appears to have
inadvertently disabled the use of the scatter gather feature of
network cards for transmission of non-IP ethernet protocols like ATA
over Ethernet (AoE). Below is a reference to the commit that
introduces a "harmonize_features" function that turns off scatter
gather when the NIC does not support hardware checksumming for the
ethernet protocol of an sk buff.
commit f01a5236bd
Author: Jesse Gross <jesse@nicira.com>
Date: Sun Jan 9 06:23:31 2011 +0000
net offloading: Generalize netif_get_vlan_features().
The can_checksum_protocol function is not equipped to consider a
protocol that does not require checksumming. Calling it for a
protocol that requires no checksum is inappropriate.
The patch below has harmonize_features call can_checksum_protocol when
the protocol needs a checksum, so that the network layer is not forced
to perform unnecessary skb linearization on the transmission of AoE
packets. Unnecessary linearization results in decreased performance
and increased memory pressure, as reported here:
http://www.spinics.net/lists/linux-mm/msg15184.html
The problem has probably not been widely experienced yet, because
only recently has the kernel.org-distributed aoe driver acquired the
ability to use payloads of over a page in size, with the patchset
recently included in the mm tree:
https://lkml.org/lkml/2012/8/28/140
The coraid.com-distributed aoe driver already could use payloads of
greater than a page in size, but its users generally do not use the
newest kernels.
Signed-off-by: Ed Cashin <ecashin@coraid.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit c0cc88a762 ]
While investigating l2tp bug, I hit a bug in eth_type_trans(),
because not enough bytes were pulled in skb head.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 96af69ea2a ]
mip6_mh_filter() should not modify its input, or else its caller
would need to recompute ipv6_hdr() if skb->head is reallocated.
Use skb_header_pointer() instead of pskb_may_pull()
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 1b05c4b50e ]
icmpv6_filter() should not modify its input, or else its caller
would need to recompute ipv6_hdr() if skb->head is reallocated.
Use skb_header_pointer() instead of pskb_may_pull() and
change the prototype to make clear both sk and skb are const.
Also, if icmpv6 header cannot be found, do not deliver the packet,
as we do in IPv4.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit ab43ed8b74 ]
icmp_filter() should not modify its input, or else its caller
would need to recompute ip_hdr() if skb->head is reallocated.
Use skb_header_pointer() instead of pskb_may_pull() and
change the prototype to make clear both sk and skb are const.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 3e10986d1d ]
Its possible to use RAW sockets to get a crash in
tcp_set_keepalive() / sk_reset_timer()
Fix is to make sure socket is a SOCK_STREAM one.
Reported-by: Dave Jones <davej@redhat.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 6862234238 ]
In the current rxhash calculation function, while the
sorting of the ports/addrs is coherent (you get the
same rxhash for packets sharing the same 4-tuple, in
both directions), ports and addrs are sorted
independently. This implies packets from a connection
between the same addresses but crossed ports hash to
the same rxhash.
For example, traffic between A=S:l and B=L:s is hashed
(in both directions) from {L, S, {s, l}}. The same
rxhash is obtained for packets between C=S:s and D=L:l.
This patch ensures that you either swap both addrs and ports,
or you swap none. Traffic between A and B, and traffic
between C and D, get their rxhash from different sources
({L, S, {l, s}} for A<->B, and {L, S, {s, l}} for C<->D)
The patch is co-written with Eric Dumazet <edumazet@google.com>
Signed-off-by: Chema Gonzalez <chema@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 2b018d57ff ]
When PPPOE is running over a virtual ethernet interface (e.g., a
bonding interface) and the user tries to delete the interface in case
the PPPOE state is ZOMBIE, the kernel will loop forever while
unregistering net_device for the reference count is not decreased to
zero which should have been done with dev_put().
Signed-off-by: Xiaodong Xu <stid.smth@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 4c3a5bdae2 ]
SCTP charges wmem_alloc via sctp_set_owner_w() in sctp_sendmsg() and via
skb_set_owner_w() in sctp_packet_transmit(). If a sender runs out of
sndbuf it will sleep in sctp_wait_for_sndbuf() and expects to be waken up
by __sctp_write_space().
Buffer space charged via sctp_set_owner_w() is released in sctp_wfree()
which calls __sctp_write_space() directly.
Buffer space charged via skb_set_owner_w() is released via sock_wfree()
which calls sk->sk_write_space() _if_ SOCK_USE_WRITE_QUEUE is not set.
sctp_endpoint_init() sets SOCK_USE_WRITE_QUEUE on all sockets.
Therefore if sctp_packet_transmit() manages to queue up more than sndbuf
bytes, sctp_wait_for_sndbuf() will never be woken up again unless it is
interrupted by a signal.
This could be fixed by clearing the SOCK_USE_WRITE_QUEUE flag but ...
Charging for the data twice does not make sense in the first place, it
leads to overcharging sndbuf by a factor 2. Therefore this patch only
charges a single byte in wmem_alloc when transmitting an SCTP packet to
ensure that the socket stays alive until the packet has been released.
This means that control chunks are no longer accounted for in wmem_alloc
which I believe is not a problem as skb->truesize will typically lead
to overcharging anyway and thus compensates for any control overhead.
Signed-off-by: Thomas Graf <tgraf@suug.ch>
CC: Vlad Yasevich <vyasevic@redhat.com>
CC: Neil Horman <nhorman@tuxdriver.com>
CC: David Miller <davem@davemloft.net>
Acked-by: Vlad Yasevich <vyasevich@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 15c041759b ]
If recv() syscall is called for a TCP socket so that
- IOAT DMA is used
- MSG_WAITALL flag is used
- requested length is bigger than sk_rcvbuf
- enough data has already arrived to bring rcv_wnd to zero
then when tcp_recvmsg() gets to calling sk_wait_data(), receive
window can be still zero while sk_async_wait_queue exhausts
enough space to keep it zero. As this queue isn't cleaned until
the tcp_service_net_dma() call, sk_wait_data() cannot receive
any data and blocks forever.
If zero receive window and non-empty sk_async_wait_queue is
detected before calling sk_wait_data(), process the queue first.
Signed-off-by: Michal Kubecek <mkubecek@suse.cz>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 6825a26c2d ]
as we hold dst_entry before we call __ip6_del_rt,
so we should alse call dst_release not only return
-ENOENT when the rt6_info is ip6_null_entry.
and we already hold the dst entry, so I think it's
safe to call dst_release out of the write-read lock.
Signed-off-by: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 5316cf9a51 ]
skb_reset_mac_len() relies on the value of the skb->network_header pointer,
therefore we must wait for such pointer to be recalculated before computing
the new mac_len value.
Signed-off-by: Antonio Quartulli <ordex@autistici.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 2120c52da6 ]
I discovered I couldn't get sierra_net to work on a powerpc. Turns out
the firmware attribute check assumes the system is little endian and
hence fails because the attributes is a 16 bit value.
Signed-off-by: Len Sorensen <lsorense@csclub.uwaterloo.ca>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7126195697 ]
If the old timestamps of a class, say cl, are stale when the class
becomes active, then QFQ may assign to cl a much higher start time
than the maximum value allowed. This may happen when QFQ assigns to
the start time of cl the finish time of a group whose classes are
characterized by a higher value of the ratio
max_class_pkt/weight_of_the_class with respect to that of
cl. Inserting a class with a too high start time into the bucket list
corrupts the data structure and may eventually lead to crashes.
This patch limits the maximum start time assigned to a class.
Signed-off-by: Paolo Valente <paolo.valente@unimore.it>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit bdfc87f7d1 ]
Its possible to setup a bad cbq configuration leading to
an infinite loop in cbq_classify()
DEV_OUT=eth0
ICMP="match ip protocol 1 0xff"
U32="protocol ip u32"
DST="match ip dst"
tc qdisc add dev $DEV_OUT root handle 1: cbq avpkt 1000 \
bandwidth 100mbit
tc class add dev $DEV_OUT parent 1: classid 1:1 cbq \
rate 512kbit allot 1500 prio 5 bounded isolated
tc filter add dev $DEV_OUT parent 1: prio 3 $U32 \
$ICMP $DST 192.168.3.234 flowid 1:
Reported-by: Denys Fedoryschenko <denys@visp.net.lb>
Tested-by: Denys Fedoryschenko <denys@visp.net.lb>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e4d1aa40e3 ]
Add a check if pdev->bus->self == NULL (root bus). When attaching
a netxen NIC to a VM it can be on the root bus and the guest would
crash in netxen_mask_aer_correctable() because of a NULL pointer
dereference if CONFIG_PCIEAER is present.
Signed-off-by: Nikolay Aleksandrov <nikolay@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 0b836ddde1 ]
Commit 36a1211970 (netprio_cgroup.h:
dont include module.h from other includes) made the following build
error on ixp4xx_hss pop up:
CC [M] drivers/net/wan/ixp4xx_hss.o
drivers/net/wan/ixp4xx_hss.c:1412:20: error: expected ';', ',' or ')'
before string constant
drivers/net/wan/ixp4xx_hss.c:1413:25: error: expected ';', ',' or ')'
before string constant
drivers/net/wan/ixp4xx_hss.c:1414:21: error: expected ';', ',' or ')'
before string constant
drivers/net/wan/ixp4xx_hss.c:1415:19: error: expected ';', ',' or ')'
before string constant
make[8]: *** [drivers/net/wan/ixp4xx_hss.o] Error 1
This was previously hidden because ixp4xx_hss includes linux/hdlc.h which
includes linux/netdevice.h which includes linux/netprio_cgroup.h which
used to include linux/module.h. The real issue was actually present since
the initial commit that added this driver since it uses macros from
linux/module.h without including this file.
Signed-off-by: Florian Fainelli <florian@openwrt.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit ffb5ba9001 ]
chan->count is used by rx channel. If the desc count is not updated by
the clean up loop in cpdma_chan_stop, the value written to the rxfree
register in cpdma_chan_start will be incorrect.
Signed-off-by: Tao Hou <hotforest@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit ecd7918745 ]
The current code fails to ensure that the netlink message actually
contains as many bytes as the header indicates. If a user creates a new
state or updates an existing one but does not supply the bytes for the
whole ESN replay window, the kernel copies random heap bytes into the
replay bitmap, the ones happen to follow the XFRMA_REPLAY_ESN_VAL
netlink attribute. This leads to following issues:
1. The replay window has random bits set confusing the replay handling
code later on.
2. A malicious user could use this flaw to leak up to ~3.5kB of heap
memory when she has access to the XFRM netlink interface (requires
CAP_NET_ADMIN).
Known users of the ESN replay window are strongSwan and Steffen's
iproute2 patch (<http://patchwork.ozlabs.org/patch/85962/>). The latter
uses the interface with a bitmap supplied while the former does not.
strongSwan is therefore prone to run into issue 1.
To fix both issues without breaking existing userland allow using the
XFRMA_REPLAY_ESN_VAL netlink attribute with either an empty bitmap or a
fully specified one. For the former case we initialize the in-kernel
bitmap with zero, for the latter we copy the user supplied bitmap. For
state updates the full bitmap must be supplied.
To prevent overflows in the bitmap length calculation the maximum size
of bmp_len is limited to 128 by this patch -- resulting in a maximum
replay window of 4096 packets. This should be sufficient for all real
life scenarios (RFC 4303 recommends a default replay window size of 64).
Cc: Steffen Klassert <steffen.klassert@secunet.com>
Cc: Martin Willi <martin@revosec.ch>
Cc: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 1f86840f89 ]
The memory used for the template copy is a local stack variable. As
struct xfrm_user_tmpl contains multiple holes added by the compiler for
alignment, not initializing the memory will lead to leaking stack bytes
to userland. Add an explicit memset(0) to avoid the info leak.
Initial version of the patch by Brad Spengler.
Cc: Brad Spengler <spender@grsecurity.net>
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7b789836f4 ]
The memory reserved to dump the xfrm policy includes multiple padding
bytes added by the compiler for alignment (padding bytes in struct
xfrm_selector and struct xfrm_userpolicy_info). Add an explicit
memset(0) before filling the buffer to avoid the heap info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit f778a63671 ]
The memory reserved to dump the xfrm state includes the padding bytes of
struct xfrm_usersa_info added by the compiler for alignment (7 for
amd64, 3 for i386). Add an explicit memset(0) before filling the buffer
to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 4c87308bde ]
copy_to_user_auth() fails to initialize the remainder of alg_name and
therefore discloses up to 54 bytes of heap memory via netlink to
userland.
Use strncpy() instead of strcpy() to fill the trailing bytes of alg_name
with null bytes.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 433a195480 ]
if xfrm_policy_get_afinfo returns 0, it has already released the read
lock, xfrm_policy_put_afinfo should not be called again.
Signed-off-by: Li RongQing <roy.qing.li@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit c254637225 ]
When dump_one_policy() returns an error, e.g. because of a too small
buffer to dump the whole xfrm policy, xfrm_policy_netlink() returns
NULL instead of an error pointer. But its caller expects an error
pointer and therefore continues to operate on a NULL skbuff.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 864745d291 ]
When dump_one_state() returns an error, e.g. because of a too small
buffer to dump the whole xfrm state, xfrm_state_netlink() returns NULL
instead of an error pointer. But its callers expect an error pointer
and therefore continue to operate on a NULL skbuff.
This could lead to a privilege escalation (execution of user code in
kernel context) if the attacker has CAP_NET_ADMIN and is able to map
address 0.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Acked-by: Steffen Klassert <steffen.klassert@secunet.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 3b59df46a4 ]
ESN for esp is defined in RFC 4303. This RFC assumes that the
sequence number counters are always up to date. However,
this is not true if an async crypto algorithm is employed.
If the sequence number counters are not up to date on sequence
number check, we may incorrectly update the upper 32 bit of
the sequence number. This leads to a DOS.
We workaround this by comparing the upper sequence number,
(used for authentication) with the upper sequence number
computed after the async processing. We drop the packet
if these numbers are different.
To do this, we introduce a recheck function that does this
check in the ESN case.
Signed-off-by: Steffen Klassert <steffen.klassert@secunet.com>
Acked-by: Herbert Xu <herbert@gondor.apana.org.au>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e488921f44 ]
Commit d6cb3e41 "bnx2x: fix checksum validation" caused a performance
regression for IPv6. Rx checksum offload does not work. IPv6 packets
are passed to the stack with CHECKSUM_NONE.
The hardware obviously cannot perform IP checksum validation for IPv6,
because there is no checksum in the IPv6 header. This should not prevent
us from setting CHECKSUM_UNNECESSARY.
Tested on BCM57711.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Acked-by: Eilon Greenstein <eilong@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dfb117b3e5 upstream.
Check whether we evaluated _ADR successfully. Previously we ignored
failure, so we would have used garbage data from the stack as the device
and function number.
We return AE_OK so that we ignore only this slot and continue looking
for other slots.
Found by Coverity (CID 113981).
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4fe9f8e203 upstream.
When a device is unplugged, wait for all processes that have opened the device
to close before deallocating the device.
Signed-off-by: Ratan Nalumasu <ratan@google.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bcb4a75bde upstream.
Several improvements in error handling:
- do not report success if alloc_chrdev_region() failed
- check for error code of cdev_add()
- use unregister_chrdev_region() instead of unregister_chrdev()
if class_create() failed
Found by Linux Driver Verification project (linuxtesting.org).
Signed-off-by: Alexey Khoroshilov <khoroshilov@ispras.ru>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4c7b417ecb upstream.
If we don't read fast enough hidraw device, hidraw_report_event
will cycle and we will leak list->buffer.
Also list->buffer are not free on release.
After this patch, kmemleak report nothing.
Signed-off-by: Matthieu CASTET <matthieu.castet@parrot.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d6d7c87352 upstream.
Commit b6787242f3 ("HID: hidraw: add proper error handling to raw event
reporting") forgot to update the static inline version of
hidraw_report_event() for the case when CONFIG_HIDRAW is unset. Fix that
up.
Reported-by: Stephen Rothwell <sfr@canb.auug.org.au>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b6787242f3 upstream.
If kmemdup() in hidraw_report_event() fails, we are not propagating
this fact properly.
Let hidraw_report_event() and hid_report_raw_event() return an error
value to the caller.
Reported-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2f1f4d9b60 upstream.
This reverts commit 985f61f7ee.
This commit fixed certain cases, but ended up regressing others
due to limitations in the current KMS API. A proper fix is too
invasive for 3.6. Push it back to 3.7.
Reported-by: Andres Freund <andres@anarazel.de>
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2: drop the DCE6 case]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d35be8bab9 upstream.
In the event of CPU hotplug, the kernel modifies the cpusets' cpus_allowed
masks as and when necessary to ensure that the tasks belonging to the cpusets
have some place (online CPUs) to run on. And regular CPU hotplug is
destructive in the sense that the kernel doesn't remember the original cpuset
configurations set by the user, across hotplug operations.
However, suspend/resume (which uses CPU hotplug) is a special case in which
the kernel has the responsibility to restore the system (during resume), to
exactly the same state it was in before suspend.
In order to achieve that, do the following:
1. Don't modify cpusets during suspend/resume. At all.
In particular, don't move the tasks from one cpuset to another, and
don't modify any cpuset's cpus_allowed mask. So, simply ignore cpusets
during the CPU hotplug operations that are carried out in the
suspend/resume path.
2. However, cpusets and sched domains are related. We just want to avoid
altering cpusets alone. So, to keep the sched domains updated, build
a single sched domain (containing all active cpus) during each of the
CPU hotplug operations carried out in s/r path, effectively ignoring
the cpusets' cpus_allowed masks.
(Since userspace is frozen while doing all this, it will go unnoticed.)
3. During the last CPU online operation during resume, build the sched
domains by looking up the (unaltered) cpusets' cpus_allowed masks.
That will bring back the system to the same original state as it was in
before suspend.
Ultimately, this will not only solve the cpuset problem related to suspend
resume (ie., restores the cpusets to exactly what it was before suspend, by
not touching it at all) but also speeds up suspend/resume because we avoid
running cpuset update code for every CPU being offlined/onlined.
Signed-off-by: Srivatsa S. Bhat <srivatsa.bhat@linux.vnet.ibm.com>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Thomas Gleixner <tglx@linutronix.de>
Link: http://lkml.kernel.org/r/20120524141611.3692.20155.stgit@srivatsabhat.in.ibm.com
[Preeti U Murthy: Please apply this patch to the stable tree 3.0.y]
Signed-off-by: Preeti U Murthy <preeti@linux.vnet.ibm.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1b68a4ca2d upstream.
If USB2 host controller probes fine but USB3 does not then we don't
remove the USB controller properly and lock up the system while the HUB
code will try to enumerate the USB2 controller and access memory which
is no longer available in case the dummy_hcd was compiled as a module.
This is a problem since 448b6eb1 ("USB: Make sure to fetch the BOS desc
for roothubs.) if used in USB3 mode because dummy does not provide this
descriptor and explodes later.
Signed-off-by: Sebastian Andrzej Siewior <sebastian@breakpoint.cc>
Signed-off-by: Felipe Balbi <balbi@ti.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8110e16d42 upstream.
IBM reported a deadlock in select_parent(). This was found to be caused
by taking rename_lock when already locked when restarting the tree
traversal.
There are two cases when the traversal needs to be restarted:
1) concurrent d_move(); this can only happen when not already locked,
since taking rename_lock protects against concurrent d_move().
2) racing with final d_put() on child just at the moment of ascending
to parent; rename_lock doesn't protect against this rare race, so it
can happen when already locked.
Because of case 2, we need to be able to handle restarting the traversal
when rename_lock is already held. This patch fixes all three callers of
try_to_ascend().
IBM reported that the deadlock is gone with this patch.
[ I rewrote the patch to be smaller and just do the "goto again" if the
lock was already held, but credit goes to Miklos for the real work.
- Linus ]
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Cc: Al Viro <viro@ZenIV.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 32ab31e01e upstream.
The ACPI tables in the Macbook Air 5,1 define a single IOAPIC with id 2,
but the only remapping unit described in the DMAR table matches id 0.
Interrupt remapping fails as a result, and the kernel panics with the
message "timer doesn't work through Interrupt-remapped IO-APIC."
To fix this, check each IOAPIC for a corresponding IOMMU. If an IOMMU is
not found, do not allow IRQ remapping to be enabled.
v2: Move check to parse_ioapics_under_ir(), raise log level to KERN_ERR,
and add FW_BUG to the log message
v3: Skip check if IOMMU doesn't support interrupt remapping and remove
existing check that the IOMMU count equals the IOAPIC count
Acked-by: Suresh Siddha <suresh.b.siddha@intel.com>
Signed-off-by: Seth Forshee <seth.forshee@canonical.com>
Acked-by: Yinghai Lu <yinghai@kernel.org>
Signed-off-by: Joerg Roedel <joerg.roedel@amd.com>
[bwh: Backported to 3.2: adjust filename]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2588aba002 upstream.
pch_uart_interrupt() takes priv->port.lock which leads to two recursive
spinlock calls if low_latency==1 or CONFIG_PREEMPT_RT_FULL=y (one
otherwise):
pch_uart_interrupt
spin_lock_irqsave(priv->port.lock, flags)
case PCH_UART_IID_RDR_TO (data ready)
handle_rx_to
push_rx
tty_port_tty_get
spin_lock_irqsave(&port->lock, flags) <--- already hold this lock
...
tty_flip_buffer_push
...
flush_to_ldisc
spin_lock_irqsave(&tty->buf.lock)
spin_lock_irqsave(&tty->buf.lock)
disc->ops->receive_buf(tty, char_buf)
n_tty_receive_buf
tty->ops->flush_chars()
uart_flush_chars
uart_start
spin_lock_irqsave(&port->lock) <--- already hold this lock
Avoid this by using a dedicated lock to protect the eg20t_port structure
and IO access to its membase. This is more consistent with the 8250
driver. Ensure priv->lock is always take prior to priv->port.lock when
taken at the same time.
V2: Remove inadvertent whitespace change.
V3: Account for oops_in_progress for the private lock in
pch_console_write().
Note: Like the 8250 driver, if a printk is introduced anywhere inside
the pch_console_write() critical section, the kernel will hang
on a recursive spinlock on the private lock. The oops case is
handled by using a trylock in the oops_in_progress case.
Signed-off-by: Darren Hart <dvhart@linux.intel.com>
CC: Tomoya MORINAGA <tomoya.rohm@gmail.com>
CC: Feng Tang <feng.tang@intel.com>
CC: Alexander Stein <alexander.stein@systec-electronic.com>
Acked-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2:
- Adjust context
- Drop changes to pch_console_write()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d8343f1257 upstream.
In the case that the link is already in the connected state and a
Pairing request arrives from the mgmt interface, hci_conn_security()
would be called but it was not considering LE links.
Reported-by: João Paulo Rechi Vita <jprvita@openbossa.org>
Signed-off-by: Vinicius Costa Gomes <vinicius.gomes@openbossa.org>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cc110922da upstream.
To make it clear that it may be called from contexts that may not have
any knowledge of L2CAP, we change the connection parameter, to receive
a hci_conn.
This also makes it clear that it is checking the security of the link.
Signed-off-by: Vinicius Costa Gomes <vinicius.gomes@openbossa.org>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4188bba0e9 upstream.
The driver should not try to switch to 1.8V when the SD 3.0 host
controller does not have any UHS capabilities bits set (SDR50, DDR50
or SDR104). See page 72 of "SD Specifications Part A2 SD Host
Controller Simplified Specification Version 3.00" under
"1.8V Signaling Enable". Instead of setting SDR12 and SDR25 in the host
capabilities data structure for all V3.0 host controllers, only set them
if SDR104, SDR50 or DDR50 is set in the host capabilities register. This
will prevent the switch to 1.8V later.
Signed-off-by: Al Cooper <acooper@gmail.com>
Acked-by: Arindam Nath <arindam.nath@amd.com>
Acked-by: Philip Rakity <prakity@marvell.com>
Acked-by: Girish K S <girish.shivananjappa@linaro.org>
Signed-off-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c531077f40 upstream.
When using my Seagate FreeAgent GoFlex eSATAp external disk enclosure,
interface errors are always seen until 1.5Gbps is negotiated [1]. This
occurs using any disk in the enclosure, and when the disk is connected
directly with a generic passive eSATAp cable, we see stable 3Gbps
operation as expected.
Blacklist 3Gbps mode to avoid dataloss and the ~30s delay bus reset
and renegotiation incurs.
Signed-off-by: Daniel J Blueman <daniel@quora.org>
Signed-off-by: Jeff Garzik <jgarzik@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 06b6a1cf6e upstream.
Jay Fenlason (fenlason@redhat.com) found a bug,
that recvfrom() on an RDS socket can return the contents of random kernel
memory to userspace if it was called with a address length larger than
sizeof(struct sockaddr_in).
rds_recvmsg() also fails to set the addr_len paramater properly before
returning, but that's just a bug.
There are also a number of cases wher recvfrom() can return an entirely bogus
address. Anything in rds_recvmsg() that returns a non-negative value but does
not go through the "sin = (struct sockaddr_in *)msg->msg_name;" code path
at the end of the while(1) loop will return up to 128 bytes of kernel memory
to userspace.
And I write two test programs to reproduce this bug, you will see that in
rds_server, fromAddr will be overwritten and the following sock_fd will be
destroyed.
Yes, it is the programmer's fault to set msg_namelen incorrectly, but it is
better to make the kernel copy the real length of address to user space in
such case.
How to run the test programs ?
I test them on 32bit x86 system, 3.5.0-rc7.
1 compile
gcc -o rds_client rds_client.c
gcc -o rds_server rds_server.c
2 run ./rds_server on one console
3 run ./rds_client on another console
4 you will see something like:
server is waiting to receive data...
old socket fd=3
server received data from client:data from client
msg.msg_namelen=32
new socket fd=-1067277685
sendmsg()
: Bad file descriptor
/***************** rds_client.c ********************/
int main(void)
{
int sock_fd;
struct sockaddr_in serverAddr;
struct sockaddr_in toAddr;
char recvBuffer[128] = "data from client";
struct msghdr msg;
struct iovec iov;
sock_fd = socket(AF_RDS, SOCK_SEQPACKET, 0);
if (sock_fd < 0) {
perror("create socket error\n");
exit(1);
}
memset(&serverAddr, 0, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
serverAddr.sin_port = htons(4001);
if (bind(sock_fd, (struct sockaddr*)&serverAddr, sizeof(serverAddr)) < 0) {
perror("bind() error\n");
close(sock_fd);
exit(1);
}
memset(&toAddr, 0, sizeof(toAddr));
toAddr.sin_family = AF_INET;
toAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
toAddr.sin_port = htons(4000);
msg.msg_name = &toAddr;
msg.msg_namelen = sizeof(toAddr);
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_iov->iov_base = recvBuffer;
msg.msg_iov->iov_len = strlen(recvBuffer) + 1;
msg.msg_control = 0;
msg.msg_controllen = 0;
msg.msg_flags = 0;
if (sendmsg(sock_fd, &msg, 0) == -1) {
perror("sendto() error\n");
close(sock_fd);
exit(1);
}
printf("client send data:%s\n", recvBuffer);
memset(recvBuffer, '\0', 128);
msg.msg_name = &toAddr;
msg.msg_namelen = sizeof(toAddr);
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_iov->iov_base = recvBuffer;
msg.msg_iov->iov_len = 128;
msg.msg_control = 0;
msg.msg_controllen = 0;
msg.msg_flags = 0;
if (recvmsg(sock_fd, &msg, 0) == -1) {
perror("recvmsg() error\n");
close(sock_fd);
exit(1);
}
printf("receive data from server:%s\n", recvBuffer);
close(sock_fd);
return 0;
}
/***************** rds_server.c ********************/
int main(void)
{
struct sockaddr_in fromAddr;
int sock_fd;
struct sockaddr_in serverAddr;
unsigned int addrLen;
char recvBuffer[128];
struct msghdr msg;
struct iovec iov;
sock_fd = socket(AF_RDS, SOCK_SEQPACKET, 0);
if(sock_fd < 0) {
perror("create socket error\n");
exit(0);
}
memset(&serverAddr, 0, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
serverAddr.sin_port = htons(4000);
if (bind(sock_fd, (struct sockaddr*)&serverAddr, sizeof(serverAddr)) < 0) {
perror("bind error\n");
close(sock_fd);
exit(1);
}
printf("server is waiting to receive data...\n");
msg.msg_name = &fromAddr;
/*
* I add 16 to sizeof(fromAddr), ie 32,
* and pay attention to the definition of fromAddr,
* recvmsg() will overwrite sock_fd,
* since kernel will copy 32 bytes to userspace.
*
* If you just use sizeof(fromAddr), it works fine.
* */
msg.msg_namelen = sizeof(fromAddr) + 16;
/* msg.msg_namelen = sizeof(fromAddr); */
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_iov->iov_base = recvBuffer;
msg.msg_iov->iov_len = 128;
msg.msg_control = 0;
msg.msg_controllen = 0;
msg.msg_flags = 0;
while (1) {
printf("old socket fd=%d\n", sock_fd);
if (recvmsg(sock_fd, &msg, 0) == -1) {
perror("recvmsg() error\n");
close(sock_fd);
exit(1);
}
printf("server received data from client:%s\n", recvBuffer);
printf("msg.msg_namelen=%d\n", msg.msg_namelen);
printf("new socket fd=%d\n", sock_fd);
strcat(recvBuffer, "--data from server");
if (sendmsg(sock_fd, &msg, 0) == -1) {
perror("sendmsg()\n");
close(sock_fd);
exit(1);
}
}
close(sock_fd);
return 0;
}
Signed-off-by: Weiping Pan <wpan@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[Fixed upstream by commits 2955b47d2c and
a4683487f9 from Dan Williams, but they are much
more intrusive than this tiny fix, according to Andrew - gregkh]
This patch tries to fix a dead loop in async_synchronize_full(), which
could be seen when preemption is disabled on a single cpu machine.
void async_synchronize_full(void)
{
do {
async_synchronize_cookie(next_cookie);
} while (!list_empty(&async_running) || !
list_empty(&async_pending));
}
async_synchronize_cookie() calls async_synchronize_cookie_domain() with
&async_running as the default domain to synchronize.
However, there might be some works in the async_pending list from other
domains. On a single cpu system, without preemption, there is no chance
for the other works to finish, so async_synchronize_full() enters a dead
loop.
It seems async_synchronize_full() wants to synchronize all entries in
all running lists(domains), so maybe we could just check the entry_count
to know whether all works are finished.
Currently, async_synchronize_cookie_domain() expects a non-NULL running
list ( if NULL, there would be NULL pointer dereference ), so maybe a
NULL pointer could be used as an indication for the functions to
synchronize all works in all domains.
Reported-by: Paul E. McKenney <paulmck@linux.vnet.ibm.com>
Signed-off-by: Li Zhong <zhong@linux.vnet.ibm.com>
Tested-by: Paul E. McKenney <paulmck@linux.vnet.ibm.com>
Tested-by: Christian Kujau <lists@nerdbynature.de>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Dan Williams <dan.j.williams@gmail.com>
Cc: Christian Kujau <lists@nerdbynature.de>
Cc: Andrew Morton <akpm@linux-foundation.org>
Cc: Cong Wang <xiyou.wangcong@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 734b65417b upstream.
This change eliminates an initialization-order hazard most
recently seen when netprio_cgroup is built into the kernel.
With thanks to Eric Dumazet for catching a bug.
Signed-off-by: Mark Rustad <mark.d.rustad@intel.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1fa6535faf upstream.
As pointed out by Gustavo and Marcel, all Apple-specific Broadcom
devices seen so far have the same interface class, subclass and
protocol numbers. This patch adds an entry which matches all of them,
using the new USB_VENDOR_AND_INTERFACE_INFO() macro.
In particular, this patch adds support for the MacBook Pro Retina
(05ac:8286), which is not in the present list.
Signed-off-by: Henrik Rydberg <rydberg@euromail.se>
Tested-by: Shea Levy <shea@shealevy.com>
Acked-by: Marcel Holtmann <marcel@holtmann.org>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 92c385f46b upstream.
Many Broadcom devices has a vendor specific devices class, with this rule
we match all existent and future controllers with this behavior.
We also remove old rules to that matches product id for Broadcom devices.
Tested-by: John Hommel <john.hommel@hp.com>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0d00dc2611 upstream.
This patch (as1607) fixes a race that can occur if a USB host
controller is removed while a process is reading the
/sys/kernel/debug/usb/devices file.
The usb_device_read() routine uses the bus->root_hub pointer to
determine whether or not the root hub is registered. The is not a
valid test, because the pointer is set before the root hub gets
registered and remains set even after the root hub is unregistered and
deallocated. As a result, usb_device_read() or usb_device_dump() can
access freed memory, causing an oops.
The patch changes the test to use the hcd->rh_registered flag, which
does get set and cleared at the appropriate times. It also makes sure
to hold the usb_bus_list_lock mutex while setting the flag, so that
usb_device_read() will become aware of new root hubs as soon as they
are registered.
Signed-off-by: Alan Stern <stern@rowland.harvard.edu>
Reported-by: Don Zickus <dzickus@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 80b4812407 upstream.
The 'enough' function is written to work with 'near' arrays only
in that is implicitly assumes that the offset from one 'group' of
devices to the next is the same as the number of copies.
In reality it is the number of 'near' copies.
So change it to make this number explicit.
This bug makes it possible to run arrays without enough drives
present, which is dangerous.
It is appropriate for an -stable kernel, but will almost certainly
need to be modified for some of them.
Reported-by: Jakub Husák <jakub@gooseman.cz>
Signed-off-by: NeilBrown <neilb@suse.de>
[bwh: Backported to 3.2: s/geo->/conf->/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c3c4555edd upstream.
Always clear QUEUE_FLAG_ADD_RANDOM if any underlying device does not
have it set. Otherwise devices with predictable characteristics may
contribute entropy.
QUEUE_FLAG_ADD_RANDOM specifies whether or not queue IO timings
contribute to the random pool.
For bio-based targets this flag is always 0 because such devices have no
real queue.
For request-based devices this flag was always set to 1 by default.
Now set it according to the flags on underlying devices. If there is at
least one device which should not contribute, set the flag to zero: If a
device, such as fast SSD storage, is not suitable for supplying entropy,
a request-based queue stacked over it will not be either.
Because the checking logic is exactly same as for the rotational flag,
share the iteration function with device_is_nonrot().
Signed-off-by: Milan Broz <mbroz@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ba1cbad93d upstream.
The access beyond the end of device BUG_ON that was introduced to
dm_request_fn via commit 29e4013de7 ("dm: implement
REQ_FLUSH/FUA support for request-based dm") was an overly
drastic (but simple) response to this situation.
I have received a report that this BUG_ON was hit and now think
it would be better to use dm_kill_unmapped_request() to fail the clone
and original request with -EIO.
map_request() will assign the valid target returned by
dm_table_find_target to tio->ti. But when the target
isn't valid tio->ti is never assigned (because map_request isn't
called); so add a check for tio->ti != NULL to dm_done().
Reported-by: Mike Christie <michaelc@cs.wisc.edu>
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Jun'ichi Nomura <j-nomura@ce.jp.nec.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit deb09ddaff upstream.
Sandy bridge EDAC is calculating the memory size with overflow.
Basically, the size field and the integer calculation is using 32 bits.
More bits are needed, when the DIMM memories have high density.
The net result is that memories are improperly reported there, when
high-density DIMMs are used:
EDAC DEBUG: in drivers/edac/sb_edac.c, line at 591: mc#0: channel 0, dimm 0, -16384 Mb (-4194304 pages) bank: 8, rank: 2, row: 0x10000, col: 0x800
EDAC DEBUG: in drivers/edac/sb_edac.c, line at 591: mc#0: channel 1, dimm 0, -16384 Mb (-4194304 pages) bank: 8, rank: 2, row: 0x10000, col: 0x800
As the number of pages value is handled at the EDAC core as unsigned
ints, the driver shows the 16 GB memories at sysfs interface as 16760832
MB! The fix is simple: calculate the number of pages as unsigned 64-bits
integer.
After the patch, the memory size (16 GB) is properly detected:
EDAC DEBUG: in drivers/edac/sb_edac.c, line at 592: mc#0: channel 0, dimm 0, 16384 Mb (4194304 pages) bank: 8, rank: 2, row: 0x10000, col: 0x800
EDAC DEBUG: in drivers/edac/sb_edac.c, line at 592: mc#0: channel 1, dimm 0, 16384 Mb (4194304 pages) bank: 8, rank: 2, row: 0x10000, col: 0x800
Signed-off-by: Mauro Carvalho Chehab <mchehab@redhat.com>
[bwh: Backported to 3.2:
- Adjust context
- Debug log function is debugf0(), not edac_dbg()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b1268d3737 upstream.
For GPIOs of gpio-lpc32xx, gpio_direction_output() ignores the value argument
(initial value of output). This patch fixes this by setting the level
accordingly.
Signed-off-by: Roland Stigge <stigge@antcom.de>
Acked-by: Alexandre Pereira da Silva <aletes.xgr@gmail.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8d54db795d upstream.
The hypervisor is in charge of allocating the proper "NUMA" memory
and dealing with the CPU scheduler to keep them bound to the proper
NUMA node. The PV guests (and PVHVM) have no inkling of where they
run and do not need to know that right now. In the future we will
need to inject NUMA configuration data (if a guest spans two or more
NUMA nodes) so that the kernel can make the right choices. But those
patches are not yet present.
In the meantime, disable the NUMA capability in the PV guest, which
also fixes a bootup issue. Andre says:
"we see Dom0 crashes due to the kernel detecting the NUMA topology not
by ACPI, but directly from the northbridge (CONFIG_AMD_NUMA).
This will detect the actual NUMA config of the physical machine, but
will crash about the mismatch with Dom0's virtual memory. Variation of
the theme: Dom0 sees what it's not supposed to see.
This happens with the said config option enabled and on a machine where
this scanning is still enabled (K8 and Fam10h, not Bulldozer class)
We have this dump then:
NUMA: Warning: node ids are out of bound, from=-1 to=-1 distance=10
Scanning NUMA topology in Northbridge 24
Number of physical nodes 4
Node 0 MemBase 0000000000000000 Limit 0000000040000000
Node 1 MemBase 0000000040000000 Limit 0000000138000000
Node 2 MemBase 0000000138000000 Limit 00000001f8000000
Node 3 MemBase 00000001f8000000 Limit 0000000238000000
Initmem setup node 0 0000000000000000-0000000040000000
NODE_DATA [000000003ffd9000 - 000000003fffffff]
Initmem setup node 1 0000000040000000-0000000138000000
NODE_DATA [0000000137fd9000 - 0000000137ffffff]
Initmem setup node 2 0000000138000000-00000001f8000000
NODE_DATA [00000001f095e000 - 00000001f0984fff]
Initmem setup node 3 00000001f8000000-0000000238000000
Cannot find 159744 bytes in node 3
BUG: unable to handle kernel NULL pointer dereference at (null)
IP: [<ffffffff81d220e6>] __alloc_bootmem_node+0x43/0x96
Pid: 0, comm: swapper Not tainted 3.3.6 #1 AMD Dinar/Dinar
RIP: e030:[<ffffffff81d220e6>] [<ffffffff81d220e6>] __alloc_bootmem_node+0x43/0x96
.. snip..
[<ffffffff81d23024>] sparse_early_usemaps_alloc_node+0x64/0x178
[<ffffffff81d23348>] sparse_init+0xe4/0x25a
[<ffffffff81d16840>] paging_init+0x13/0x22
[<ffffffff81d07fbb>] setup_arch+0x9c6/0xa9b
[<ffffffff81683954>] ? printk+0x3c/0x3e
[<ffffffff81d01a38>] start_kernel+0xe5/0x468
[<ffffffff81d012cf>] x86_64_start_reservations+0xba/0xc1
[<ffffffff81007153>] ? xen_setup_runstate_info+0x2c/0x36
[<ffffffff81d050ee>] xen_start_kernel+0x565/0x56c
"
so we just disable NUMA scanning by setting numa_off=1.
Reported-and-Tested-by: Andre Przywara <andre.przywara@amd.com>
Acked-by: Andre Przywara <andre.przywara@amd.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5f0ecb907d upstream.
The quirk introduced with commit
00250ec909 (hwmon: fam15h_power: fix
bogus values with current BIOSes) is not only required during driver
load but also when system resumes from suspend. The BIOS might set the
previously recommended (but unsuitable) initilization value for the
running average range register during resume.
Signed-off-by: Andreas Herrmann <andreas.herrmann3@amd.com>
Tested-by: Andreas Hartmann <andihartmann@01019freenet.de>
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 596264082f upstream.
This patch fixes an issue introduced after commit 4ea5454203
("HID: Fix race condition between driver core and ll-driver").
After that commit, hid-core discards any incoming packet that arrives while
hid driver's probe function is being executed.
This broke the enumeration process of hid-logitech-dj, that must receive
control packets in-band with the mouse and keyboard packets. Discarding mouse
or keyboard data at the very begining is usually fine, but it is not the case
for control packets.
This patch forces a re-enumeration of the paired devices when a packet arrives
that comes from an unknown device.
Based on a patch originally written by Benjamin Tissoires.
Signed-off-by: Nestor Lopez Casado <nlopezcasad@logitech.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d8dc3494f7 upstream.
On a system with a logitech wireless keyboard/mouse and DMA-API debugging
enabled, this warning appears at boot:
kernel: WARNING: at lib/dma-debug.c:929 check_for_stack.part.12+0x70/0xa7()
kernel: Hardware name: MS-7593
kernel: uhci_hcd 0000:00:1d.1: DMA-API: device driver maps memory fromstack [addr=ffff8801b0079c29]
Make logi_dj_recv_query_paired_devices and logi_dj_recv_switch_to_dj_mode
use a structure allocated with kzalloc rather than a stack based one.
Signed-off-by: Marc Dionne <marc.c.dionne@gmail.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 765031668f upstream.
The user can only experience the bug if she pairs 6 devices to a Unifying
receiver. The sixth paired device would not work.
The value changed is actually a bitmask that enables reporting from each
paired device. As the sixth bit was not set, the sixth device reports are
ignored by the receiver and never get to the driver.
Signed-off-by: Nestor Lopez Casado <nlopezcasad@logitech.com>
drivers/hid/hid-logitech-dj.c | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e21093ef6f upstream.
The Revision 1.0 Janz CMOD-IO Carrier Board does not have support for
the reset registers. To support older hardware, the code is changed to
use the hardware reset register on the Janz VMOD-ICAN3 hardware itself.
Signed-off-by: Ira W. Snyder <iws@ovro.caltech.edu>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8669cf6793 upstream.
On Toshiba Satellite C850D, the touchpad and the keyboard might randomly
not work at boot. Preventing MUX mode activation solves this issue.
Signed-off-by: Anisse Astier <anisse@astier.eu>
Signed-off-by: Dmitry Torokhov <dtor@mail.ru>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bd49940a35 upstream.
As the initial domain we are able to search/map certain regions
of memory to harvest configuration data. For all low-level we
use ACPI tables - for interrupts we use exclusively ACPI _PRT
(so DSDT) and MADT for INT_SRC_OVR.
The SMP MP table is not used at all. As a matter of fact we do
not even support machines that only have SMP MP but no ACPI tables.
Lets follow how Moorestown does it and just disable searching
for BIOS SMP tables.
This also fixes an issue on HP Proliant BL680c G5 and DL380 G6:
9f->100 for 1:1 PTE
Freeing 9f-100 pfn range: 97 pages freed
1-1 mapping on 9f->100
.. snip..
e820: BIOS-provided physical RAM map:
Xen: [mem 0x0000000000000000-0x000000000009efff] usable
Xen: [mem 0x000000000009f400-0x00000000000fffff] reserved
Xen: [mem 0x0000000000100000-0x00000000cfd1dfff] usable
.. snip..
Scan for SMP in [mem 0x00000000-0x000003ff]
Scan for SMP in [mem 0x0009fc00-0x0009ffff]
Scan for SMP in [mem 0x000f0000-0x000fffff]
found SMP MP-table at [mem 0x000f4fa0-0x000f4faf] mapped at [ffff8800000f4fa0]
(XEN) mm.c:908:d0 Error getting mfn 100 (pfn 5555555555555555) from L1 entry 0000000000100461 for l1e_owner=0, pg_owner=0
(XEN) mm.c:4995:d0 ptwr_emulate: could not get_page_from_l1e()
BUG: unable to handle kernel NULL pointer dereference at (null)
IP: [<ffffffff81ac07e2>] xen_set_pte_init+0x66/0x71
. snip..
Pid: 0, comm: swapper Not tainted 3.6.0-rc6upstream-00188-gb6fb969-dirty #2 HP ProLiant BL680c G5
.. snip..
Call Trace:
[<ffffffff81ad31c6>] __early_ioremap+0x18a/0x248
[<ffffffff81624731>] ? printk+0x48/0x4a
[<ffffffff81ad32ac>] early_ioremap+0x13/0x15
[<ffffffff81acc140>] get_mpc_size+0x2f/0x67
[<ffffffff81acc284>] smp_scan_config+0x10c/0x136
[<ffffffff81acc2e4>] default_find_smp_config+0x36/0x5a
[<ffffffff81ac3085>] setup_arch+0x5b3/0xb5b
[<ffffffff81624731>] ? printk+0x48/0x4a
[<ffffffff81abca7f>] start_kernel+0x90/0x390
[<ffffffff81abc356>] x86_64_start_reservations+0x131/0x136
[<ffffffff81abfa83>] xen_start_kernel+0x65f/0x661
(XEN) Domain 0 crashed: 'noreboot' set - not rebooting.
which is that ioremap would end up mapping 0xff using _PAGE_IOMAP
(which is what early_ioremap sticks as a flag) - which meant
we would get MFN 0xFF (pte ff461, which is OK), and then it would
also map 0x100 (b/c ioremap tries to get page aligned request, and
it was trying to map 0xf4fa0 + PAGE_SIZE - so it mapped the next page)
as _PAGE_IOMAP. Since 0x100 is actually a RAM page, and the _PAGE_IOMAP
bypasses the P2M lookup we would happily set the PTE to 1000461.
Xen would deny the request since we do not have access to the
Machine Frame Number (MFN) of 0x100. The P2M[0x100] is for example
0x80140.
Fixes-Oracle-Bugzilla: https://bugzilla.oracle.com/bugzilla/show_bug.cgi?id=13665
Acked-by: Jan Beulich <jbeulich@suse.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a85d0d7f34 upstream.
When call_crda() is called we kick off a witch hunt search
for the same regulatory domain on our internal regulatory
database and that work gets kicked off on a workqueue, this
is done while the cfg80211_mutex is held. If that workqueue
kicks off it will first lock reg_regdb_search_mutex and
later cfg80211_mutex but to ensure two CPUs will not contend
against cfg80211_mutex the right thing to do is to have the
reg_regdb_search() wait until the cfg80211_mutex is let go.
The lockdep report is pasted below.
cfg80211: Calling CRDA to update world regulatory domain
======================================================
[ INFO: possible circular locking dependency detected ]
3.3.8 #3 Tainted: G O
-------------------------------------------------------
kworker/0:1/235 is trying to acquire lock:
(cfg80211_mutex){+.+...}, at: [<816468a4>] set_regdom+0x78c/0x808 [cfg80211]
but task is already holding lock:
(reg_regdb_search_mutex){+.+...}, at: [<81646828>] set_regdom+0x710/0x808 [cfg80211]
which lock already depends on the new lock.
the existing dependency chain (in reverse order) is:
-> #2 (reg_regdb_search_mutex){+.+...}:
[<800a8384>] lock_acquire+0x60/0x88
[<802950a8>] mutex_lock_nested+0x54/0x31c
[<81645778>] is_world_regdom+0x9f8/0xc74 [cfg80211]
-> #1 (reg_mutex#2){+.+...}:
[<800a8384>] lock_acquire+0x60/0x88
[<802950a8>] mutex_lock_nested+0x54/0x31c
[<8164539c>] is_world_regdom+0x61c/0xc74 [cfg80211]
-> #0 (cfg80211_mutex){+.+...}:
[<800a77b8>] __lock_acquire+0x10d4/0x17bc
[<800a8384>] lock_acquire+0x60/0x88
[<802950a8>] mutex_lock_nested+0x54/0x31c
[<816468a4>] set_regdom+0x78c/0x808 [cfg80211]
other info that might help us debug this:
Chain exists of:
cfg80211_mutex --> reg_mutex#2 --> reg_regdb_search_mutex
Possible unsafe locking scenario:
CPU0 CPU1
---- ----
lock(reg_regdb_search_mutex);
lock(reg_mutex#2);
lock(reg_regdb_search_mutex);
lock(cfg80211_mutex);
*** DEADLOCK ***
3 locks held by kworker/0:1/235:
#0: (events){.+.+..}, at: [<80089a00>] process_one_work+0x230/0x460
#1: (reg_regdb_work){+.+...}, at: [<80089a00>] process_one_work+0x230/0x460
#2: (reg_regdb_search_mutex){+.+...}, at: [<81646828>] set_regdom+0x710/0x808 [cfg80211]
stack backtrace:
Call Trace:
[<80290fd4>] dump_stack+0x8/0x34
[<80291bc4>] print_circular_bug+0x2ac/0x2d8
[<800a77b8>] __lock_acquire+0x10d4/0x17bc
[<800a8384>] lock_acquire+0x60/0x88
[<802950a8>] mutex_lock_nested+0x54/0x31c
[<816468a4>] set_regdom+0x78c/0x808 [cfg80211]
Reported-by: Felix Fietkau <nbd@openwrt.org>
Tested-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: Luis R. Rodriguez <mcgrof@do-not-panic.com>
Reviewed-by: Johannes Berg <johannes@sipsolutions.net>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 256d0eaac8 upstream.
If a command status of CMD_PROTOCOL_ERR is received, this
information should be conveyed to the SCSI mid layer, not
dropped on the floor. CMD_PROTOCOL_ERR may be received
from the Smart Array for any commands destined for an external
RAID controller such as a P2000, or commands destined for tape
drives or CD/DVD-ROM drives, if for instance a cable is
disconnected. This mostly affects multipath configurations, as
disconnecting a cable on a non-multipath configuration is not
going to do anything good regardless of whether CMD_PROTOCOL_ERR
is handled correctly or not. Not handling CMD_PROTOCOL_ERR
correctly in a multipath configaration involving external RAID
controllers may cause data corruption, so this is quite a serious
bug. This bug should not normally cause a problem for direct
attached disk storage.
Signed-off-by: Stephen M. Cameron <scameron@beardog.cce.hp.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 10cce6d8b5 upstream.
This patch checks whether HBA is SAS2008 B0 controller.
if it is a SAS2008 B0 controller then it use IO-APIC interrupt instead of MSIX,
as SAS2008 B0 controller doesn't support MSIX interrupts.
[jejb: fix whitespace problems]
Signed-off-by: Sreekanth Reddy <sreekanth.reddy@lsi.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d653220711 upstream.
This patch fixes the following kernel panic invoked by uninitialized fields
in the chip initialization for the 1G bnx2 iSCSI offload.
One of the bits in the chip initialization is being used by the latest
firmware to control overflow packets. When this control bit gets enabled
erroneously, it would ultimately result in a bad packet placement which would
cause the bnx2 driver to dereference a NULL ptr in the placement handler.
This can happen under certain stress I/O environment under the Linux
iSCSI offload operation.
This change only affects Broadcom's 5709 chipset.
Unable to handle kernel NULL pointer dereference at 0000000000000008 RIP:
[<ffffffff881f0e7d>] :bnx2:bnx2_poll_work+0xd0d/0x13c5
Pid: 0, comm: swapper Tainted: G ---- 2.6.18-333.el5debug #2
RIP: 0010:[<ffffffff881f0e7d>] [<ffffffff881f0e7d>] :bnx2:bnx2_poll_work+0xd0d/0x13c5
RSP: 0018:ffff8101b575bd50 EFLAGS: 00010216
RAX: 0000000000000005 RBX: ffff81007c5fb180 RCX: 0000000000000000
RDX: 0000000000000ffc RSI: 00000000817e8000 RDI: 0000000000000220
RBP: ffff81015bbd7ec0 R08: ffff8100817e9000 R09: 0000000000000000
R10: ffff81007c5fb180 R11: 00000000000000c8 R12: 000000007a25a010
R13: 0000000000000000 R14: 0000000000000005 R15: ffff810159f80558
FS: 0000000000000000(0000) GS:ffff8101afebc240(0000) knlGS:0000000000000000
CS: 0010 DS: 0018 ES: 0018 CR0: 000000008005003b
CR2: 0000000000000008 CR3: 0000000000201000 CR4: 00000000000006a0
Process swapper (pid: 0, threadinfo ffff8101b5754000, task ffff8101afebd820)
Stack: 000000000000000b ffff810159f80000 0000000000000040 ffff810159f80520
ffff810159f80500 00cf00cf8008e84b ffffc200100939e0 ffff810009035b20
0000502900000000 000000be00000001 ffff8100817e7810 00d08101b575bea8
Call Trace:
<IRQ> [<ffffffff8008e0d0>] show_schedstat+0x1c2/0x25b
[<ffffffff881f1886>] :bnx2:bnx2_poll+0xf6/0x231
[<ffffffff8000c9b9>] net_rx_action+0xac/0x1b1
[<ffffffff800125a0>] __do_softirq+0x89/0x133
[<ffffffff8005e30c>] call_softirq+0x1c/0x28
[<ffffffff8006d5de>] do_softirq+0x2c/0x7d
[<ffffffff8006d46e>] do_IRQ+0xee/0xf7
[<ffffffff8005d625>] ret_from_intr+0x0/0xa
<EOI> [<ffffffff801a5780>] acpi_processor_idle_simple+0x1c5/0x341
[<ffffffff801a573d>] acpi_processor_idle_simple+0x182/0x341
[<ffffffff801a55bb>] acpi_processor_idle_simple+0x0/0x341
[<ffffffff80049560>] cpu_idle+0x95/0xb8
[<ffffffff80078b1c>] start_secondary+0x479/0x488
Signed-off-by: Eddie Wai <eddie.wai@broadcom.com>
Reviewed-by: Mike Christie <michaelc@cs.wisc.edu>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b98b601672 upstream.
Clear Audio Enable bit to trigger unsolicated event to notify Audio
Driver part the HDMI hot plug change. The patch fixed the bug when
remove HDMI cable the bit was not cleared correctly.
In intel_hdmi_dpms(), if intel_hdmi->has_audio been true, the "Audio enable bit" will
be set to trigger unsolicated event to notify Alsa driver the change.
intel_hdmi->has_audio will be reset to false from intel_hdmi_detect() after
remove the hdmi cable, here's debug log:
[ 187.494153] [drm:output_poll_execute], [CONNECTOR:17:HDMI-A-1] status updated from 1 to 2
[ 187.525349] [drm:intel_hdmi_detect], HDMI: has_audio = 0
so when comes back to intel_hdmi_dpms(), the "Audio enable bit" will not be cleared. And this
cause the eld infomation and pin presence doesnot update accordingly in alsa driver side.
This patch will also trigger unsolicated event to alsa driver to notify the hot plug event:
[ 187.853159] ALSA sound/pci/hda/patch_hdmi.c:772 HDMI hot plug event: Codec=3 Pin=5 Presence_Detect=0 ELD_Valid=1
[ 187.853268] ALSA sound/pci/hda/patch_hdmi.c:990 HDMI status: Codec=3 Pin=5 Presence_Detect=0 ELD_Valid=0
Signed-off-by: Wang Xingchao <xingchao.wang@intel.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7e81a42e34 upstream.
Pin-leaks persist and we get the perennial bug reports of machine
lockups to the BUG_ON(pin_count==MAX). If we instead loudly report that
the object cannot be pinned at that time it should prevent the driver from
locking up, and hopefully restore a semblance of working whilst still
leaving us a OOPS to debug.
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e1e5b7e425 upstream.
This patch zeroes the SCTLR.TRE bit prior to setting the mapping as
cacheable for ARMv7 cores in the decompressor, ensuring that the
memory region attributes are obtained from the C and B bits, not from
the page tables.
Cc: Nicolas Pitre <nico@fluxnic.net>
Reviewed-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Matthew Leach <matthew.leach@arm.com>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c456797681 upstream.
Avoid the construction of a malformed DMA request sent to
the DMA controller.
Log message is for debug only because this condition is unlikely to
append and may only trigger at driver development time.
Signed-off-by: Nicolas Ferre <nicolas.ferre@atmel.com>
Signed-off-by: Vinod Koul <vinod.koul@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 022e1d0680 upstream.
There are a number of problems that occur for the latest version
of the Realtek RTL8188CE device with the in-kernel driver. These
include selection of the wrong firmware, and system lockup. A full
fix is known, but is too invasive for inclusion in stable. This patch
fixes the problem with loading the wrong firmware, and logs a message
that the device may not work for kernels 3.6 and older.
Signed-off-by: Larry Finger <Larry.Finger@lwfinger.net>
Cc: Anisse Astier <anisse@astier.eu>
Cc: Li Chaoming <chaoming_li@realsil.com.cn>
Tested-by: Anisse Astier <anisse@astier.eu>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 308b135e4f upstream.
kdump can be interrupted by watchdog timer when the timer is left
activated on the crash kernel. Changed the hpwdt driver to disable
watchdog timer at boot-time. This assures that watchdog timer is
disabled until /dev/watchdog is opened, and prevents watchdog timer
to be left running on the crash kernel.
Signed-off-by: Toshi Kani <toshi.kani@hp.com>
Tested-by: Lisa Mitchell <lisa.mitchell@hp.com>
Signed-off-by: Thomas Mingarelli <Thomas.Mingarelli@hp.com>
Signed-off-by: Wim Van Sebroeck <wim@iguana.be>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b5740f4b2c upstream.
try_to_wake_up() has a problem which may change status from TASK_DEAD to
TASK_RUNNING in race condition with SMI or guest environment of virtual
machine. As a result, exited task is scheduled() again and panic occurs.
Here is the sequence how it occurs:
----------------------------------+-----------------------------
|
CPU A | CPU B
----------------------------------+-----------------------------
TASK A calls exit()....
do_exit()
exit_mm()
down_read(mm->mmap_sem);
rwsem_down_failed_common()
set TASK_UNINTERRUPTIBLE
set waiter.task <= task A
list_add to sem->wait_list
:
raw_spin_unlock_irq()
(I/O interruption occured)
__rwsem_do_wake(mmap_sem)
list_del(&waiter->list);
waiter->task = NULL
wake_up_process(task A)
try_to_wake_up()
(task is still
TASK_UNINTERRUPTIBLE)
p->on_rq is still 1.)
ttwu_do_wakeup()
(*A)
:
(I/O interruption handler finished)
if (!waiter.task)
schedule() is not called
due to waiter.task is NULL.
tsk->state = TASK_RUNNING
:
check_preempt_curr();
:
task->state = TASK_DEAD
(*B)
<--- set TASK_RUNNING (*C)
schedule()
(exit task is running again)
BUG_ON() is called!
--------------------------------------------------------
The execution time between (*A) and (*B) is usually very short,
because the interruption is disabled, and setting TASK_RUNNING at (*C)
must be executed before setting TASK_DEAD.
HOWEVER, if SMI is interrupted between (*A) and (*B),
(*C) is able to execute AFTER setting TASK_DEAD!
Then, exited task is scheduled again, and BUG_ON() is called....
If the system works on guest system of virtual machine, the time
between (*A) and (*B) may be also long due to scheduling of hypervisor,
and same phenomenon can occur.
By this patch, do_exit() waits for releasing task->pi_lock which is used
in try_to_wake_up(). It guarantees the task becomes TASK_DEAD after
waking up.
Signed-off-by: Yasunori Goto <y-goto@jp.fujitsu.com>
Acked-by: Oleg Nesterov <oleg@redhat.com>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Andrew Morton <akpm@linux-foundation.org>
Link: http://lkml.kernel.org/r/20120117174031.3118.E1E9C6FF@jp.fujitsu.com
Signed-off-by: Ingo Molnar <mingo@elte.hu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6889125b8b upstream.
powernowk8_target() runs off a per-cpu work item and if the
cpufreq_policy->cpu is different from the current one, it migrates the
kworker to the target CPU by manipulating current->cpus_allowed. The
function migrates the kworker back to the original CPU but this is
still broken. Workqueue concurrency management requires the kworkers
to stay on the same CPU and powernowk8_target() ends up triggerring
BUG_ON(rq != this_rq()) in try_to_wake_up_local() if it contends on
fidvid_mutex and sleeps.
It is unclear why this bug is being reported now. Duncan says it
appeared to be a regression of 3.6-rc1 and couldn't reproduce it on
3.5. Bisection seemed to point to 63d95a91 "workqueue: use @pool
instead of @gcwq or @cpu where applicable" which is an non-functional
change. Given that the reproduce case sometimes took upto days to
trigger, it's easy to be misled while bisecting. Maybe something made
contention on fidvid_mutex more likely? I don't know.
This patch fixes the bug by using work_on_cpu() instead if @pol->cpu
isn't the same as the current one. The code assumes that
cpufreq_policy->cpu is kept online by the caller, which Rafael tells
me is the case.
stable: ed48ece27c ("workqueue: reimplement work_on_cpu() using
system_wq") should be applied before this; otherwise, the
behavior could be horrible.
Signed-off-by: Tejun Heo <tj@kernel.org>
Reported-by: Duncan <1i5t5.duncan@cox.net>
Tested-by: Duncan <1i5t5.duncan@cox.net>
Cc: Rafael J. Wysocki <rjw@sisk.pl>
Cc: Andreas Herrmann <andreas.herrmann3@amd.com>
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=47301
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ed48ece27c upstream.
The existing work_on_cpu() implementation is hugely inefficient. It
creates a new kthread, execute that single function and then let the
kthread die on each invocation.
Now that system_wq can handle concurrent executions, there's no
advantage of doing this. Reimplement work_on_cpu() using system_wq
which makes it simpler and way more efficient.
stable: While this isn't a fix in itself, it's needed to fix a
workqueue related bug in cpufreq/powernow-k8. AFAICS, this
shouldn't break other existing users.
Signed-off-by: Tejun Heo <tj@kernel.org>
Acked-by: Jiri Kosina <jkosina@suse.cz>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Bjorn Helgaas <bhelgaas@google.com>
Cc: Len Brown <lenb@kernel.org>
Cc: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b161dfa693 upstream.
IBM reported a soft lockup after applying the fix for the rename_lock
deadlock. Commit c83ce989cb ("VFS: Fix the nfs sillyrename regression
in kernel 2.6.38") was found to be the culprit.
The nfs sillyrename fix used DCACHE_DISCONNECTED to indicate that the
dentry was killed. This flag can be set on non-killed dentries too,
which results in infinite retries when trying to traverse the dentry
tree.
This patch introduces a separate flag: DCACHE_DENTRY_KILLED, which is
only set in d_kill() and makes try_to_ascend() test only this flag.
IBM reported successful test results with this patch.
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Cc: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2453f5f992 upstream.
If a command completes with a status of CMD_PROTOCOL_ERR, this
information should be conveyed to the SCSI mid layer, not dropped
on the floor. Unlike a similar bug in the hpsa driver, this bug
only affects tape drives and CD and DVD ROM drives in the cciss
driver, and to induce it, you have to disconnect (or damage) a
cable, so it is not a very likely scenario (which would explain
why the bug has gone undetected for the last 10 years.)
Signed-off-by: Stephen M. Cameron <scameron@beardog.cce.hp.com>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f14851af0e upstream.
There may be a bug when registering section info. For example, on my
Itanium platform, the pfn range of node0 includes the other nodes, so
other nodes' section info will be double registered, and memmap's page
count will equal to 3.
node0: start_pfn=0x100, spanned_pfn=0x20fb00, present_pfn=0x7f8a3, => 0x000100-0x20fc00
node1: start_pfn=0x80000, spanned_pfn=0x80000, present_pfn=0x80000, => 0x080000-0x100000
node2: start_pfn=0x100000, spanned_pfn=0x80000, present_pfn=0x80000, => 0x100000-0x180000
node3: start_pfn=0x180000, spanned_pfn=0x80000, present_pfn=0x80000, => 0x180000-0x200000
free_all_bootmem_node()
register_page_bootmem_info_node()
register_page_bootmem_info_section()
When hot remove memory, we can't free the memmap's page because
page_count() is 2 after put_page_bootmem().
sparse_remove_one_section()
free_section_usemap()
free_map_bootmem()
put_page_bootmem()
[akpm@linux-foundation.org: add code comment]
Signed-off-by: Xishi Qiu <qiuxishi@huawei.com>
Signed-off-by: Jiang Liu <jiang.liu@huawei.com>
Acked-by: Mel Gorman <mgorman@suse.de>
Cc: "Luck, Tony" <tony.luck@intel.com>
Cc: Yasuaki Ishimatsu <isimatu.yasuaki@jp.fujitsu.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0ba8f2d593 upstream.
The heuristic method for buddy has been introduced since commit
43506fad21 ("mm/page_alloc.c: simplify calculation of combined index
of adjacent buddy lists"). But the page address of higher page's buddy
was wrongly calculated, which will lead page_is_buddy to fail for ever.
IOW, the heuristic method would be disabled with the wrong page address
of higher page's buddy.
Calculating the page address of higher page's buddy should be based
higher_page with the offset between index of higher page and index of
higher page's buddy.
Signed-off-by: Haifeng Li <omycle@gmail.com>
Signed-off-by: Gavin Shan <shangw@linux.vnet.ibm.com>
Reviewed-by: Michal Hocko <mhocko@suse.cz>
Cc: KyongHo Cho <pullip.cho@samsung.com>
Cc: Mel Gorman <mgorman@suse.de>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8dcebaa9a0 upstream.
On some platforms, bootloaders are known to do some interesting RTC
programming. Without going into the obscurities as to why this may be
the case, suffice it to say the the driver should not make any
assumptions about the state of the RTC when the driver loads. In
particular, the driver probe should be sure that all interrupts are
disabled until otherwise programmed.
This was discovered when finding bursty I2C traffic every second on
Overo platforms. This I2C overhead was keeping the SoC from hitting
deep power states. The cause was found to be the RTC firing every
second on the I2C-connected TWL PMIC.
Special thanks to Felipe Balbi for suggesting to look for a rogue driver
as the source of the I2C traffic rather than the I2C driver itself.
Special thanks to Steve Sakoman for helping track down the source of the
continuous RTC interrups on the Overo boards.
Signed-off-by: Kevin Hilman <khilman@ti.com>
Cc: Felipe Balbi <balbi@ti.com>
Tested-by: Steve Sakoman <steve@sakoman.com>
Cc: Alessandro Zummo <a.zummo@towertech.it>
Tested-by: Shubhrajyoti Datta <omaplinuxkernel@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fded4e090c upstream.
Fix a serious but uncommon bug in nbd which occurs when there is heavy
I/O going to the nbd device while, at the same time, a failure (server,
network) or manual disconnect of the nbd connection occurs.
There is a small window between the time that the nbd_thread is stopped
and the socket is shutdown where requests can continue to be queued to
nbd's internal waiting_queue. When this happens, those requests are
never completed or freed.
The fix is to clear the waiting_queue on shutdown of the nbd device, in
the same way that the nbd request queue (queue_head) is already being
cleared.
Signed-off-by: Paul Clements <paul.clements@steeleye.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: local nbd_device pointers are called 'lo' not 'nbd']
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 05cf96398e upstream.
I found following definition in include/linux/memory.h, in my IA64
platform, SECTION_SIZE_BITS is equal to 32, and MIN_MEMORY_BLOCK_SIZE
will be 0.
#define MIN_MEMORY_BLOCK_SIZE (1 << SECTION_SIZE_BITS)
Because MIN_MEMORY_BLOCK_SIZE is int type and length of 32bits,
so MIN_MEMORY_BLOCK_SIZE(1 << 32) will will equal to 0.
Actually when SECTION_SIZE_BITS >= 31, MIN_MEMORY_BLOCK_SIZE will be wrong.
This will cause wrong system memory infomation in sysfs.
I think it should be:
#define MIN_MEMORY_BLOCK_SIZE (1UL << SECTION_SIZE_BITS)
And "echo offline > memory0/state" will cause following call trace:
kernel BUG at mm/memory_hotplug.c:885!
sh[6455]: bugcheck! 0 [1]
Pid: 6455, CPU 0, comm: sh
psr : 0000101008526030 ifs : 8000000000000fa4 ip : [<a0000001008c40f0>] Not tainted (3.6.0-rc1)
ip is at offline_pages+0x210/0xee0
Call Trace:
show_stack+0x80/0xa0
show_regs+0x640/0x920
die+0x190/0x2c0
die_if_kernel+0x50/0x80
ia64_bad_break+0x3d0/0x6e0
ia64_native_leave_kernel+0x0/0x270
offline_pages+0x210/0xee0
alloc_pages_current+0x180/0x2a0
Signed-off-by: Jianguo Wu <wujianguo@huawei.com>
Signed-off-by: Jiang Liu <jiang.liu@huawei.com>
Cc: "Luck, Tony" <tony.luck@intel.com>
Reviewed-by: Michal Hocko <mhocko@suse.cz>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6bf6104573 upstream.
The unregister_sysctl_table() function hangs if all references to its
ctl_table_header structure are not dropped.
This can happen sometimes because of a leak in proc_sys_lookup():
proc_sys_lookup() gets a reference to the table via lookup_entry(), but
it does not release it when a subsequent call to sysctl_follow_link()
fails.
This patch fixes this leak by making sure the reference is always
dropped on return.
See also commit 076c3eed2c ("sysctl: Rewrite proc_sys_lookup
introducing find_entry and lookup_entry") which reorganized this code in
3.4.
Tested in Linux 3.4.4.
Signed-off-by: Francesco Ruggeri <fruggeri@aristanetworks.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 57b2d68863 upstream.
The pause and resume operations indicate that the stream can be
un-paused/resumed from the exact location they were paused/suspended.
This is not true for this driver, the pause and suspend triggers share
the same code path with stop, they flush all pending DMA transfers.
This drops all pending samples. The pause_release/resume triggers are
the same as start, except that prepare won't be called beforehand,
nothing will be enqueued to the DMA engine and nothing will happen (no
audio). Removing the pause flag will let apps know that it isn't
supported. Removing the resume flag will cause user space to call
prepare and start instead of resume, so audio will continue playing when
the system wakes up.
Before removing the pause and resume flags, I tested this on an exynos
5250, using 'aplay -i'. Pause/un-pause leads to silence followed by a
write error. Suspend/resume testing led to the same result. Removing
the two flags fixes suspend/resume (since snd_pcm_prepare is called
again). And leads to a proper reporting of pause not supported.
Signed-off-by: Dylan Reid <dgreid@chromium.org>
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4c054ba63a upstream.
This patch fixes a long-standing bug with SCSI overflow handling
where se_cmd->data_length was incorrectly being re-assigned to
the larger CDB extracted allocation length, resulting in a number
of fabric level errors that would end up causing a session reset
in most cases. So instead now:
- Only re-assign se_cmd->data_length durining UNDERFLOW (to use the
smaller value)
- Use existing se_cmd->data_length for OVERFLOW (to use the smaller
value)
This fix has been tested with the following CDB to generate an
SCSI overflow:
sg_raw -r512 /dev/sdc 28 0 0 0 0 0 0 0 9 0
Tested using iscsi-target, tcm_qla2xxx, loopback and tcm_vhost fabric
ports. Here is a bit more detail on each case:
- iscsi-target: Bug with open-iscsi with overflow, sg_raw returns
-3584 bytes of data.
- tcm_qla2xxx: Working as expected, returnins 512 bytes of data
- loopback: sg_raw returns CHECK_CONDITION, from overflow rejection
in transport_generic_map_mem_to_cmd()
- tcm_vhost: Same as loopback
Reported-by: Roland Dreier <roland@purestorage.com>
Cc: Roland Dreier <roland@purestorage.com>
Cc: Christoph Hellwig <hch@lst.de>
Cc: Boaz Harrosh <bharrosh@panasas.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 55815f7014 upstream.
We already use them for openat() and friends, but fstat() also wants to
be able to use O_PATH file descriptors. This should make it more
directly comparable to the O_SEARCH of Solaris.
Note that you could already do the same thing with "fstatat()" and an
empty path, but just doing "fstat()" directly is simpler and faster, so
there is no reason not to just allow it directly.
See also commit 332a2e1244, which did the same thing for fchdir, for
the same reasons.
Reported-by: ольга крыжановская <olga.kryzhanovska@gmail.com>
Cc: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e994defb7b upstream.
Use the *_light() versions that properly avoid doing the file user count
updates when they are unnecessary.
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8335eafc28 upstream.
After calling into the lower filesystem to do a rename, the lower target
inode's attributes were not copied up to the eCryptfs target inode. This
resulted in the eCryptfs target inode staying around, rather than being
evicted, because i_nlink was not updated for the eCryptfs inode. This
also meant that eCryptfs didn't do the final iput() on the lower target
inode so it stayed around, as well. This would result in a failure to
free up space occupied by the target file in the rename() operation.
Both target inodes would eventually be evicted when the eCryptfs
filesystem was unmounted.
This patch calls fsstack_copy_attr_all() after the lower filesystem
does its ->rename() so that important inode attributes, such as i_nlink,
are updated at the eCryptfs layer. ecryptfs_evict_inode() is now called
and eCryptfs can drop its final reference on the lower inode.
http://launchpad.net/bugs/561129
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Tested-by: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 610bd7da16 upstream.
We noticed a plymouth bug on Fedora 18, and I then
noticed this stupid thinko, fixing it fixed the problem
with plymouth.
Acked-by: Ben Skeggs <bskeggs@redhat.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 985f61f7ee upstream.
For DP we can use the same PPLL for all active DP
encoders. Take advantage of that to prevent cases
where we may end up sharing a PPLL between DP and
non-DP which won't work. Also clean up the code
a bit.
v2: - fix missing pll_id assignment in crtc init
v3: - fix DP PPLL check
- document functions
- break in main encoder search loop after matching.
no need to keep checking additional encoders.
fixes:
https://bugs.freedesktop.org/show_bug.cgi?id=54471
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2: drop the DCE6 case]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ecd67955fd upstream.
No functional change, but re-order the cases so they
evaluate properly due to the way the DCE macros work.
Noticed by kallisti5 on IRC.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2: drop the DCE6 case]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 26fe45a0a7 upstream.
Selecting ATOM_PPLL_INVALID should be equivalent as the
DCPLL or PPLL0 are already programmed for the DISPCLK, but
the preferred method is to always specify the PLL selected.
SetPixelClock will check the parameters and skip the
programming if the PLL is already set up.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Reviewed-by: Christian König <christian.koenig@amd.com>
[bwh: Backported to 3.2: drop the DCE6 case]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5e1782d224 upstream.
Testing and works with the -modesetting driver,
Reviewed-by: Jakob Bornecrantz <jakob@vmware.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3737e2be50 upstream.
The AK4396 DAC has a linear-scale attentuator, but
sound/pci/ice1712/prodigy_hifi.c used a log scale instead, which is
not quite right. This patch restores the correct scale, borrowing
from the ak4396 code in sound/pci/oxygen/oxygen.c.
Signed-off-by: Matteo Frigo <athena@fftw.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3d037774b4 upstream.
There is a possibility of QH overlay region having reference to a stale
qTD pointer during unlink.
Consider an endpoint having two pending qTD before unlink process begins.
The endpoint's QH queue looks like this.
qTD1 --> qTD2 --> Dummy
To unlink qTD2, QH is removed from asynchronous list and Asynchronous
Advance Doorbell is programmed. The qTD1's next qTD pointer is set to
qTD2'2 next qTD pointer and qTD2 is retired upon controller's doorbell
interrupt. If QH's current qTD pointer points to qTD1, transfer overlay
region still have reference to qTD2. But qtD2 is just unlinked and freed.
This may cause EHCI system error. Fix this by updating qTD next pointer
in QH overlay region with the qTD next pointer of the current qTD.
Signed-off-by: Pavankumar Kondeti <pkondeti@codeaurora.org>
Acked-by: Alan Stern <stern@rowland.harvard.edu>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f08dea7348 upstream.
The Microchip vid:pid 04d8:000a is used for their CDC ACM
demo firmware application. This is a device with a single
function conforming to the CDC ACM specification and with
the intention of demonstrating CDC ACM class firmware and
driver interaction. The demo is used on a number of
development boards, and may also be used unmodified by
vendors using Microchip hardware.
Some vendors have re-used this vid:pid for other types of
firmware, emulating FTDI chips. Attempting to continue to
support such devices without breaking class based
applications that by matching on interface
class/subclass/proto being ff/ff/00. I have no information
about the actual device or interface descriptors, but this
will at least make the proper CDC ACM devices work again.
Anyone having details of the offending device's descriptors
should update this entry with the details.
Reported-by: Florian Wöhrl <fw@woehrl.biz>
Reported-by: Xiaofan Chen <xiaofanc@gmail.com>
Cc: Alan Cox <alan@linux.intel.com>
Cc: Bruno Thomsen <bruno.thomsen@gmail.com>
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 07dc59f098 upstream.
snd_hda_codec_reset() calls restore_pincfgs() where the codec is
powered up again, which eventually tries to resume and initialize via
the callbacks of the codec. However, it's the place just after codec
free callback, thus no codec callbacks should be called after that.
On a codec like CS4206, it results in Oops due to the access in init
callback.
This patch fixes the issue by clearing the codec callbacks properly
after freeing codec.
Reported-by: Daniel J Blueman <daniel@quora.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2b2040af0b upstream.
get_user may fail to load from the provided __user address due to an
unhandled fault generated by the access.
In the case of the undefined instruction trap, this results in failure
to load the faulting instruction, in which case we should send SIGILL to
the task rather than continue with potentially uninitialised data.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 70b0476a23 upstream.
'make dtbs' in a clean tree will try running the dtc before actually
building it. Make these rules depend upon the scripts to build it.
Signed-off-by: David Brown <davidb@codeaurora.org>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f39c1bfb5a upstream.
Commit 43cedbf0e8 (SUNRPC: Ensure that
we grab the XPRT_LOCK before calling xprt_alloc_slot) is causing
hangs in the case of NFS over UDP mounts.
Since neither the UDP or the RDMA transport mechanism use dynamic slot
allocation, we can skip grabbing the socket lock for those transports.
Add a new rpc_xprt_op to allow switching between the TCP and UDP/RDMA
case.
Note that the NFSv4.1 back channel assigns the slot directly
through rpc_run_bc_task, so we can ignore that case.
Reported-by: Dick Streefland <dick.streefland@altium.nl>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 01913b49cf upstream.
If decode_getfh failed, nfs4_xdr_dec_open would return 0 since the last
decode_* call must have succeeded.
Signed-off-by: Weston Andros Adamson <dros@netapp.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 60e233a566 upstream.
Fengguang Wu <fengguang.wu@intel.com> writes:
> After the __devinit* removal series, I can still get kernel panic in
> show_uevent(). So there are more sources of bug..
>
> Debug patch:
>
> @@ -343,8 +343,11 @@ static ssize_t show_uevent(struct device
> goto out;
>
> /* copy keys to file */
> - for (i = 0; i < env->envp_idx; i++)
> + dev_err(dev, "uevent %d env[%d]: %s/.../%s\n", env->buflen, env->envp_idx, top_kobj->name, dev->kobj.name);
> + for (i = 0; i < env->envp_idx; i++) {
> + printk(KERN_ERR "uevent %d env[%d]: %s\n", (int)count, i, env->envp[i]);
> count += sprintf(&buf[count], "%s\n", env->envp[i]);
> + }
>
> Oops message, the env[] is again not properly initilized:
>
> [ 44.068623] input input0: uevent 61 env[805306368]: input0/.../input0
> [ 44.069552] uevent 0 env[0]: (null)
This is a completely different CONFIG_HOTPLUG problem, only
demonstrating another reason why CONFIG_HOTPLUG should go away. I had a
hard time trying to disable it anyway ;-)
The problem this time is lots of code assuming that a call to
add_uevent_var() will guarantee that env->buflen > 0. This is not true
if CONFIG_HOTPLUG is unset. So things like this end up overwriting
env->envp_idx because the array index is -1:
if (add_uevent_var(env, "MODALIAS="))
return -ENOMEM;
len = input_print_modalias(&env->buf[env->buflen - 1],
sizeof(env->buf) - env->buflen,
dev, 0);
Don't know what the best action is, given that there seem to be a *lot*
of this around the kernel. This patch "fixes" the problem for me, but I
don't know if it can be considered an appropriate fix.
[ It is the correct fix for now, for 3.7 forcing CONFIG_HOTPLUG to
always be on is the longterm fix, but it's too late for 3.6 and older
kernels to resolve this that way - gregkh ]
Reported-by: Fengguang Wu <fengguang.wu@intel.com>
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Tested-by: Fengguang Wu <fengguang.wu@intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 92fc7a8b0f upstream.
This patch (as1604) adds a CONFIG_INTF_STRINGS quirk for the Joss
infrared touchboard device. The device doesn't like to be asked for
its interface strings.
Signed-off-by: Alan Stern <stern@rowland.harvard.edu>
Reported-by: adam ? <adam3337@wp.pl>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dafc4f7be1 upstream.
Commit b69cc67205 added support for the E-861. After acquiring a C-867, I
realised that every Physik Instrumente's device has a different PID. They are
listed in the Windows device driver's .inf file. So here are all PIDs for the
current (and probably future) USB devices from Physik Instrumente.
Compiled, but only actually tested on the E-861 and C-867.
Signed-off-by: Éric Piel <piel@delmic.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d90c92fee8 upstream.
This patch fixes a bug found by Nish Aravamudan
(https://lkml.org/lkml/2012/5/15/220) where the driver is not following
the spec (it is not aligning the rx buffer on a 16-byte boundary) and the
hypervisor aborts the registration, making the device unusable.
The fix follows BenH's recommendation (https://lkml.org/lkml/2012/7/20/461)
to replace the kmalloc+map for a single call to dma_alloc_coherent()
because that function always aligns to a 16-byte boundary.
The stable trees will run into this bug whenever the rx buffer kmalloc call
returns something not aligned on a 16-byte boundary.
Signed-off-by: Santiago Leon <santil@linux.vnet.ibm.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7be0670f7b upstream.
Remove the clock configuration from imx_setup_ufcr(). This
isn't needed here and will cause garbage output if done.
To be be sure that we only touch the bits we want (TXTL and RXTL)
we have to mask out all other bits of the UFCR register. Add
one non-existing bit macro for this, too (bit 6, DCEDTE on i.MX6).
Signed-off-by: Dirk Behme <dirk.behme@de.bosch.com>
CC: Shawn Guo <shawn.guo@linaro.org>
CC: Sascha Hauer <s.hauer@pengutronix.de>
CC: Troy Kisky <troy.kisky@boundarydevices.com>
CC: Xinyu Chen <xinyu.chen@freescale.com>
Acked-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: deleted code in imx_setup_ufcr() refers to
sport->clk not sport->clk_per]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9ec1882df2 upstream.
The console feature's write routing is unsafe on SMP with
the startup/shutdown call.
There could be several consumers of the console
* the kernel printk
* the init process using /dev/kmsg to call printk to show log
* shell, which open /dev/console and write with sys_write()
The shell goes into the normal uart open/write routing,
but the other two go into the console operations.
The open routing calls imx serial startup, which will write USR1/2
register without any lock and critical with imx_console_write call.
Add a spin_lock for startup/shutdown/console_write routing.
This patch is a port from Freescale's Android kernel.
Signed-off-by: Xinyu Chen <xinyu.chen@freescale.com>
Tested-by: Dirk Behme <dirk.behme@de.bosch.com>
CC: Sascha Hauer <s.hauer@pengutronix.de>
Acked-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2963657819 upstream.
For non PCI-based stacks, this function call
usb_disable_xhci_ports(to_pci_dev(hcd->self.controller));
made from xhci_shutdown is not applicable.
Ideally, we wouldn't have any PCI-specific code on
a generic driver such as the xHCI stack, but it looks
like we should just stub usb_disable_xhci_ports() out
for non-PCI devices.
[ balbi@ti.com: slight improvement to commit log ]
This patch should be backported to kernels as old as 3.0, since the
commit it fixes (e95829f474 "xhci: Switch
PPT ports to EHCI on shutdown.") was marked for stable.
Signed-off-by: Moiz Sonasath<m-sonasath@ti.com>
Signed-off-by: Ruchika Kharwar <ruchika@ti.com>
Signed-off-by: Felipe Balbi <balbi@ti.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 71c731a296 upstream.
This patch is intended to work around a known issue on the
SN65LVPE502CP USB3.0 re-driver that can delay the negotiation
between a device and the host past the usual handshake timeout.
If that happens on the first insertion, the host controller
port will enter in Compliance Mode and NO port status event will
be generated (as per xHCI Spec) making impossible to detect this
event by software. The port will remain in compliance mode until
a warm reset is applied to it.
As a result of this, the port will seem "dead" to the user and no
device connections or disconnections will be detected.
For solving this, the patch creates a timer which polls every 2
seconds the link state of each host controller's port (this
by reading the PORTSC register) and recovers the port by issuing a
Warm reset every time Compliance mode is detected.
If a xHC USB3.0 port has previously entered to U0, the compliance
mode issue will NOT occur only until system resumes from
sleep/hibernate, therefore, the compliance mode timer is stopped
when all xHC USB 3.0 ports have entered U0. The timer is initialized
again after each system resume.
Since the issue is being caused by a piece of hardware, the timer
will be enabled ONLY on those systems that have the SN65LVPE502CP
installed (this patch uses DMI strings for detecting those systems)
therefore making this patch to act as a quirk (XHCI_COMP_MODE_QUIRK
has been added to the xhci stack).
This patch applies for these systems:
Vendor: Hewlett-Packard. System Models: Z420, Z620 and Z820.
This patch should be backported to kernels as old as 3.2, as that was
the first kernel to support warm reset. The kernels will need to
contain both commit 10d674a82e "USB: When
hot reset for USB3 fails, try warm reset" and commit
8bea2bd37d "usb: Add support for root hub
port status CAS". The first patch add warm reset support, and the
second patch modifies the USB core to issue a warm reset when the port
is in compliance mode.
Signed-off-by: Alexis R. Cortes <alexis.cortes@ti.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e955a1cd08 upstream.
My test platform (Intel DX79SI) boots reliably under BIOS, but frequently
crashes when booting via UEFI. I finally tracked this down to the xhci
handoff code. It seems that reads from the device occasionally just return
0xff, resulting in xhci_find_next_cap_offset generating a value that's
larger than the resource region. We then oops when attempting to read the
value. Sanity checking that value lets us avoid the crash.
I've no idea what's causing the underlying problem, and xhci still doesn't
actually *work* even with this, but the machine at least boots which will
probably make further debugging easier.
This should be backported to kernels as old as 2.6.31, that contain the
commit 66d4eadd8d "USB: xhci: BIOS handoff
and HW initialization."
Signed-off-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 052c7f9ffb upstream.
The intent was to test whether the flag was set.
This patch should be backported to stable kernels as old as 3.0, since
it fixes a bug in commit e95829f474 "xhci:
Switch PPT ports to EHCI on shutdown.", which was marked for stable.
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e95829f474 upstream.
The Intel desktop boards DH77EB and DH77DF have a hardware issue that
can be worked around by BIOS. If the USB ports are switched to xHCI on
shutdown, the xHCI host will send a spurious interrupt, which will wake
the system. Some BIOS will work around this, but not all.
The bug can be avoided if the USB ports are switched back to EHCI on
shutdown. The Intel Windows driver switches the ports back to EHCI, so
change the Linux xHCI driver to do the same.
Unfortunately, we can't tell the two effected boards apart from other
working motherboards, because the vendors will change the DMI strings
for the DH77EB and DH77DF boards to their own custom names. One example
is Compulab's mini-desktop, the Intense-PC. Instead, key off the
Panther Point xHCI host PCI vendor and device ID, and switch the ports
over for all PPT xHCI hosts.
The only impact this will have on non-effected boards is to add a couple
hundred milliseconds delay on boot when the BIOS has to switch the ports
over from EHCI to xHCI.
This patch should be backported to kernels as old as 3.0, that contain
the commit 69e848c209 "Intel xhci: Support
EHCI/xHCI port switching."
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Reported-by: Denis Turischev <denis@compulab.co.il>
Tested-by: Denis Turischev <denis@compulab.co.il>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6d7d9798ad upstream.
This patch fixes a race condition that results in memory
corruption when using cleancache.
The race exists between the zcache shrinker handler,
shrink_zcache_memory() and cleancache_get_page().
In most cases, the shrinker will both evict a zbpg
from its buddy list and flush it from tmem before a
cleancache_get_page() occurs on that page. A subsequent
cleancache_get_page() will fail in the tmem layer.
In the rare case that two occur together and the
cleancache_get_page() path gets through the tmem
layer before the shrinker path can flush tmem,
zbud_decompress() does a check to see if the zbpg is a
"zombie", i.e. not on a buddy list, which means the shrinker
is in the process of reclaiming it. If the zbpg is a zombie,
zbud_decompress() returns -EINVAL.
However, this return code is being ignored by the caller,
zcache_pampd_get_data_and_free(), which results in the
caller of cleancache_get_page() thinking that the page has
been properly retrieved when it has not.
This patch modifies zcache_pampd_get_data_and_free() to
convey the failure up the stack so that the caller of
cleancache_get_page() knows the page retrieval failed.
This needs to be applied to stable trees as well.
zcache-main.c was named zcache.c before v3.1, so
I'm not sure how you want to handle trees earlier
than that.
Signed-off-by: Seth Jennings <sjenning@linux.vnet.ibm.com>
Reviewed-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Reviewed-by: Minchan Kim <minchan@kernel.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit efd5d6b03b upstream.
On our system (ARM Cortex-M3 SOC running linux-2.6.33)
frequent crashes were observed in the rt2800usb module
because of the invalid length of the received packet (3392,
46920...). This patch adds the sanity check on the packet
legth. Also, changed WARNING to ERROR in rt2x00lib_rxdone()
so that the bad packet condition would be noticed.
The fix was tested on the latest compat-wireless-3.5.1-1-snpc.
Signed-off-by: Sergei Poselenov <sposelenov@emcraft.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a396e10019 upstream.
We need to program the rfkill switch GPIO pin direction to input at
device initialization time, not only when the interface is brought up.
Doing this only when the interface is brought up could lead to rfkill
detecting the switch is turned on erroneously and inability to create
the interface and bringing it up.
Reported-and-tested-by: Andreas Messer <andi@bastelmap.de>
Signed-off-by: Gertjan van Wingerde <gwingerde@gmail.com>
Acked-by: Ivo Van Doorn <ivdoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a96874a2a9 upstream.
With a previous patch to enable the EHCI/XHCI port switching, it switches
all the available ports.
The assumption is not correct because the BIOS may expect some ports
not switchable by the OS.
There are two more registers that contains the information of the switchable
and non-switchable ports.
This patch adds the checking code for the two register so that only the
switchable ports are altered.
This patch should be backported to kernels as old as 3.0, that contain
commit ID 69e848c209 "Intel xhci: Support
EHCI/xHCI port switching."
Signed-off-by: Keng-Yu Lin <kengyu@canonical.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 29d214576f upstream.
On Intel Panther Point chipset USB 3.0 devices show up as
high-speed devices on powerup, but after an s3 cycle they are
correctly recognized as SuperSpeed. At powerup switch the port
to xHCI so that USB 3.0 devices are correctly recognized.
BugLink: http://bugs.launchpad.net/bugs/1000424
This patch should be backported to kernels as old as 3.0, that contain
commit ID 69e848c209 "Intel xhci: Support
EHCI/xHCI port switching."
Signed-off-by: Manoj Iyer <manoj.iyer@canonical.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit aa209eef3c upstream.
Hi,
This patch fixes a bug with driver failing to negotiate a connection.
The bug was traced to commit
203e4615ee
staging: vt6656: removed custom definitions of Ethernet packet types
In that patch, definitions in include/linux/if_ether.h replaced ones
in tether.h which had both big and little endian definitions.
include/linux/if_ether.h only refers to big endian values, cpu_to_be16
should be used for the correct endian architectures.
Signed-off-by: Malcolm Priestley <tvboxspy@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 61ed59ed09 upstream.
Don't zero out bits 15..12 of the data value in `das08jr_ao_winsn()` as
that knobbles the upper three-quarters of the output range for the
'das08jr-16-ao' board.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e6391a1828 upstream.
The element of `das08_boards[]` for the 'das08jr-16-ao' board has the
`ai_encoding` member set to `das08_encode12`. It should be set to
`das08_encode16` same as the 'das08jr/16' board. After all, this board
has 16-bit AI resolution.
The description of the A/D LSB register at offset 0 seems incorrect in
the user manual "cio-das08jr-16-ao.pdf" as it implies that the AI
resolution is only 12 bits. The diagrams of the A/D LSB and MSB
registers show 15 data bits and a sign bit, which matches what the
software expects for the `das08_encode16` AI encoding method.
Signed-off-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[bwh: Backported to 3.2: adjust indentation]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 872ece86ea upstream.
Apparently, am-utils is still using the legacy binary mountdata interface,
and is having trouble parsing /proc/mounts due to the 'port=' field being
incorrectly set.
The following patch should fix up the regression.
Reported-by: Marius Tolzmann <tolzmann@molgen.mpg.de>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c3f52af3e0 upstream.
When the NFS_COOKIEVERF helper macro was converted into a static
inline function in commit 99fadcd764 (nfs: convert NFS_*(inode)
helpers to static inline), we broke the initialisation of the
readdir cookies, since that depended on doing a memset with an
argument of 'sizeof(NFS_COOKIEVERF(inode))' which therefore
changed from sizeof(be32 cookieverf[2]) to sizeof(be32 *).
At this point, NFS_COOKIEVERF seems to be more of an obfuscation
than a helper, so the best thing would be to just get rid of it.
Also see: https://bugzilla.kernel.org/show_bug.cgi?id=46881
Reported-by: Andi Kleen <andi@firstfloor.org>
Reported-by: David Binderman <dcb314@hotmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a6fa941d94 upstream.
Don't mess with file refcounts (or keep a reference to file, for
that matter) in perf_event. Use explicit refcount of its own
instead. Deal with the race between the final reference to event
going away and new children getting created for it by use of
atomic_long_inc_not_zero() in inherit_event(); just have the
latter free what it had allocated and return NULL, that works
out just fine (children of siblings of something doomed are
created as singletons, same as if the child of leader had been
created and immediately killed).
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20120820135925.GG23464@ZenIV.linux.org.uk
Signed-off-by: Ingo Molnar <mingo@kernel.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cab32f39dc upstream.
The MCP2515 has a silicon bug causing repeated frame transmission, see section
5 of MCP2515 Rev. B Silicon Errata Revision G (March 2007).
Basically, setting TXBnCTRL.TXREQ in either SPI mode (00 or 11) will eventually
cause the bug. The workaround proposed by Microchip is to use mode 00 and send
a RTS command on the SPI bus to initiate the transmission.
Signed-off-by: Benoît Locher <Benoit.Locher@skf.com>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fcbc50da77 upstream.
Avoid constant wakeups caused by noisy irq lines when we don't even care
about the irq. This should be particularly useful for i945g/gm where the
hotplug has been disabled:
commit 768b107e4b
Author: Daniel Vetter <daniel.vetter@ffwll.ch>
Date: Fri May 4 11:29:56 2012 +0200
drm/i915: disable sdvo hotplug on i945g/gm
v2: While at it, remove the bogus hotplug_active read, and do not mask
hotplug_active[0] before checking whether the irq is needed, per discussion
with Daniel on IRC.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=38442
Tested-by: Dominik Köppl <dominik@devwork.org>
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 084b612ecf upstream.
Note that gen3 is the only platform where we've got the bit
definitions right, hence the workaround of disabling sdvo hotplug
support on i945g/gm is not due to misdiagnosis of broken hotplug irq
handling ...
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
[danvet: add some blurb about sdvo hotplug fail on i945g/gm I've
wondered about while reviewing.]
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- Handle all three cases in i915_driver_irq_postinstall() as there
are not separate functions for gen3 and gen4+
- Carry on using IS_SDVOB() in intel_sdvo_init()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bf8801145c upstream.
From ARM debug architecture v7.1 onwards, a watchpoint exception causes
the DFAR to be updated with the faulting data address. However, DFSR.WnR
takes an UNKNOWN value and therefore cannot be used in general to
determine the access type that triggered the watchpoint.
This patch forbids watchpoints without an overflow handler from
specifying a specific access type (load/store). Those with overflow
handlers must be able to handle false positives potentially triggered by
a watchpoint of a different access type on the same address. For
SIGTRAP-based handlers (i.e. ptrace), this should have no impact.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f1b5c997e6 upstream.
The ZTE (Vodafone) K5006-Z use the following
interface layout:
00 DIAG
01 secondary
02 modem
03 networkcard
04 storage
Ignoring interface #3 which is handled by the qmi_wwan
driver.
Cc: Thomas Schäfer <tschaefer@t-online.de>
Signed-off-by: Bjørn Mork <bjorn@mork.no>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 47f1204329 upstream.
Swap entries are encoding in ptes such that !pte_present(pte) and
pte_file(pte). The remaining bits of the descriptor are used to identify
the swapfile and offset within it to the swap entry.
When writing such a pte for a user virtual address, set_pte_at
unconditionally sets the nG bit, which (in the case of LPAE) will
corrupt the swapfile offset and lead to a BUG:
[ 140.494067] swap_free: Unused swap offset entry 000763b4
[ 140.509989] BUG: Bad page map in process rs:main Q:Reg pte:0ec76800 pmd:8f92e003
This patch fixes the problem by only setting the nG bit for user
mappings that are actually present.
Reviewed-by: Catalin Marinas <catalin.marinas@arm.com>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
This patch fixes a particularly nasty bug that was revealed by the ring
expansion patches. The bug has been present since the very beginning of
the xHCI driver history, and could have caused general protection faults
from bad memory accesses.
The first thing to note is that a Set TR Dequeue Pointer command can
move the dequeue pointer to a link TRB, if the canceled or stalled
transfer TD ended just before a link TRB. The function to increment the
dequeue pointer, inc_deq, was written before cancellation and stall
support was added. It assumed that the dequeue pointer could never
point to a link TRB. It would unconditionally increment the dequeue
pointer at the start of the function, check if the pointer was now on a
link TRB, and move it to the top of the next segment if so.
This means that if a Set TR Dequeue Point command moved the dequeue
pointer to a link TRB, a subsequent call to inc_deq() would move the
pointer off the segment and into la-la-land. It would then read from
that memory to determine if it was a link TRB. Other functions would
often call inc_deq() until the dequeue pointer matched some other
pointer, which means this function would quite happily read all of
system memory before wrapping around to the right pointer value.
Often, there would be another endpoint segment from a different ring
allocated from the same DMA pool, which would be contiguous to the
segment inc_deq just stepped off of. inc_deq would eventually find the
link TRB in that segment, and blindly move the dequeue pointer back to
the top of the correct ring segment.
The only reason the original code worked at all is because there was
only one ring segment. With the ring expansion patches, the dequeue
pointer would eventually wrap into place, but the dequeue segment would
be out-of-sync. On the second TD after the dequeue pointer was moved to
a link TRB, trb_in_td() would fail (because the dequeue pointer and
dequeue segment were out-of-sync), and this message would appear:
ERROR Transfer event TRB DMA ptr not part of current TD
This fixes bugzilla entry 4333 (option-based modem unhappy on USB 3.0
port: "Transfer event TRB DMA ptr not part of current TD", "rejecting
I/O to offline device"),
https://bugzilla.kernel.org/show_bug.cgi?id=43333
and possibly other general protection fault bugs as well.
This patch should be backported to kernels as old as 2.6.31. The
original upstream commit is 50d0206fca,
but it does not apply to kernels older than 3.4, because inc_deq was
changed in 3.3 and 3.4. This patch should apply to the 3.2 kernel and
older.
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
During modeset we have to disable the pipe to reconfigure its timings
and maybe its size. Userspace may have queued up command buffers that
depend upon the pipe running in a certain configuration and so the
commands may become confused across the modeset. At the moment, we use a
less than satisfactory kick-scanline-waits should the GPU hang during
the modeset. It should be more reliable to wait for the pending
operations to complete first, even though we still have a window for
userspace to submit a broken command buffer during the modeset.
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
(cherry picked from commit 0f91128d88)
Signed-off-by: Timo Aaltonen <timo.aaltonen@canonical.com>
This is a -stable backport of cee58483cf
Andreas Bombe reported that the added ktime_t overflow checking added to
timespec_valid in commit 4e8b14526c ("time: Improve sanity checking of
timekeeping inputs") was causing problems with X.org because it caused
timeouts larger then KTIME_T to be invalid.
Previously, these large timeouts would be clamped to KTIME_MAX and would
never expire, which is valid.
This patch splits the ktime_t overflow checking into a new
timespec_valid_strict function, and converts the timekeeping codes
internal checking to use this more strict function.
Reported-and-tested-by: Andreas Bombe <aeb@debian.org>
Cc: Zhouping Liu <zliu@redhat.com>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Prarit Bhargava <prarit@redhat.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: John Stultz <john.stultz@linaro.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Linux Kernel <linux-kernel@vger.kernel.org>
Signed-off-by: John Stultz <john.stultz@linaro.org>
This is a -stable backport of 4e8b14526c
Unexpected behavior could occur if the time is set to a value large
enough to overflow a 64bit ktime_t (which is something larger then the
year 2262).
Also unexpected behavior could occur if large negative offsets are
injected via adjtimex.
So this patch improves the sanity check timekeeping inputs by
improving the timespec_valid() check, and then makes better use of
timespec_valid() to make sure we don't set the time to an invalid
negative value or one that overflows ktime_t.
Note: This does not protect from setting the time close to overflowing
ktime_t and then letting natural accumulation cause the overflow.
Reported-by: CAI Qian <caiqian@redhat.com>
Reported-by: Sasha Levin <levinsasha928@gmail.com>
Signed-off-by: John Stultz <john.stultz@linaro.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Prarit Bhargava <prarit@redhat.com>
Cc: Zhouping Liu <zliu@redhat.com>
Cc: Ingo Molnar <mingo@kernel.org>
Link: http://lkml.kernel.org/r/1344454580-17031-1-git-send-email-john.stultz@linaro.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Linux Kernel <linux-kernel@vger.kernel.org>
Signed-off-by: John Stultz <john.stultz@linaro.org>
commit 96e65306b8 upstream.
The compiler may compile the following code into TWO write/modify
instructions.
worker->flags &= ~WORKER_UNBOUND;
worker->flags |= WORKER_REBIND;
so the other CPU may temporarily see worker->flags which doesn't have
either WORKER_UNBOUND or WORKER_REBIND set and perform local wakeup
prematurely.
Fix it by using single explicit assignment via ACCESS_ONCE().
Because idle workers have another WORKER_NOT_RUNNING flag, this bug
doesn't exist for them; however, update it to use the same pattern for
consistency.
tj: Applied the change to idle workers too and updated comments and
patch description a bit.
stable: Idle worker rebinding doesn't apply for -stable and
WORKER_UNBOUND used to be WORKER_ROGUE. Updated accordingly.
Signed-off-by: Lai Jiangshan <laijs@cn.fujitsu.com>
Signed-off-by: Tejun Heo <tj@kernel.org>
[ Upstream commit 5c879d2094 ]
Commit c3def943c7 have added support for
new pci ids of the 57840 board, while failing to change the obsolete value
in 'pci_ids.h'.
This patch does so, allowing the probe of such devices.
Signed-off-by: Yuval Mintz <yuvalmin@broadcom.com>
Signed-off-by: Eilon Greenstein <eilong@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit acbb219d5f ]
When tearing down a net namespace, ipv4 mr_table structures are freed
without first deactivating their timers. This can result in a crash in
run_timer_softirq.
This patch mimics the corresponding behaviour in ipv6.
Locking and synchronization seem to be adequate.
We are about to kfree mrt, so existing code should already make sure that
no other references to mrt are pending or can be created by incoming traffic.
The functions invoked here do not cause new references to mrt or other
race conditions to be created.
Invoking del_timer_sync guarantees that ipmr_expire_timer is inactive.
Both ipmr_expire_process (whose completion we may have to wait in
del_timer_sync) and mroute_clean_tables internally use mfc_unres_lock
or other synchronizations when needed, and they both only modify mrt.
Tested in Linux 3.4.8.
Signed-off-by: Francesco Ruggeri <fruggeri@aristanetworks.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 99469c32f7 ]
Avoid to use synchronize_rcu in l2tp_tunnel_free because context may be
atomic.
Signed-off-by: Dmitry Kozlov <xeb@mail.ru>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e2c53be223 ]
Commit -
"b852b72 gianfar: fix bug caused by
87c288c6e9aa31720b72e2bc2d665e24e1653c3e"
disables by default (on mac init) the hw vlan tag insertion.
The "features" flags were not updated to reflect this, and
"ethtool -K" shows tx-vlan-offload to be "on" by default.
Cc: Sebastian Poehn <sebastian.poehn@belden.com>
Signed-off-by: Claudiu Manoil <claudiu.manoil@freescale.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 20e1db19db ]
Non-root user-space processes can send Netlink messages to other
processes that are well-known for being subscribed to Netlink
asynchronous notifications. This allows ilegitimate non-root
process to send forged messages to Netlink subscribers.
The userspace process usually verifies the legitimate origin in
two ways:
a) Socket credentials. If UID != 0, then the message comes from
some ilegitimate process and the message needs to be dropped.
b) Netlink portID. In general, portID == 0 means that the origin
of the messages comes from the kernel. Thus, discarding any
message not coming from the kernel.
However, ctnetlink sets the portID in event messages that has
been triggered by some user-space process, eg. conntrack utility.
So other processes subscribed to ctnetlink events, eg. conntrackd,
know that the event was triggered by some user-space action.
Neither of the two ways to discard ilegitimate messages coming
from non-root processes can help for ctnetlink.
This patch adds capability validation in case that dst_pid is set
in netlink_sendmsg(). This approach is aggressive since existing
applications using any Netlink bus to deliver messages between
two user-space processes will break. Note that the exception is
NETLINK_USERSOCK, since it is reserved for netlink-to-netlink
userspace communication.
Still, if anyone wants that his Netlink bus allows netlink-to-netlink
userspace, then they can set NL_NONROOT_SEND. However, by default,
I don't think it makes sense to allow to use NETLINK_ROUTE to
communicate two processes that are sending no matter what information
that is not related to link/neighbouring/routing. They should be using
NETLINK_USERSOCK instead for that.
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e0e3cea46d ]
Pablo Neira Ayuso discovered that avahi and
potentially NetworkManager accept spoofed Netlink messages because of a
kernel bug. The kernel passes all-zero SCM_CREDENTIALS ancillary data
to the receiver if the sender did not provide such data, instead of not
including any such data at all or including the correct data from the
peer (as it is the case with AF_UNIX).
This bug was introduced in commit 16e5726269
(af_unix: dont send SCM_CREDENTIALS by default)
This patch forces passing credentials for netlink, as
before the regression.
Another fix would be to not add SCM_CREDENTIALS in
netlink messages if not provided by the sender, but it
might break some programs.
With help from Florian Weimer & Petr Matousek
This issue is designated as CVE-2012-3520
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Petr Matousek <pmatouse@redhat.com>
Cc: Florian Weimer <fweimer@redhat.com>
Cc: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit c0de08d042 ]
If a packet is emitted on one socket in one group of fanout sockets,
it is transmitted again. It is thus read again on one of the sockets
of the fanout group. This result in a loop for software which
generate packets when receiving one.
This retransmission is not the intended behavior: a fanout group
must behave like a single socket. The packet should not be
transmitted on a socket if it originates from a socket belonging
to the same fanout group.
This patch fixes the issue by changing the transmission check to
take fanout group info account.
Reported-by: Aleksandr Kotov <a1k@mail.ru>
Signed-off-by: Eric Leblond <eric@regit.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 43da5f2e0d ]
The implementation of dev_ifconf() for the compat ioctl interface uses
an intermediate ifc structure allocated in userland for the duration of
the syscall. Though, it fails to initialize the padding bytes inserted
for alignment and that for leaks four bytes of kernel stack. Add an
explicit memset(0) before filling the structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 2d8a041b7b ]
If at least one of CONFIG_IP_VS_PROTO_TCP or CONFIG_IP_VS_PROTO_UDP is
not set, __ip_vs_get_timeouts() does not fully initialize the structure
that gets copied to userland and that for leaks up to 12 bytes of kernel
stack. Add an explicit memset(0) before passing the structure to
__ip_vs_get_timeouts() to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Wensong Zhang <wensong@linux-vs.org>
Cc: Simon Horman <horms@verge.net.au>
Cc: Julian Anastasov <ja@ssi.bg>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7b07f8eb75 ]
The CCID3 code fails to initialize the trailing padding bytes of struct
tfrc_tx_info added for alignment on 64 bit architectures. It that for
potentially leaks four bytes kernel stack via the getsockopt() syscall.
Add an explicit memset(0) before filling the structure to avoid the
info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Gerrit Renker <gerrit@erg.abdn.ac.uk>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 3592aaeb80 ]
The LLC code wrongly returns 0, i.e. "success", when the socket is
zapped. Together with the uninitialized uaddrlen pointer argument from
sys_getsockname this leads to an arbitrary memory leak of up to 128
bytes kernel stack via the getsockname() syscall.
Return an error instead when the socket is zapped to prevent the info
leak. Also remove the unnecessary memset(0). We don't directly write to
the memory pointed by uaddr but memcpy() a local structure at the end of
the function that is properly initialized.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Arnaldo Carvalho de Melo <acme@ghostprotocols.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 792039c73c ]
The L2CAP code fails to initialize the l2_bdaddr_type member of struct
sockaddr_l2 and the padding byte added for alignment. It that for leaks
two bytes kernel stack via the getsockname() syscall. Add an explicit
memset(0) before filling the structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Marcel Holtmann <marcel@holtmann.org>
Cc: Gustavo Padovan <gustavo@padovan.org>
Cc: Johan Hedberg <johan.hedberg@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 9344a97296 ]
The RFCOMM code fails to initialize the trailing padding byte of struct
sockaddr_rc added for alignment. It that for leaks one byte kernel stack
via the getsockname() syscall. Add an explicit memset(0) before filling
the structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Marcel Holtmann <marcel@holtmann.org>
Cc: Gustavo Padovan <gustavo@padovan.org>
Cc: Johan Hedberg <johan.hedberg@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit f9432c5ec8 ]
The RFCOMM code fails to initialize the two padding bytes of struct
rfcomm_dev_list_req inserted for alignment before copying it to
userland. Additionally there are two padding bytes in each instance of
struct rfcomm_dev_info. The ioctl() that for disclosures two bytes plus
dev_num times two bytes uninitialized kernel heap memory.
Allocate the memory using kzalloc() to fix this issue.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Marcel Holtmann <marcel@holtmann.org>
Cc: Gustavo Padovan <gustavo@padovan.org>
Cc: Johan Hedberg <johan.hedberg@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e15ca9a0ef ]
The HCI code fails to initialize the two padding bytes of struct
hci_ufilter before copying it to userland -- that for leaking two
bytes kernel stack. Add an explicit memset(0) before filling the
structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Marcel Holtmann <marcel@holtmann.org>
Cc: Gustavo Padovan <gustavo@padovan.org>
Cc: Johan Hedberg <johan.hedberg@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 3c0c5cfdcd ]
The ATM code fails to initialize the two padding bytes of struct
sockaddr_atmpvc inserted for alignment. Add an explicit memset(0)
before filling the structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e862f1a9b7 ]
The ATM code fails to initialize the two padding bytes of struct
sockaddr_atmpvc inserted for alignment. Add an explicit memset(0)
before filling the structure to avoid the info leak.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7f5c3e3a80 ]
Here's a quote of the comment about the BUG macro from asm-generic/bug.h:
Don't use BUG() or BUG_ON() unless there's really no way out; one
example might be detecting data structure corruption in the middle
of an operation that can't be backed out of. If the (sub)system
can somehow continue operating, perhaps with reduced functionality,
it's probably not BUG-worthy.
If you're tempted to BUG(), think again: is completely giving up
really the *only* solution? There are usually better options, where
users don't need to reboot ASAP and can mostly shut down cleanly.
In our case, the status flag of a ring buffer slot is managed from both sides,
the kernel space and the user space. This means that even though the kernel
side might work as expected, the user space screws up and changes this flag
right between the send(2) is triggered when the flag is changed to
TP_STATUS_SENDING and a given skb is destructed after some time. Then, this
will hit the BUG macro. As David suggested, the best solution is to simply
remove this statement since it cannot be used for kernel side internal
consistency checks. I've tested it and the system still behaves /stable/ in
this case, so in accordance with the above comment, we should rather remove it.
Signed-off-by: Daniel Borkmann <daniel.borkmann@tik.ee.ethz.ch>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7364e445f6 ]
Do not leak memory by updating pointer with potentially NULL realloc return value.
Found by Linux Driver Verification project (linuxtesting.org).
Signed-off-by: Alexey Khoroshilov <khoroshilov@ispras.ru>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 08252b3231 ]
pptp always use init_net as the net namespace to lookup
route, this will cause route lookup failed in container.
because we already set the correct net namespace to struct
sock in pptp_create,so fix this by using sock_net(sk) to
replace &init_net.
Signed-off-by: Gao feng <gaofeng@cn.fujitsu.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 696ecdc106 ]
gact_rand array is accessed by gact->tcfg_ptype whose value
is assumed to less than MAX_RAND, but any range checks are
not performed.
So add a check in tcf_gact_init(). And in tcf_gact(), we can
reduce a branch.
Signed-off-by: Hiroaki SHIMODA <shimoda.hiroaki@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 1485348d24 ]
Cache the device gso_max_segs in sock::sk_gso_max_segs and use it to
limit the size of TSO skbs. This avoids the need to fall back to
software GSO for local TCP senders.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 7e6d06f0de ]
Currently an skb requiring TSO may not fit within a minimum-size TX
queue. The TX queue selected for the skb may stall and trigger the TX
watchdog repeatedly (since the problem skb will be retried after the
TX reset). This issue is designated as CVE-2012-3412.
Set the maximum number of TSO segments for our devices to 100. This
should make no difference to behaviour unless the actual MSS is less
than about 700. Increase the minimum TX queue size accordingly to
allow for 2 worst-case skbs, so that there will definitely be space
to add an skb after we wake a queue.
To avoid invalidating existing configurations, change
efx_ethtool_set_ringparam() to fix up values that are too small rather
than returning -EINVAL.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 30b678d844 ]
A peer (or local user) may cause TCP to use a nominal MSS of as little
as 88 (actual MSS of 76 with timestamps). Given that we have a
sufficiently prodigious local sender and the peer ACKs quickly enough,
it is nevertheless possible to grow the window for such a connection
to the point that we will try to send just under 64K at once. This
results in a single skb that expands to 861 segments.
In some drivers with TSO support, such an skb will require hundreds of
DMA descriptors; a substantial fraction of a TX ring or even more than
a full ring. The TX queue selected for the skb may stall and trigger
the TX watchdog repeatedly (since the problem skb will be retried
after the TX reset). This particularly affects sfc, for which the
issue is designated as CVE-2012-3412.
Therefore:
1. Add the field net_device::gso_max_segs holding the device-specific
limit.
2. In netif_skb_features(), if the number of segments is too high then
mask out GSO features to force fall back to software GSO.
Signed-off-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e68bb91baa upstream.
This patch adds config I2C_DESIGNWARE_CORE in Kconfig, and let
I2C_DESIGNWARE_PLATFORM and I2C_DESIGNWARE_PCI select I2C_DESIGNWARE_CORE.
Because both I2C_DESIGNWARE_PLATFORM and I2C_DESIGNWARE_PCI can be built as
built-in or module, we also need to export the functions in i2c-designware-core.
This fixes below build error when CONFIG_I2C_DESIGNWARE_PLATFORM=y &&
CONFIG_I2C_DESIGNWARE_PCI=y:
LD drivers/i2c/busses/built-in.o
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_clear_int':
i2c-designware-core.c:(.text+0xa10): multiple definition of `i2c_dw_clear_int'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x928): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_init':
i2c-designware-core.c:(.text+0x178): multiple definition of `i2c_dw_init'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x90): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `dw_readl':
i2c-designware-core.c:(.text+0xe8): multiple definition of `dw_readl'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x0): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_isr':
i2c-designware-core.c:(.text+0x724): multiple definition of `i2c_dw_isr'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x63c): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_xfer':
i2c-designware-core.c:(.text+0x4b0): multiple definition of `i2c_dw_xfer'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x3c8): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_is_enabled':
i2c-designware-core.c:(.text+0x9d4): multiple definition of `i2c_dw_is_enabled'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x8ec): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `dw_writel':
i2c-designware-core.c:(.text+0x124): multiple definition of `dw_writel'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x3c): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_xfer_msg':
i2c-designware-core.c:(.text+0x2e8): multiple definition of `i2c_dw_xfer_msg'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x200): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_enable':
i2c-designware-core.c:(.text+0x9c8): multiple definition of `i2c_dw_enable'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x8e0): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_read_comp_param':
i2c-designware-core.c:(.text+0xa24): multiple definition of `i2c_dw_read_comp_param'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x93c): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_disable':
i2c-designware-core.c:(.text+0x9dc): multiple definition of `i2c_dw_disable'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x8f4): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_func':
i2c-designware-core.c:(.text+0x710): multiple definition of `i2c_dw_func'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x628): first defined here
drivers/i2c/busses/i2c-designware-pci.o: In function `i2c_dw_disable_int':
i2c-designware-core.c:(.text+0xa18): multiple definition of `i2c_dw_disable_int'
drivers/i2c/busses/i2c-designware-platform.o:i2c-designware-platdrv.c:(.text+0x930): first defined here
make[3]: *** [drivers/i2c/busses/built-in.o] Error 1
make[2]: *** [drivers/i2c/busses] Error 2
make[1]: *** [drivers/i2c] Error 2
make: *** [drivers] Error 2
Signed-off-by: Axel Lin <axel.lin@gmail.com>
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Tested-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b5031ed1be upstream.
When running 32-bit pvops-dom0 and a driver tries to allocate a coherent
DMA-memory the xen swiotlb-implementation returned memory beyond 4GB.
The underlaying reason is that if the supplied driver passes in a
DMA_BIT_MASK(64) ( hwdev->coherent_dma_mask is set to 0xffffffffffffffff)
our dma_mask will be u64 set to 0xffffffffffffffff even if we set it to
DMA_BIT_MASK(32) previously. Meaning we do not reset the upper bits.
By using the dma_alloc_coherent_mask function - it does the proper casting
and we get 0xfffffffff.
This caused not working sound on a system with 4 GB and a 64-bit
compatible sound-card with sets the DMA-mask to 64bit.
On bare-metal and the forward-ported xen-dom0 patches from OpenSuse a coherent
DMA-memory is always allocated inside the 32-bit address-range by calling
dma_alloc_coherent_mask.
This patch adds the same functionality to xen swiotlb and is a rebase of the
original patch from Ronny Hegewald which never got upstream b/c the
underlaying reason was not understood until now.
The original email with the original patch is in:
http://old-list-archives.xen.org/archives/html/xen-devel/2010-02/msg00038.html
the original thread from where the discussion started is in:
http://old-list-archives.xen.org/archives/html/xen-devel/2010-01/msg00928.html
Signed-off-by: Ronny Hegewald <ronny.hegewald@online.de>
Signed-off-by: Stefano Panella <stefano.panella@citrix.com>
Acked-By: David Vrabel <david.vrabel@citrix.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9c2fc0de1a upstream.
When a file is stored in ICB (inode), we overwrite part of the file, and
the page containing file's data is not in page cache, we end up corrupting
file's data by overwriting them with zeros. The problem is we use
simple_write_begin() which simply zeroes parts of the page which are not
written to. The problem has been introduced by be021ee4 (udf: convert to
new aops).
Fix the problem by providing a ->write_begin function which makes the page
properly uptodate.
Reported-by: Ian Abbott <abbotti@mev.co.uk>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9fb1b36ca1 upstream.
We have been observing hangs, both of KVM guest vcpu tasks and more
generally, where a process that is woken doesn't properly wake up and
continue to run, but instead sticks in TASK_WAKING state. This
happens because the update of rq->wake_list in ttwu_queue_remote()
is not ordered with the update of ipi_message in
smp_muxed_ipi_message_pass(), and the reading of rq->wake_list in
scheduler_ipi() is not ordered with the reading of ipi_message in
smp_ipi_demux(). Thus it is possible for the IPI receiver not to see
the updated rq->wake_list and therefore conclude that there is nothing
for it to do.
In order to make sure that anything done before smp_send_reschedule()
is ordered before anything done in the resulting call to scheduler_ipi(),
this adds barriers in smp_muxed_message_pass() and smp_ipi_demux().
The barrier in smp_muxed_message_pass() is a full barrier to ensure that
there is a full ordering between the smp_send_reschedule() caller and
scheduler_ipi(). In smp_ipi_demux(), we use xchg() rather than
xchg_local() because xchg() includes release and acquire barriers.
Using xchg() rather than xchg_local() makes sense given that
ipi_message is not just accessed locally.
This moves the barrier between setting the message and calling the
cause_ipi() function into the individual cause_ipi implementations.
Most of them -- those that used outb, out_8 or similar -- already had
a full barrier because out_8 etc. include a sync before the MMIO
store. This adds an explicit barrier in the two remaining cases.
These changes made no measurable difference to the speed of IPIs as
measured using a simple ping-pong latency test across two CPUs on
different cores of a POWER7 machine.
The analysis of the reason why processes were not waking up properly
is due to Milton Miller.
Reported-by: Milton Miller <miltonm@bga.com>
Signed-off-by: Paul Mackerras <paulus@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3ce21cdfe9 upstream.
During kdump stress testing I sometimes see the kdump kernel panic
with:
Interrupt 0x306 (real) is invalid, disabling it.
Kernel panic - not syncing: bad return code EOI - rc = -4, value=ff000306
Instead of panicing print the error message, dump the stack the first
time it happens and continue on. Add some more information to the
debug messages as well.
Signed-off-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1021cb268b upstream.
If the default DSCR is non zero we set thread.dscr_inherit in
copy_thread() meaning the new thread and all its children will ignore
future updates to the default DSCR. This is not intended and is
a change in behaviour that a number of our users have hit.
We just need to inherit thread.dscr and thread.dscr_inherit from
the parent which ends up being much simpler.
This was found with the following test case:
http://ozlabs.org/~anton/junkcode/dscr_default_test.c
Signed-off-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 00ca0de02f upstream.
When we update the DSCR either via emulation of mtspr(DSCR) or via
a change to dscr_default in sysfs we don't update thread.dscr.
We will eventually update it at context switch time but there is
a period where thread.dscr is incorrect.
If we fork at this point we will copy the old value of thread.dscr
into the child. To avoid this, always keep thread.dscr in sync with
reality.
This issue was found with the following testcase:
http://ozlabs.org/~anton/junkcode/dscr_inherit_test.c
Signed-off-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1b6ca2a6fe upstream.
Writing to dscr_default in sysfs doesn't actually change the DSCR -
we rely on a context switch on each CPU to do the work. There is no
guarantee we will get a context switch in a reasonable amount of time
so fire off an IPI to force an immediate change.
This issue was found with the following test case:
http://ozlabs.org/~anton/junkcode/dscr_explicit_test.c
Signed-off-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 74f330bcea upstream.
Since commit 30832ab56 ("mmc: sdhci: Always pass clock request value
zero to set_clock host op") was merged, esdhc_set_clock starts hitting
"if (clock == 0)" where ESDHC_SYSTEM_CONTROL has been operated. This
causes SDHCI card-detection function being broken. Fix the regression
by moving "if (clock == 0)" above ESDHC_SYSTEM_CONTROL operation.
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c9e67d4837 upstream.
In some cases fuse_retrieve() would return a short byte count if offset was
non-zero. The data returned was correct, though.
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 78b495c39a upstream.
UBI was mistakingly using 'kfree()' instead of 'kmem_cache_free()' when
freeing "attach eraseblock" structures in vtbl.c. Thankfully, this happened
only when we were doing auto-format, so many systems were unaffected. However,
there are still many users affected.
It is strange, but the system did not crash and nothing bad happened when
the SLUB memory allocator was used. However, in case of SLOB we observed an
crash right away.
This problem was introduced in 2.6.39 by commit
"6c1e875 UBI: add slab cache for ubi_scan_leb objects"
A note for stable trees:
Because variable were renamed, this won't cleanly apply to older kernels.
Changing names like this should help:
1. ai -> si
2. aeb_slab_cache -> seb_slab_cache
3. new_aeb -> new_seb
Reported-by: Richard Genoud <richard.genoud@gmail.com>
Tested-by: Richard Genoud <richard.genoud@gmail.com>
Tested-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
[bwh: Backported to 3.2: aeb_slab_cache was actually named scan_leb_slab]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 156bddd8e5 upstream.
Code tracking when transaction needs to be committed on fdatasync(2) forgets
to handle a situation when only inode's i_size is changed. Thus in such
situations fdatasync(2) doesn't force transaction with new i_size to disk
and that can result in wrong i_size after a crash.
Fix the issue by updating inode's i_datasync_tid whenever its size is
updated.
Reported-by: Kristian Nielsen <knielsen@knielsen-hq.org>
Signed-off-by: Jan Kara <jack@suse.cz>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d821a4c4d1 upstream.
With a low enough MSS on the link partner and TSO enabled locally, the
networking stack can periodically send a very large (e.g. 64KB) TCP
message for which the driver will attempt to use more Tx descriptors than
are available by default in the Tx ring. This is due to a workaround in
the code that imposes a limit of only 4 MSS-sized segments per descriptor
which appears to be a carry-over from the older e1000 driver and may be
applicable only to some older PCI or PCIx parts which are not supported in
e1000e. When the driver gets a message that is too large to fit across the
configured number of Tx descriptors, it stops the upper stack from queueing
any more and gets stuck in this state. After a timeout, the upper stack
assumes the adapter is hung and calls the driver to reset it.
Remove the unnecessary limitation of using up to only 4 MSS-sized segments
per Tx descriptor, and put in a hard failure test to catch when attempting
to check for message sizes larger than would fit in the whole Tx ring.
Refactor the remaining logic that limits the size of data per Tx descriptor
from a seemingly arbitrary 8KB to a limit based on the dynamic size of the
Tx packet buffer as described in the hardware specification.
Also, fix the logic in the check for space in the Tx ring for the next
largest possible packet after the current one has been successfully queued
for transmit, and use the appropriate defines for default ring sizes in
e1000_probe instead of magic values.
This issue goes back to the introduction of e1000e in 2.6.24 when it was
split off from e1000.
Reported-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: Bruce Allan <bruce.w.allan@intel.com>
Tested-by: Aaron Brown <aaron.f.brown@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
[bwh: Backported to 3.2:
- Adjust context
- Adjust for use of net_device vs e1000_ring parameter]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8d1af57ae3 upstream.
The ordering is important and the current drm code
wasn't cutting it for modern DIG encoders. We need
to have information about crtc before setting up
the encoders so I've shifted the ordering a bit.
Probably we'll need a full rework akin to danvet's
recent intel patchs. This patch fixes numerous
issues with DP bridge chips and makes link training
much more reliable.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2: drop DCE6 cases]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4e58591c89 upstream.
Some plls are shared for DP.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Reviewed-by: Michel Dänzer <michel.daenzer@amd.com>
[bwh: Backported to 3.2: add the dev and rdev variables, previously added
upstream to support DCE6.1 which isn't supported in this version]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 67ddbb3e65 upstream.
This patch (as1603) adds a NOGET quirk for the Eaton Ellipse MAX UPS
device. (The USB IDs were already present in hid-ids.h, apparently
under a different name.)
Signed-off-by: Alan Stern <stern@rowland.harvard.edu>
Reported-by: Laurent Bigonville <l.bigonville@edpnet.be>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b7ea95ff9b upstream.
This patch modifies hid-multitouch driver for supporting PixArt optical touch
screen. Because of the device does not have to set initial report, we apply
"HID_QUIRK_NO_INIT_REPORTS" quirk and add the device into hid_blacklist[]
Signed-off-by: Aaron Tian <aaron_tian@pixart.com.tw>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit acb4b992d8 upstream.
Each of these error messages can be caused by a broken or malicious
userspace wanting to spam the dmesg with useless info. They're really
not worthy of DRM_DEBUG statements either; those are generally only
useful during bringup of new hardware or versions, and ought to be
removed before going upstream anyway.
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Reviewed-by: Alex Deucher <alexdeucher@gmail.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
[bwh: Backported to 3.2: s/r\./r->/ in drm_mode_addfb()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f637c4c940 upstream.
The i.MX cpufreq implementation uses the CPU_FREQ_TABLE helpers,
so it needs to select that code to be built. This problem has
apparently existed since the i.MX cpufreq code was first merged
in v2.6.37.
Building IMX without CPU_FREQ_TABLE results in:
arch/arm/plat-mxc/built-in.o: In function `mxc_cpufreq_exit':
arch/arm/plat-mxc/cpufreq.c:173: undefined reference to `cpufreq_frequency_table_put_attr'
arch/arm/plat-mxc/built-in.o: In function `mxc_set_target':
arch/arm/plat-mxc/cpufreq.c:84: undefined reference to `cpufreq_frequency_table_target'
arch/arm/plat-mxc/built-in.o: In function `mxc_verify_speed':
arch/arm/plat-mxc/cpufreq.c:65: undefined reference to `cpufreq_frequency_table_verify'
arch/arm/plat-mxc/built-in.o: In function `mxc_cpufreq_init':
arch/arm/plat-mxc/cpufreq.c:154: undefined reference to `cpufreq_frequency_table_cpuinfo'
arch/arm/plat-mxc/cpufreq.c:162: undefined reference to `cpufreq_frequency_table_get_attr'
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Shawn Guo <shawn.guo@linaro.org>
Cc: Sascha Hauer <s.hauer@pengutronix.de>
Cc: Yong Shen <yong.shen@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c96aae1f7f upstream.
When we are finished with return PFNs to the hypervisor, then
populate it back, and also mark the E820 MMIO and E820 gaps
as IDENTITY_FRAMEs, we then call P2M to set areas that can
be used for ballooning. We were off by one, and ended up
over-writting a P2M entry that most likely was an IDENTITY_FRAME.
For example:
1-1 mapping on 40000->40200
1-1 mapping on bc558->bc5ac
1-1 mapping on bc5b4->bc8c5
1-1 mapping on bc8c6->bcb7c
1-1 mapping on bcd00->100000
Released 614 pages of unused memory
Set 277889 page(s) to 1-1 mapping
Populating 40200-40466 pfn range: 614 pages added
=> here we set from 40466 up to bc559 P2M tree to be
INVALID_P2M_ENTRY. We should have done it up to bc558.
The end result is that if anybody is trying to construct
a PTE for PFN bc558 they end up with ~PAGE_PRESENT.
Reported-by-and-Tested-by: Andre Przywara <andre.przywara@amd.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a46d2619d7 upstream.
The binding doc and dts use properties "fsl,{cd,wp}-internal" while
esdhc driver uses "fsl,{cd,wp}-controller". Fix binding doc and dts
to get them match driver code.
Reported-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Acked-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c944b0b935 upstream.
Though commit 602bf40 (ARM: imx6: exit coherency when shutting down
a cpu) improves the stability of imx6q cpu hotplug a lot, there are
still hangs seen with a more stressful hotplug testing.
It's expected that once imx_enable_cpu(cpu, false) is called, the cpu
will be taken down by hardware immediately, and the code after that
will not get any chance to execute. However, this is not always the
case from the testing. The cpu could possibly be alive for a few
cycles before hardware actually takes it down. So rather than letting
cpu execute some code that could cause a hang in these cycles, let's
make the cpu spin there and wait for hardware to take it down.
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c1c52848ce upstream.
omapfb does not currently set pseudo palette correctly for color depths
above 16bpp, making red text invisible, command like
echo -e '\e[0;31mRED' > /dev/tty1
will display nothing on framebuffer console in 24bpp mode.
This is because temporary variable is declared incorrectly, fix it.
Signed-off-by: Grazvydas Ignotas <notasas@gmail.com>
Signed-off-by: Tomi Valkeinen <tomi.valkeinen@ti.com>
Signed-off-by: Florian Tobias Schandinat <FlorianSchandinat@gmx.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 43ca6cb28c upstream.
The old interface is bugged and reads the wrong sensor when retrieving
the reading for the chassis fan (it reads the CPU sensor); the new
interface works fine.
Reported-by: Göran Uddeborg <goeran@uddeborg.se>
Tested-by: Göran Uddeborg <goeran@uddeborg.se>
Signed-off-by: Luca Tettamanti <kronos.it@gmail.com>
Signed-off-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 14216561e1 upstream.
This is a particularly nasty SCSI ATA Translation Layer (SATL) problem.
SAT-2 says (section 8.12.2)
if the device is in the stopped state as the result of
processing a START STOP UNIT command (see 9.11), then the SATL
shall terminate the TEST UNIT READY command with CHECK CONDITION
status with the sense key set to NOT READY and the additional
sense code of LOGICAL UNIT NOT READY, INITIALIZING COMMAND
REQUIRED;
mpt2sas internal SATL seems to implement this. The result is very confusing
standby behaviour (using hdparm -y). If you suspend a drive and then send
another command, usually it wakes up. However, if the next command is a TEST
UNIT READY, the SATL sees that the drive is suspended and proceeds to follow
the SATL rules for this, returning NOT READY to all subsequent commands. This
means that the ordering of TEST UNIT READY is crucial: if you send TUR and
then a command, you get a NOT READY to both back. If you send a command and
then a TUR, you get GOOD status because the preceeding command woke the drive.
This bit us badly because
commit 85ef06d1d2
Author: Tejun Heo <tj@kernel.org>
Date: Fri Jul 1 16:17:47 2011 +0200
block: flush MEDIA_CHANGE from drivers on close(2)
Changed our ordering on TEST UNIT READY commands meaning that SATA drives
connected to an mpt2sas now suspend and refuse to wake (because the mpt2sas
SATL sees the suspend *before* the drives get awoken by the next ATA command)
resulting in lots of failed commands.
The standard is completely nuts forcing this inconsistent behaviour, but we
have to work around it.
The fix for this is twofold:
1. Set the allow_restart flag so we wake the drive when we see it has been
suspended
2. Return all TEST UNIT READY status directly to the mid layer without any
further error handling which prevents us causing error handling which
may offline the device just because of a media check TUR.
Reported-by: Matthias Prager <linux@matthiasprager.de>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bd8d6dd43a upstream.
The following patch moves the poll_aen_lock initializer from
megasas_probe_one() to megasas_init(). This prevents a crash when a user
loads the driver and tries to issue a poll() system call on the ioctl
interface with no adapters present.
Signed-off-by: Kashyap Desai <Kashyap.Desai@lsi.com>
Signed-off-by: Adam Radford <aradford@gmail.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 338b131a32 upstream.
If the specified max_queue_depth setting is less than the
expected number of internal commands, then driver will calculate
the queue depth size to a negitive number. This negitive number
is actually a very large number because variable is unsigned
16bit integer. So, the driver will ask for a very large amount of
memory for message frames and resulting into oops as memory
allocation routines will not able to handle such a large request.
So, in order to limit this kind of oops, The driver need to set
the max_queue_depth to a scsi mid layer's can_queue value. Then
the overall message frames required for IO is minimum of either
(max_queue_depth plus internal commands) or the IOC global
credits.
Signed-off-by: Sreekanth Reddy <sreekanth.reddy@lsi.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4fc79db178 upstream.
If the device is not started, we can't read its
SRAM and attempting to do so will cause issues.
Protect the debugfs read.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2:
- Adjust context
- Pass iwl_shared not iwl_priv pointer to iwl_is_ready_rf()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 94543a8d4f upstream.
iwl_dbgfs_fh_reg_read() can cause crashes and/or
BUG_ON in slub because the ifdefs are wrong, the
code in iwl_dump_fh() should use DEBUGFS, not
DEBUG to protect the buffer writing code.
Also, while at it, clean up the arguments to the
function, some code and make it generally safer.
Reported-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust filenames and context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 58569aee5a upstream.
The mv643xx ethernet controller limits the packet size for the TX
checksum offloading. This patch sets this limits for Kirkwood and
Dove which have smaller limits that the default.
As a side note, this patch is an updated version of a patch sent some years
ago: http://lists.infradead.org/pipermail/linux-arm-kernel/2010-June/017320.html
which seems to have been lost.
Signed-off-by: Arnaud Patard <arnaud.patard@rtp-net.org>
Signed-off-by: Jason Cooper <jason@lakedaemon.net>
[bwh: Backported to 3.2: adjust for the extra two parameters of
orion_ge0{0,1}_init()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 54f32a35f4 upstream.
Calling the dmtimer function omap_dm_timer_set_source() fails if following a
call to pm_runtime_put() to disable the timer. For example the following
sequence would fail to set the parent clock ...
omap_dm_timer_stop(gptimer);
omap_dm_timer_set_source(gptimer, OMAP_TIMER_SRC_32_KHZ);
The following error message would be seen ...
omap_dm_timer_set_source: failed to set timer_32k_ck as parent
The problem is that, by design, pm_runtime_put() simply decrements the usage
count and returns before the timer has actually been disabled. Therefore,
setting the parent clock failed because the timer was still active when the
trying to set the parent clock. Setting a parent clock will fail if the clock
you are setting the parent of has a non-zero usage count. To ensure that this
does not fail use pm_runtime_put_sync() when disabling the timer.
Note that this will not be seen on OMAP1 devices, because these devices do
not use the clock framework for dmtimers.
Signed-off-by: Jon Hunter <jon-hunter@ti.com>
Acked-by: Kevin Hilman <khilman@ti.com>
Signed-off-by: Tony Lindgren <tony@atomide.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b01858c780 upstream.
Commit d670ac019f (ARM: SAMSUNG: DMA Cleanup as per sparse) changed the
prototype of the s3c2410_dma_* functions to use the enum dma_ch instead
of an generic unsigned int.
In the s3c24xx dma.c s3c2410_dma_enqueue seems to have been forgotten,
the other functions there were changed correctly.
Signed-off-by: Heiko Stuebner <heiko@sntech.de>
Signed-off-by: Kukjin Kim <kgene.kim@samsung.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bba3d8c3b3 upstream.
The following build error occured during a parisc build with
swap-over-NFS patches applied.
net/core/sock.c:274:36: error: initializer element is not constant
net/core/sock.c:274:36: error: (near initialization for 'memalloc_socks')
net/core/sock.c:274:36: error: initializer element is not constant
Dave Anglin says:
> Here is the line in sock.i:
>
> struct static_key memalloc_socks = ((struct static_key) { .enabled =
> ((atomic_t) { (0) }) });
The above line contains two compound literals. It also uses a designated
initializer to initialize the field enabled. A compound literal is not a
constant expression.
The location of the above statement isn't fully clear, but if a compound
literal occurs outside the body of a function, the initializer list must
consist of constant expressions.
Reported-by: Fengguang Wu <fengguang.wu@intel.com>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fe35004fbf upstream.
Sometimes we'd like to avoid swapping out anonymous memory. In
particular, avoid swapping out pages of important process or process
groups while there is a reasonable amount of pagecache on RAM so that we
can satisfy our customers' requirements.
OTOH, we can control how aggressive the kernel will swap memory pages with
/proc/sys/vm/swappiness for global and
/sys/fs/cgroup/memory/memory.swappiness for each memcg.
But with current reclaim implementation, the kernel may swap out even if
we set swappiness=0 and there is pagecache in RAM.
This patch changes the behavior with swappiness==0. If we set
swappiness==0, the kernel does not swap out completely (for global reclaim
until the amount of free pages and filebacked pages in a zone has been
reduced to something very very small (nr_free + nr_filebacked < high
watermark)).
Signed-off-by: Satoru Moriya <satoru.moriya@hds.com>
Acked-by: Minchan Kim <minchan@kernel.org>
Reviewed-by: Rik van Riel <riel@redhat.com>
Acked-by: Jerome Marchand <jmarchan@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2:
- Adjust context
- vmscan_swappiness() does not have a zone parameter]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cc37f75a9f upstream.
A Squashfs filesystem containing nothing but an empty directory,
although unusual and ultimately pointless, is still valid.
The directory_table >= next_table sanity check rejects these
filesystems as invalid because the directory_table is empty and
equal to next_table.
Signed-off-by: Phillip Lougher <phillip@squashfs.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3766054fff upstream.
There are some new video switch keys that used by newer machines.
0xA0 - SDSP HDMI only
0xA1 - SDSP LCD + HDMI
0xA2 - SDSP CRT + HDMI
0xA3 - SDSP TV + HDMI
But in Linux, there is no suitable userspace application to handle this,
so, mapping them all to KEY_SWITCHVIDEOMODE.
Signed-off-by: AceLan Kao <acelan.kao@canonical.com>
Signed-off-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4ea418b8b2 upstream.
A local static variable was declared as a pointer to a string
constant. We're assigning to the underlying memory, so it
needs to be an array instead.
Signed-off-by: Christopher Brannon <chris@the-brannons.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 38f8eefccf upstream.
kdb <-> kgdb transitioning does not work properly with this UART
driver because the get character routine loops indefinitely as opposed
to returning NO_POLL_CHAR per the expectation of the KDB I/O driver
API.
The symptom is a kernel hang when trying to switch debug modes.
Cc: Alan Cox <alan@linux.intel.com>
Signed-off-by: Jason Wessel <jason.wessel@windriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 76c9d8fe2c upstream.
Add yet another device to the list of Cypress barcode scanners
needing the CP_RDESC_SWAPPED_MIN_MAX quirk.
Signed-off-by: Lionel Vaux (iouri) <lionel.vaux@free.fr>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 483001c765 upstream.
blk_cleanup_queue() will call blk_drian_queue() to drain all the
requests before queue DEAD marking. If we reset the device before
blk_cleanup_queue() the drain would fail.
1) if the queue is stopped in do_virtblk_request() because device is
full, the q->request_fn() will not be called.
blk_drain_queue() {
while(true) {
...
if (!list_empty(&q->queue_head))
__blk_run_queue(q) {
if (queue is not stoped)
q->request_fn()
}
...
}
}
Do no reset the device before blk_cleanup_queue() gives the chance to
start the queue in interrupt handler blk_done().
2) In commit b79d866c8b, We abort requests
dispatched to driver before blk_cleanup_queue(). There is a race if
requests are dispatched to driver after the abort and before the queue
DEAD mark. To fix this, instead of aborting the requests explicitly, we
can just reset the device after after blk_cleanup_queue so that the
device can complete all the requests before queue DEAD marking in the
drain process.
Cc: Rusty Russell <rusty@rustcorp.com.au>
Cc: virtualization@lists.linux-foundation.org
Cc: kvm@vger.kernel.org
Signed-off-by: Asias He <asias@redhat.com>
Acked-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 02e2b12494 upstream.
del_gendisk() might not return due to failing to remove the
/sys/block/vda/serial sysfs entry when another thread (udev) is
trying to read it.
virtblk_remove()
vdev->config->reset() : guest will not kick us through interrupt
del_gendisk()
device_del()
kobject_del(): got stuck, sysfs entry ref count non zero
sysfs_open_file(): user space process read /sys/block/vda/serial
sysfs_get_active() : got sysfs entry ref count
dev_attr_show()
virtblk_serial_show()
blk_execute_rq() : got stuck, interrupt is disabled
request cannot be finished
This patch fixes it by calling del_gendisk() before we disable guest's
interrupt so that the request sent in virtblk_serial_show() will be
finished and del_gendisk() will success.
This fixes another race in hot-unplug process.
It is save to call del_gendisk(vblk->disk) before
flush_work(&vblk->config_work) which might access vblk->disk, because
vblk->disk is not freed until put_disk(vblk->disk).
Cc: virtualization@lists.linux-foundation.org
Cc: kvm@vger.kernel.org
Signed-off-by: Asias He <asias@redhat.com>
Acked-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b79d866c8b upstream.
If we reset the virtio-blk device before the requests already dispatched
to the virtio-blk driver from the block layer are finised, we will stuck
in blk_cleanup_queue() and the remove will fail.
blk_cleanup_queue() calls blk_drain_queue() to drain all requests queued
before DEAD marking. However it will never success if the device is
already stopped. We'll have q->in_flight[] > 0, so the drain will not
finish.
How to reproduce the race:
1. hot-plug a virtio-blk device
2. keep reading/writing the device in guest
3. hot-unplug while the device is busy serving I/O
Test:
~1000 rounds of hot-plug/hot-unplug test passed with this patch.
Changes in v3:
- Drop blk_abort_queue and blk_abort_request
- Use __blk_end_request_all to complete request dispatched to driver
Changes in v2:
- Drop req_in_flight
- Use virtqueue_detach_unused_buf to get request dispatched to driver
Signed-off-by: Asias He <asias@redhat.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4678d6f970 upstream.
Fix a theoretical race related to config work
handler: a config interrupt might happen
after we flush config work but before we
reset the device. It will then cause the
config work to run during or after reset.
Two problems with this:
- if this runs after device is gone we will get use after free
- access of config while reset is in progress is racy
(as layout is changing).
As a solution
1. flush after reset when we know there will be no more interrupts
2. add a flag to disable config access before reset
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d114a33387 upstream.
Send the entire DMI (SMBIOS) table to the /dev/random driver to
help seed its pools.
Signed-off-by: Tony Luck <tony.luck@intel.com>
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cbc96b7594 upstream.
Many platforms have per-machine instance data (serial numbers,
asset tags, etc.) squirreled away in areas that are accessed
during early system bringup. Mixing this data into the random
pools has a very high value in providing better random data,
so we should allow (and even encourage) architecture code to
call add_device_randomness() from the setup_arch() paths.
However, this limits our options for internal structure of
the random driver since random_initialize() is not called
until long after setup_arch().
Add a big fat comment to rand_initialize() spelling out
this requirement.
Suggested-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Tony Luck <tony.luck@intel.com>
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 330e0a01d5 upstream.
Matt Mackall stepped down as the /dev/random driver maintainer last
year, so Theodore Ts'o is taking back the /dev/random driver.
Cc: Matt Mackall <mpm@selenic.com>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 44e4360fa3 upstream.
/proc/sys/kernel/random/boot_id can be read concurrently by userspace
processes. If two (or more) user-space processes concurrently read
boot_id when sysctl_bootid is not yet assigned, a race can occur making
boot_id differ between the reads. Because the whole point of the boot id
is to be unique across a kernel execution, fix this by protecting this
operation with a spinlock.
Given that this operation is not frequently used, hitting the spinlock
on each call should not be an issue.
Signed-off-by: Mathieu Desnoyers <mathieu.desnoyers@efficios.com>
Cc: "Theodore Ts'o" <tytso@mit.edu>
Cc: Matt Mackall <mpm@selenic.com>
Signed-off-by: Eric Dumazet <eric.dumazet@gmail.com>
Cc: Greg Kroah-Hartman <greg@kroah.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8f321f853e upstream.
If remote device sends bogus RFC option with invalid length,
undefined options values are used. Fix this by using defaults when
remote misbehaves.
This also fixes the following warning reported by gcc 4.7.0:
net/bluetooth/l2cap_core.c: In function 'l2cap_config_rsp':
net/bluetooth/l2cap_core.c:3302:13: warning: 'rfc.max_pdu_size' may be used uninitialized in this function [-Wmaybe-uninitialized]
net/bluetooth/l2cap_core.c:3266:24: note: 'rfc.max_pdu_size' was declared here
net/bluetooth/l2cap_core.c:3298:25: warning: 'rfc.monitor_timeout' may be used uninitialized in this function [-Wmaybe-uninitialized]
net/bluetooth/l2cap_core.c:3266:24: note: 'rfc.monitor_timeout' was declared here
net/bluetooth/l2cap_core.c:3297:25: warning: 'rfc.retrans_timeout' may be used uninitialized in this function [-Wmaybe-uninitialized]
net/bluetooth/l2cap_core.c:3266:24: note: 'rfc.retrans_timeout' was declared here
net/bluetooth/l2cap_core.c:3295:2: warning: 'rfc.mode' may be used uninitialized in this function [-Wmaybe-uninitialized]
net/bluetooth/l2cap_core.c:3266:24: note: 'rfc.mode' was declared here
Signed-off-by: Szymon Janc <szymon.janc@tieto.com>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 676ce6d5ca upstream.
Commit 91f68c89d8 ("block: fix infinite loop in __getblk_slow")
is not good: a successful call to grow_buffers() cannot guarantee
that the page won't be reclaimed before the immediate next call to
__find_get_block(), which is why there was always a loop there.
Yesterday I got "EXT4-fs error (device loop0): __ext4_get_inode_loc:3595:
inode #19278: block 664: comm cc1: unable to read itable block" on console,
which pointed to this commit.
I've been trying to bisect for weeks, why kbuild-on-ext4-on-loop-on-tmpfs
sometimes fails from a missing header file, under memory pressure on
ppc G5. I've never seen this on x86, and I've never seen it on 3.5-rc7
itself, despite that commit being in there: bisection pointed to an
irrelevant pinctrl merge, but hard to tell when failure takes between
18 minutes and 38 hours (but so far it's happened quicker on 3.6-rc2).
(I've since found such __ext4_get_inode_loc errors in /var/log/messages
from previous weeks: why the message never appeared on console until
yesterday morning is a mystery for another day.)
Revert 91f68c89d8, restoring __getblk_slow() to how it was (plus
a checkpatch nitfix). Simplify the interface between grow_buffers()
and grow_dev_page(), and avoid the infinite loop beyond end of device
by instead checking init_page_buffers()'s end_block there (I presume
that's more efficient than a repeated call to blkdev_max_block()),
returning -ENXIO to __getblk_slow() in that case.
And remove akpm's ten-year-old "__getblk() cannot fail ... weird"
comment, but that is worrying: are all users of __getblk() really
now prepared for a NULL bh beyond end of device, or will some oops??
Signed-off-by: Hugh Dickins <hughd@google.com>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 61065a30af upstream.
While stressing the kernel with with failing allocations today, I hit the
following chain of events:
alloc_page_buffers():
bh = alloc_buffer_head(GFP_NOFS);
if (!bh)
goto no_grow; <= path taken
grow_dev_page():
bh = alloc_page_buffers(page, size, 0);
if (!bh)
goto failed; <= taken, consequence of the above
and then the failed path BUG()s the kernel.
The failure is inserted a litte bit artificially, but even then, I see no
reason why it should be deemed impossible in a real box.
Even though this is not a condition that we expect to see around every
time, failed allocations are expected to be handled, and BUG() sounds just
too much. As a matter of fact, grow_dev_page() can return NULL just fine
in other circumstances, so I propose we just remove it, then.
Signed-off-by: Glauber Costa <glommer@parallels.com>
Cc: Michal Hocko <mhocko@suse.cz>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3670e7e12e upstream.
Make sure that there is no doorbell messages left behind due to disabled
interrupts during inbound doorbell processing.
The most common case for this bug is loss of rionet JOIN messages in
systems with three or more rionet participants and MSI or MSI-X enabled.
As result, requests for packet transfers may finish with "destination
unreachable" error message.
This patch is applicable to kernel versions starting from v3.2.
Signed-off-by: Alexandre Bounine <alexandre.bounine@idt.com>
Cc: Matt Porter <mporter@kernel.crashing.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7dbfb315b2 upstream.
Correct the offset by subtracting 20 from tm_hour before taking the
modulo 12.
[ "Why 20?" I hear you ask. Or at least I did.
Here's the reason why: RS5C348_BIT_PM is 32, and is - stupidly -
included in the RS5C348_HOURS_MASK define. So it's really subtracting
out that bit to get "hour+12". But then because it does things modulo
12, it needs to add the 12 in again afterwards anyway.
This code is confused. It would be much clearer if RS5C348_HOURS_MASK
just didn't include the RS5C348_BIT_PM bit at all, then it wouldn't
need to do the silly subtract either.
Whatever. It's all just math, the end result is the same. - Linus ]
Reported-by: James Nute <newten82@gmail.com>
Tested-by: James Nute <newten82@gmail.com>
Signed-off-by: Atsushi Nemoto <anemo@mba.ocn.ne.jp>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7838f994b4 upstream.
On many of our larger systems, CPU 0 has had all of its IRQ resources
consumed before XPC loads. Worst cases on machines with multiple 10
GigE cards and multiple IB cards have depleted the entire first socket
of IRQs.
This patch makes selecting the node upon which IRQs are allocated (as
well as all the other GRU Message Queue structures) specifiable as a
module load param and has a default behavior of searching all nodes/cpus
for an available resources.
[akpm@linux-foundation.org: fix build: include cpu.h and module.h]
Signed-off-by: Robin Holt <holt@sgi.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit eb48c07146 upstream.
Each page mapped in a process's address space must be correctly
accounted for in _mapcount. Normally the rules for this are
straightforward but hugetlbfs page table sharing is different. The page
table pages at the PMD level are reference counted while the mapcount
remains the same.
If this accounting is wrong, it causes bugs like this one reported by
Larry Woodman:
kernel BUG at mm/filemap.c:135!
invalid opcode: 0000 [#1] SMP
CPU 22
Modules linked in: bridge stp llc sunrpc binfmt_misc dcdbas microcode pcspkr acpi_pad acpi]
Pid: 18001, comm: mpitest Tainted: G W 3.3.0+ #4 Dell Inc. PowerEdge R620/07NDJ2
RIP: 0010:[<ffffffff8112cfed>] [<ffffffff8112cfed>] __delete_from_page_cache+0x15d/0x170
Process mpitest (pid: 18001, threadinfo ffff880428972000, task ffff880428b5cc20)
Call Trace:
delete_from_page_cache+0x40/0x80
truncate_hugepages+0x115/0x1f0
hugetlbfs_evict_inode+0x18/0x30
evict+0x9f/0x1b0
iput_final+0xe3/0x1e0
iput+0x3e/0x50
d_kill+0xf8/0x110
dput+0xe2/0x1b0
__fput+0x162/0x240
During fork(), copy_hugetlb_page_range() detects if huge_pte_alloc()
shared page tables with the check dst_pte == src_pte. The logic is if
the PMD page is the same, they must be shared. This assumes that the
sharing is between the parent and child. However, if the sharing is
with a different process entirely then this check fails as in this
diagram:
parent
|
------------>pmd
src_pte----------> data page
^
other--------->pmd--------------------|
^
child-----------|
dst_pte
For this situation to occur, it must be possible for Parent and Other to
have faulted and failed to share page tables with each other. This is
possible due to the following style of race.
PROC A PROC B
copy_hugetlb_page_range copy_hugetlb_page_range
src_pte == huge_pte_offset src_pte == huge_pte_offset
!src_pte so no sharing !src_pte so no sharing
(time passes)
hugetlb_fault hugetlb_fault
huge_pte_alloc huge_pte_alloc
huge_pmd_share huge_pmd_share
LOCK(i_mmap_mutex)
find nothing, no sharing
UNLOCK(i_mmap_mutex)
LOCK(i_mmap_mutex)
find nothing, no sharing
UNLOCK(i_mmap_mutex)
pmd_alloc pmd_alloc
LOCK(instantiation_mutex)
fault
UNLOCK(instantiation_mutex)
LOCK(instantiation_mutex)
fault
UNLOCK(instantiation_mutex)
These two processes are not poing to the same data page but are not
sharing page tables because the opportunity was missed. When either
process later forks, the src_pte == dst pte is potentially insufficient.
As the check falls through, the wrong PTE information is copied in
(harmless but wrong) and the mapcount is bumped for a page mapped by a
shared page table leading to the BUG_ON.
This patch addresses the issue by moving pmd_alloc into huge_pmd_share
which guarantees that the shared pud is populated in the same critical
section as pmd. This also means that huge_pte_offset test in
huge_pmd_share is serialized correctly now which in turn means that the
success of the sharing will be higher as the racing tasks see the pud
and pmd populated together.
Race identified and changelog written mostly by Mel Gorman.
{akpm@linux-foundation.org: attempt to make the huge_pmd_share() comment comprehensible, clean up coding style]
Reported-by: Larry Woodman <lwoodman@redhat.com>
Tested-by: Larry Woodman <lwoodman@redhat.com>
Reviewed-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Michal Hocko <mhocko@suse.cz>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: David Gibson <david@gibson.dropbear.id.au>
Cc: Ken Chen <kenchen@google.com>
Cc: Cong Wang <xiyou.wangcong@gmail.com>
Cc: Hillf Danton <dhillf@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d8636a2717 upstream.
So we've had a fair few reports of fbcon handover breakage between
efi/vesafb and i915 surface recently, so I dedicated a couple of
days to finding the problem.
Essentially the last thing we saw was the conflicting framebuffer
message and that was all.
So after much tracing with direct netconsole writes (printks
under console_lock not so useful), I think I found the race.
Thread A (driver load) Thread B (timer thread)
unbind_con_driver -> |
bind_con_driver -> |
vc->vc_sw->con_deinit -> |
fbcon_deinit -> |
console_lock() |
| |
| fbcon_flashcursor timer fires
| console_lock() <- blocked for A
|
|
fbcon_del_cursor_timer ->
del_timer_sync
(BOOM)
Of course because all of this is under the console lock,
we never see anything, also since we also just unbound the active
console guess what we never see anything.
Hopefully this fixes the problem for anyone seeing vesafb->kms
driver handoff.
v1.1: add comment suggestion from Alan.
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 676bc2e1e4 upstream.
This reverts commit d1c7871ddb.
ttm_bo_init() destroys the BO on failure. So this patch makes
the retry path work with freed memory. This ends up causing
kernel panics when this path is hit.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d10f27a750 upstream.
The rpc server tries to ensure that there will be room to send a reply
before it receives a request.
It does this by tracking, in xpt_reserved, an upper bound on the total
size of the replies that is has already committed to for the socket.
Currently it is adding in the estimate for a new reply *before* it
checks whether there is space available. If it finds that there is not
space, it then subtracts the estimate back out.
This may lead the subsequent svc_xprt_enqueue to decide that there is
space after all.
The results is a svc_recv() that will repeatedly return -EAGAIN, causing
server threads to loop without doing any actual work.
Reported-by: Michael Tokarev <mjt@tls.msk.ru>
Tested-by: Michael Tokarev <mjt@tls.msk.ru>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f06f00a24d upstream.
svc_tcp_sendto sets XPT_CLOSE if we fail to transmit the entire reply.
However, the XPT_CLOSE won't be acted on immediately. Meanwhile other
threads could send further replies before the socket is really shut
down. This can manifest as data corruption: for example, if a truncated
read reply is followed by another rpc reply, that second reply will look
to the client like further read data.
Symptoms were data corruption preceded by svc_tcp_sendto logging
something like
kernel: rpc-srv/tcp: nfsd: sent only 963696 when sending 1048708 bytes - shutting down socket
Reported-by: Malahal Naineni <malahal@us.ibm.com>
Tested-by: Malahal Naineni <malahal@us.ibm.com>
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit be1e44441a upstream.
Examination of svc_tcp_clear_pages shows that it assumes sk_tcplen is
consistent with sk_pages[] (in particular, sk_pages[n] can't be NULL if
sk_tcplen would lead us to expect n pages of data).
svc_tcp_restore_pages zeroes out sk_pages[] while leaving sk_tcplen.
This is OK, since both functions are serialized by XPT_BUSY. However,
that means the inconsistency must be repaired before dropping XPT_BUSY.
Therefore we should be ensuring that svc_tcp_save_pages repairs the
problem before exiting svc_tcp_recv_record on error.
Symptoms were a BUG() in svc_tcp_clear_pages.
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0866004304 upstream.
If the rpc call to NFS3PROC_FSINFO fails, then we need to report that
error so that the mount fails. Otherwise we can end up with a
superblock with completely unusable values for block sizes, maxfilesize,
etc.
Reported-by: Yuanming Chen <hikvision_linux@163.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 211fa4fc4e upstream.
Return a number of bytes read in radeon_atrm_get_bios_chunk() and
properly check this value in radeon_atrm_get_bios().
If radeon_atrm_get_bios_chunk() read less bytes then were requested,
it means that it finished reading bios data.
Prior to this patch, condition in radeon_atrm_get_bios() was always
equivalent to "if (ATRM_BIOS_PAGE <= 0)", so it was always false,
thus radeon_atrm_get_bios() was trying to read past the bios data
wasting boot time.
On my lenovo ideapad u455 laptop this patch drops bios reading time
from ~5.5s to ~1.5s.
Signed-off-by: Igor Murzov <e-mail@date.by>
Reviewed-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4f81f98676 upstream.
We need it in the radeon drm module to fetch
and verify the vbios image on UEFI systems.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 52e9b39d9a upstream.
There is a more recent APU stepping with a new PCI ID
shipping in the same board by Fujitsu which needs the
same quirk to correctly mark the back plane connectors.
Signed-off-by: Tvrtko Ursulin <tvrtko.ursulin@onelan.co.uk>
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 72d3eb13b5 upstream.
This netconsole_target_put() is obviously redundant, and it
causes a kernel segfault when removing a bridge device which has
netconsole running on it.
This is caused by:
commit 8d8fc29d02
Author: Amerigo Wang <amwang@redhat.com>
Date: Thu May 19 21:39:10 2011 +0000
netpoll: disable netpoll when enslave a device
Cc: David Miller <davem@davemloft.net>
Signed-off-by: Cong Wang <amwang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 67a806d949 upstream.
The following build error occurred during an alpha build:
net/core/sock.c:274:36: error: initializer element is not constant
Dave Anglin says:
> Here is the line in sock.i:
>
> struct static_key memalloc_socks = ((struct static_key) { .enabled =
> ((atomic_t) { (0) }) });
The above line contains two compound literals. It also uses a designated
initializer to initialize the field enabled. A compound literal is not a
constant expression.
The location of the above statement isn't fully clear, but if a compound
literal occurs outside the body of a function, the initializer list must
consist of constant expressions.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Fengguang Wu <fengguang.wu@intel.com>
Signed-off-by: Michael Cree <mcree@orcon.net.nz>
Acked-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a2fa3ccd7b upstream.
Currently we export SOCK_NONBLOCK to user space but that conflicts with
the definition from glibc leading to compilation errors in user programs
(e.g. see Debian bug #658460).
The generic socket.h restricts the definition of SOCK_NONBLOCK to the
kernel, as does the MIPS specific socket.h, so let's do the same on
Alpha.
Signed-off-by: Michael Cree <mcree@orcon.net.nz>
Acked-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 99f347caa4 upstream.
If a device specifies zero endpoints in its interface descriptor,
the kernel oopses in acm_probe(). Even though that's clearly an
invalid descriptor, we should test wether we have all endpoints.
This is especially bad as this oops can be triggered by just
plugging a USB device in.
Signed-off-by: Sven Schnelle <svens@stackframe.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b9c4167cbb upstream.
This structure needs to always stick around, even if CONFIG_HOTPLUG
is disabled, otherwise we can oops when trying to probe a device that
was added after the structure is thrown away.
Thanks to Fengguang Wu and Bjørn Mork for tracking this issue down.
Reported-by: Fengguang Wu <fengguang.wu@intel.com>
Reported-by: Bjørn Mork <bjorn@mork.no>
CC: Christian Lamparter <chunkeey@googlemail.com>
CC: "John W. Linville" <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e694d51888 upstream.
This structure needs to always stick around, even if CONFIG_HOTPLUG
is disabled, otherwise we can oops when trying to probe a device that
was added after the structure is thrown away.
Thanks to Fengguang Wu and Bjørn Mork for tracking this issue down.
Reported-by: Fengguang Wu <fengguang.wu@intel.com>
Reported-by: Bjørn Mork <bjorn@mork.no>
CC: Hans de Goede <hdegoede@redhat.com>
CC: Mauro Carvalho Chehab <mchehab@infradead.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ccf795847a upstream.
Currently the microphone input source is not selectable as while there is
a DAPM widget it's not connected to anything so it won't be properly
instantiated. Add something more correct for the input structure to get
things going, even though it's not hooked into the rest of the routing
map and so won't actually achieve anything except allowing the relevant
register bits to be written.
Reported-by: Christop Fritz <chf.fritz@googlemail.com>
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 58a34de7b1 upstream.
The power.deferred_resume can only be set if the runtime PM status
of device is RPM_SUSPENDING and it should be cleared after its
status has been changed, regardless of whether or not the runtime
suspend has been successful. However, it only is cleared on
suspend failure, while it may remain set on successful suspend and
is happily leaked to rpm_resume() executed in that case.
That shouldn't happen, so if power.deferred_resume is set in
rpm_suspend() after the status has been changed to RPM_SUSPENDED,
clear it before calling rpm_resume(). Then, it doesn't need to be
cleared before changing the status to RPM_SUSPENDING any more,
because it's always cleared after the status has been changed to
either RPM_SUSPENDED (on success) or RPM_ACTIVE (on failure).
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Acked-by: Alan Stern <stern@rowland.harvard.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7f321c26c0 upstream.
For devices whose power.no_callbacks flag is set, rpm_resume()
should return 1 if the device's parent is already active, so that
the callers of pm_runtime_get() don't think that they have to wait
for the device to resume (asynchronously) in that case (the core
won't queue up an asynchronous resume in that case, so there's
nothing to wait for anyway).
Modify the code accordingly (and make sure that an idle notification
will be queued up on success, even if 1 is to be returned).
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Acked-by: Alan Stern <stern@rowland.harvard.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0548bbb853 upstream.
Commit 8aeb00ff85: "ext4: fix overhead calculation used by
ext4_statfs()" introduced a O(n**2) calculation which makes very large
file systems take forever to mount. Fix this with an optimization for
non-bigalloc file systems. (For bigalloc file systems the overhead
needs to be set in the the superblock.)
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d0e27c88d7 upstream.
I am hitting this bug when the target is low in memory that fails the
alloc_page() for the newly submitted command. This is a sort of off-by-one
bug causing NULL pointer dereference in __free_page() since 'i' here is
really the counter of total pages that have been successfully allocated here.
Signed-off-by: Yi Zou <yi.zou@intel.com>
Cc: Andy Grover <agrover@redhat.com>
Cc: Nicholas Bellinger <nab@linux-iscsi.org>
Cc: Open-FCoE.org <devel@open-fcoe.org>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 425e776d93 upstream.
This allows distros to remove the line from their modprobe
configuration.
Signed-off-by: Bryan Schumaker <bjschuma@netapp.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 667a5313ec upstream.
commit 27a7b260f7
md: Fix handling for devices from 2TB to 4TB in 0.90 metadata.
changed 0.90 metadata handling to truncated size to 4TB as that is
all that 0.90 can record.
However for RAID0 and Linear, 0.90 doesn't need to record the size, so
this truncation is not needed and causes working arrays to become too small.
So avoid the truncation for RAID0 and Linear
This bug was introduced in 3.1 and is suitable for any stable kernels
from then onwards.
As the offending commit was tagged for 'stable', any stable kernel
that it was applied to should also get this patch. That includes
at least 2.6.32, 2.6.33 and 3.0. (Thanks to Ben Hutchings for
providing that list).
Signed-off-by: Neil Brown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 276bdb82de upstream.
ccid_hc_rx_getsockopt() and ccid_hc_tx_getsockopt() might be called with
a NULL ccid pointer leading to a NULL pointer dereference. This could
lead to a privilege escalation if the attacker is able to map page 0 and
prepare it with a fake ccid_ops pointer.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Cc: Gerrit Renker <gerrit@erg.abdn.ac.uk>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0b68c8e2c3 upstream.
Commit dbf0e4c (PCI: EHCI: fix crash during suspend on ASUS
computers) added a workaround for an ASUS suspend issue related to
USB EHCI and a bug in a number of ASUS BIOSes that attempt to shut
down the EHCI controller during system suspend if its PCI command
register doesn't contain 0 at that time.
It turns out that the same workaround is necessary in the analogous
hibernation code path, so add it.
References: https://bugzilla.kernel.org/show_bug.cgi?id=45811
Reported-and-tested-by: Oleksij Rempel <bug-track@fisher-privat.net>
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Bjorn Helgaas <bhelgaas@google.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e68726ff72 upstream.
Userspace can pass weird create mode in open(2) that we canonicalize to
"(mode & S_IALLUGO) | S_IFREG" in vfs_create().
The problem is that we use the uncanonicalized mode before calling vfs_create()
with unforseen consequences.
So do the canonicalization early in build_open_flags().
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Tested-by: Richard W.M. Jones <rjones@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a2140fc0cb upstream.
Refcounting of fsnotify_mark in audit tree is broken. E.g:
refcount
create_chunk
alloc_chunk 1
fsnotify_add_mark 2
untag_chunk
fsnotify_get_mark 3
fsnotify_destroy_mark
audit_tree_freeing_mark 2
fsnotify_put_mark 1
fsnotify_put_mark 0
via destroy_list
fsnotify_mark_destroy -1
This was reported by various people as triggering Oops when stopping auditd.
We could just remove the put_mark from audit_tree_freeing_mark() but that would
break freeing via inode destruction. So this patch simply omits a put_mark
after calling destroy_mark or adds a get_mark before.
The additional get_mark is necessary where there's no other put_mark after
fsnotify_destroy_mark() since it assumes that the caller is holding a reference
(or the inode is keeping the mark pinned, not the case here AFAICS).
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Reported-by: Valentin Avram <aval13@gmail.com>
Reported-by: Peter Moody <pmoody@google.com>
Acked-by: Eric Paris <eparis@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0fe33aae0e upstream.
Don't do free_chunk() after fsnotify_add_mark(). That one does a delayed unref
via the destroy list and this results in use-after-free.
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Acked-by: Eric Paris <eparis@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 35a38556d9 upstream.
eDP is tons of fun. It turns out that at least the new MacBook Air 5,1
model absolutely doesn't like the new force vdd dance we've introduced
in
commit 6cb49835da
Author: Daniel Vetter <daniel.vetter@ffwll.ch>
Date: Sun May 20 17:14:50 2012 +0200
drm/i915: enable vdd when switching off the eDP panel
But that patch also tried to fix some neat edp sequence issue with the
force_vdd timings. Closer inspection reveals that we've raised
force_vdd only to do the aux channel communication dp_sink_dpms. If we
move the edp_panel_off below that, we don't need any force_vdd for the
disable sequence, which makes the Air happy.
Unfortunately the reporter of the original bug that the above commit
fixed is travelling, so we can't test whether this regresses things.
But my theory is that since we don't check for any power-off ->
force_vdd-on delays in edp_panel_vdd_on, this was the actual
root-cause of this failure. With that force_vdd dance completely
eliminated, I'm hopeful the original bug stays fixed, too.
For reference the old bug, which hopefully doesn't get broken by this:
https://bugzilla.kernel.org/show_bug.cgi?id=43163
In any case, regression fixers win over plain bugfixes, so this needs
to go in asap.
v2: The crucial pieces seems to be to clear the force_vdd flag
uncoditionally, too, in edp_panel_off. Looks like this is left behind
by the firmware somehow.
v3: The Apple firmware seems to switch off the panel on it's own, hence
we still need to keep force_vdd on, but properly clear it when switching
the panel off.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=45671
Tested-by: Roberto Romer <sildurin@gmail.com>
Tested-by: Daniel Wagner <wagi@monom.org>
Tested-by: Keith Packard <keithp@keithp.com>
Cc: Keith Packard <keithp@keithp.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e1352fde56 upstream.
ath_rx_tasklet() calls ath9k_rx_skb_preprocess() and ath9k_rx_skb_postprocess()
in a loop over the received frames. The decrypt_error flag is
initialized to false
just outside ath_rx_tasklet() loop. ath9k_rx_accept(), called by
ath9k_rx_skb_preprocess(),
only sets decrypt_error to true and never to false.
Then ath_rx_tasklet() calls ath9k_rx_skb_postprocess() and passes
decrypt_error to it.
So, after a decryption error, in ath9k_rx_skb_postprocess(), we can
have a leftover value
from another processed frame. In that case, the frame will not be marked with
RX_FLAG_DECRYPTED even if it is decrypted correctly.
When using CCMP encryption this issue can lead to connection stuck
because of CCMP
PN corruption and a waste of CPU time since mac80211 tries to decrypt an already
deciphered frame with ieee80211_aes_ccm_decrypt.
Fix the issue initializing decrypt_error flag at the begging of the
ath_rx_tasklet() loop.
Signed-off-by: Lorenzo Bianconi <lorenzo.bianconi83@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0bce9c46bf upstream.
ARM recently moved to asm-generic/mutex-xchg.h for its mutex
implementation after the previous implementation was found to be missing
some crucial memory barriers. However, this has revealed some problems
running hackbench on SMP platforms due to the way in which the
MUTEX_SPIN_ON_OWNER code operates.
The symptoms are that a bunch of hackbench tasks are left waiting on an
unlocked mutex and therefore never get woken up to claim it. This boils
down to the following sequence of events:
Task A Task B Task C Lock value
0 1
1 lock() 0
2 lock() 0
3 spin(A) 0
4 unlock() 1
5 lock() 0
6 cmpxchg(1,0) 0
7 contended() -1
8 lock() 0
9 spin(C) 0
10 unlock() 1
11 cmpxchg(1,0) 0
12 unlock() 1
At this point, the lock is unlocked, but Task B is in an uninterruptible
sleep with nobody to wake it up.
This patch fixes the problem by ensuring we put the lock into the
contended state if we fail to acquire it on the fastpath, ensuring that
any blocked waiters are woken up when the mutex is released.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Cc: Arnd Bergmann <arnd@arndb.de>
Cc: Chris Mason <chris.mason@fusionio.com>
Cc: Ingo Molnar <mingo@elte.hu>
Reviewed-by: Nicolas Pitre <nico@linaro.org>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/n/tip-6e9lrw2avczr0617fzl5vqb8@git.kernel.org
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bea6832cc8 upstream.
On architectures where cputime_t is 64 bit type, is possible to trigger
divide by zero on do_div(temp, (__force u32) total) line, if total is a
non zero number but has lower 32 bit's zeroed. Removing casting is not
a good solution since some do_div() implementations do cast to u32
internally.
This problem can be triggered in practice on very long lived processes:
PID: 2331 TASK: ffff880472814b00 CPU: 2 COMMAND: "oraagent.bin"
#0 [ffff880472a51b70] machine_kexec at ffffffff8103214b
#1 [ffff880472a51bd0] crash_kexec at ffffffff810b91c2
#2 [ffff880472a51ca0] oops_end at ffffffff814f0b00
#3 [ffff880472a51cd0] die at ffffffff8100f26b
#4 [ffff880472a51d00] do_trap at ffffffff814f03f4
#5 [ffff880472a51d60] do_divide_error at ffffffff8100cfff
#6 [ffff880472a51e00] divide_error at ffffffff8100be7b
[exception RIP: thread_group_times+0x56]
RIP: ffffffff81056a16 RSP: ffff880472a51eb8 RFLAGS: 00010046
RAX: bc3572c9fe12d194 RBX: ffff880874150800 RCX: 0000000110266fad
RDX: 0000000000000000 RSI: ffff880472a51eb8 RDI: 001038ae7d9633dc
RBP: ffff880472a51ef8 R8: 00000000b10a3a64 R9: ffff880874150800
R10: 00007fcba27ab680 R11: 0000000000000202 R12: ffff880472a51f08
R13: ffff880472a51f10 R14: 0000000000000000 R15: 0000000000000007
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#7 [ffff880472a51f00] do_sys_times at ffffffff8108845d
#8 [ffff880472a51f40] sys_times at ffffffff81088524
#9 [ffff880472a51f80] system_call_fastpath at ffffffff8100b0f2
RIP: 0000003808caac3a RSP: 00007fcba27ab6d8 RFLAGS: 00000202
RAX: 0000000000000064 RBX: ffffffff8100b0f2 RCX: 0000000000000000
RDX: 00007fcba27ab6e0 RSI: 000000000076d58e RDI: 00007fcba27ab6e0
RBP: 00007fcba27ab700 R8: 0000000000000020 R9: 000000000000091b
R10: 00007fcba27ab680 R11: 0000000000000202 R12: 00007fff9ca41940
R13: 0000000000000000 R14: 00007fcba27ac9c0 R15: 00007fff9ca41940
ORIG_RAX: 0000000000000064 CS: 0033 SS: 002b
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/20120808092714.GA3580@redhat.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
[bwh: Backported to 3.2:
- Adjust filename
- Most conversions in the original code are implicit]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4344b813f1 upstream.
This has originally been introduced to not oversubscribe the dp links
in
commit 885a5fb5b1
Author: Zhenyu Wang <zhenyuw@linux.intel.com>
Date: Tue Jan 12 05:38:31 2010 +0800
drm/i915: fix pixel color depth setting on eDP
Since then we've fixed up the dp link bandwidth calculation code and
should now automatically fall back to 6bpc dithering. So this is
unnecessary.
Furthermore it seems to break the new MacbookPro with retina display,
hence let's just rip this out.
Reported-by: Benoit Gschwind <gschwind@gnu-log.net>
Cc: Benoit Gschwind <gschwind@gnu-log.net>
Cc: Francois Rigaut <frigaut@gmail.com>
Cc: Greg KH <gregkh@linuxfoundation.org>
Tested-by: Benoit Gschwind <gschwind@gnu-log.net>
Tested-by: Bernhard Froemel <froemel at vmars tuwien.ac.at>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
--
Testing feedback highgly welcome, and thanks for Benoit for finding
out that the bpc computations are busted.
-Daniel
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 730a8128cd upstream.
Commit 5a783cbc48 ("ARM: 7478/1: errata: extend workaround for erratum
#720789") added workarounds for erratum #720789 to the range TLB
invalidation functions with the observation that the erratum only
affects SMP platforms. However, when running an SMP_ON_UP kernel on a
uniprocessor platform we must take care to preserve the ASID as the
workaround is not required.
This patch ensures that we don't set the ASID to 0 when flushing the TLB
on such a system, preserving the original behaviour with the workaround
disabled.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f5f2025ef3 upstream.
Page migration encodes the pfn in the offset field of a swp_entry_t.
For LPAE, we support physical addresses of up to 36 bits (due to
sparsemem limitations with the size of page flags), requiring 24 bits
to represent a pfn. A further 3 bits are used to encode a swp_entry into
a pte, leaving 5 bits for the type field. Furthermore, the core code
defines MAX_SWAPFILES_SHIFT as 5, so the additional type bit does not
get used.
This patch reduces the width of the type field to 5 bits, allowing us
to create up to 31 swapfiles of 64GB each.
Reviewed-by: Catalin Marinas <catalin.marinas@arm.com>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3d9fb0038a upstream.
VFPv4 support depends on the VFPv3 context save/restore code, so only
advertise support in the hwcaps if the kernel can actually handle it.
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b1b552a69b upstream.
This patch fixes an issue introduced by patch:
72c973d usb: gadget: add usb_endpoint_descriptor to struct usb_ep
Without this patch we see a kworker taking 100% CPU, after this sequence:
- Connect gadget to a windows host
- load g_ether
- ifconfig up <ip>; ifconfig down; ifconfig up
- ping <windows host>
The "ifconfig down" results in calling eth_stop(), which will call
usb_ep_disable() and, if the carrier is still ok, usb_ep_enable():
usb_ep_disable(link->in_ep);
usb_ep_disable(link->out_ep);
if (netif_carrier_ok(net)) {
usb_ep_enable(link->in_ep);
usb_ep_enable(link->out_ep);
}
The ep should stay enabled, but will not, as ep_disable set the desc
pointer to NULL, therefore the subsequent ep_enable will fail. This leads
to permanent rescheduling of the eth_work() worker as usb_ep_queue()
(called by the worker) will fail due to the unconfigured endpoint.
We fix this issue by saving the ep descriptors and re-assign them before
usb_ep_enable().
Cc: Tatyana Brokhman <tlinder@codeaurora.org>
Signed-off-by: Michael Grzeschik <m.grzeschik@pengutronix.de>
Signed-off-by: Marc Kleine-Budde <mkl@pengutronix.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5c263b92f8 upstream.
* Use the buffer content length as opposed to the total buffer size. This can
be a real problem when using the mos7840 as a usb serial-console as all
kernel output is truncated during boot.
Signed-off-by: Mark Ferrell <mferrell@uplogix.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ee6f827df9 upstream.
In this patch, we add new declarations into option.c to support the new
interfaces of Huawei Data Card devices. And at the same time, remove the
redundant declarations from option.c.
Signed-off-by: fangxiaozhi <huananhu@huawei.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d81a5d1956 upstream.
A lot of Broadcom Bluetooth devices provides vendor specific interface
class and we are getting flooded by patches adding new device support.
This change will help us enable support for any other Broadcom with vendor
specific device that arrives in the future.
Only the product id changes for those devices, so this macro would be
perfect for us:
{ USB_VENDOR_AND_INTERFACE_INFO(0x0a5c, 0xff, 0x01, 0x01) }
Signed-off-by: Marcel Holtmann <marcel@holtmann.org>
Signed-off-by: Gustavo Padovan <gustavo.padovan@collabora.co.uk>
Acked-by: Henrik Rydberg <rydberg@bitmath.se>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5cb7df2b2d upstream.
Gary reports that with recent kernels, he notices more xHCI driver
warnings:
xhci_hcd 0000:03:00.0: WARN Successful completion on short TX: needs XHCI_TRUST_TX_LENGTH quirk?
We think his Etron xHCI host controller may have the same buggy behavior
as the Fresco Logic xHCI host. When a short transfer is received, the
host will mark the transfer as successfully completed when it should be
marking it with a short completion.
Fix this by turning on the XHCI_TRUST_TX_LENGTH quirk when the Etron
host is discovered. Note that Gary has revision 1, but if Etron fixes
this bug in future revisions, the quirk will have no effect.
This patch should be backported to kernels as old as 2.6.36, that
contain a backported version of commit
1530bbc627 "xhci: Add new short TX quirk
for Fresco Logic host."
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Reported-by: Gary E. Miller <gem@rellim.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 22ceac1912 upstream.
The NEC/Renesas 720201 xHCI host controller does not complete its reset
within 250 milliseconds. In fact, it takes about 9 seconds to reset the
host controller, and 1 second for the host to be ready for doorbell
rings. Extend the reset and CNR polling timeout to 10 seconds each.
This patch should be backported to kernels as old as 2.6.31, that
contain the commit 66d4eadd8d "USB: xhci:
BIOS handoff and HW initialization."
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Reported-by: Edwin Klein Mentink <e.kleinmentink@zonnet.nl>
[bwh: Backported to 3.2: result of second handshake call is returned directly]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fb6ccff667 upstream.
Commit 7572777eef attempted to verify that
the total iovec from the client doesn't overflow iov_length() but it
only checked the first element. The iovec could still overflow by
starting with a small element. The obvious fix is to check all the
elements.
The overflow case doesn't look dangerous to the kernel as the copy is
limited by the length after the overflow. This fix restores the
intention of returning an error instead of successfully copying less
than the iovec represented.
I found this by code inspection. I built it but don't have a test case.
I'm cc:ing stable because the initial commit did as well.
Signed-off-by: Zach Brown <zab@redhat.com>
Signed-off-by: Miklos Szeredi <mszeredi@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7e731bc9a1 upstream.
Commit 03179fe923 introduced a kmemcheck complaint in
ext4_da_get_block_prep() because we save and restore
ei->i_da_metadata_calc_last_lblock even though it is left
uninitialized in the case where i_da_metadata_calc_len is zero.
This doesn't hurt anything, but silencing the kmemcheck complaint
makes it easier for people to find real bugs.
Addresses https://bugzilla.kernel.org/show_bug.cgi?id=45631
(which is marked as a regression).
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8554116e17 upstream.
we have encountered a bug whereby reading a lot of files (copying
fedora's /bin) from a pNFS mount and hitting Ctrl+C in the middle caused
a general protection fault in xdr_shrink_bufhead. this function is
called when decoding the response from LAYOUTGET. the decoding is done
by a worker thread, and the caller of LAYOUTGET waits for the worker
thread to complete.
hitting Ctrl+C caused the synchronous wait to end and the next thing the
caller does is to free the pages, so when the worker thread calls
xdr_shrink_bufhead, the pages are gone. therefore, the cleanup of these
pages has been moved to nfs4_layoutget_release.
Signed-off-by: Idan Kedar <idank@tonian.com>
Signed-off-by: Benny Halevy <bhalevy@tonian.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3dd4765fce upstream.
...and ensure that we tear down the nfs_commit_data cache too when
unloading the module.
Cc: Bryan Schumaker <bjschuma@netapp.com>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: drop the nfs_cdata_cachep cleanup; it doesn't exist]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 81ee8fb6b5 upstream.
It seems we can not update the crtc scanout address. After disabling
crtc, update to base address do not take effect after crtc being
reenable leading to at least frame being scanout from the old crtc
base address. Disabling crtc display request lead to same behavior.
So after changing the vram address if we don't keep crtc disabled
we will have the GPU trying to read some random system memory address
with some iommu this will broke the crtc engine and will lead to
broken display and iommu error message.
So to avoid this, disable crtc. For flicker less boot we will need
to avoid moving the vram start address.
This patch should also fix :
https://bugs.freedesktop.org/show_bug.cgi?id=42373
Signed-off-by: Jerome Glisse <jglisse@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e858712185 upstream.
The native 31 bit and the compat behaviour for the mmap system calls differ:
In native 31 bit mode the passed in address for the mmap system call will be
unmodified passed to sys_mmap_pgoff().
In compat mode however the passed in address will be modified with
compat_ptr() which masks out the most significant bit.
The result is that in native 31 bit mode each mmap request (with MAP_FIXED)
will fail where the most significat bit is set, while in compat mode it
may succeed.
This odd behaviour was introduced with d3815898 "[S390] mmap: add missing
compat_ptr conversion to both mmap compat syscalls".
To restore a consistent behaviour accross native and compat mode this
patch functionally reverts the above mentioned commit.
Signed-off-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f01db988ef upstream.
I have seen a number of "blt ring initialization failed" messages
where the ctl or start registers are not the correct value. Upon further
inspection, if the code just waited a little bit, it would read the
correct value. Adding the wait_for to these reads should eliminate the
issue.
Signed-off-by: Sean Paul <seanpaul@chromium.org>
Reviewed-by: Ben Widawsky <ben@bwidawsk.net>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4eef6cbfcc upstream.
The EETI touchscreen asserts its IRQ line as soon as it has data in its
internal buffers. The line is automatically deasserted once all data has
been read via I2C. Hence, the driver has to monitor the GPIO line and
cannot simply rely on the interrupt handler reception.
In the current implementation of the driver, irq_to_gpio() is used to
determine the GPIO number from the i2c_client's IRQ value.
As irq_to_gpio() is not available on all platforms, this patch changes
this and makes the driver ignore the passed in IRQ. Instead, a GPIO is
added to the platform_data struct and gpio_to_irq is used to derive the
IRQ from that GPIO. If this fails, bail out. The driver is only able to
work in environments where the touchscreen GPIO can be mapped to an
IRQ.
Without this patch, building raumfeld_defconfig results in:
drivers/input/touchscreen/eeti_ts.c: In function 'eeti_ts_irq_active':
drivers/input/touchscreen/eeti_ts.c:65:2: error: implicit declaration of function 'irq_to_gpio' [-Werror=implicit-function-declaration]
Signed-off-by: Daniel Mack <zonque@gmail.com>
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Cc: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Cc: Sven Neumann <s.neumann@raumfeld.com>
Cc: linux-input@vger.kernel.org
Cc: Haojian Zhuang <haojian.zhuang@gmail.com>
[bwh: Backported to 3.2: raumfeld_controller_i2c_board_info.irq was
initialised using gpio_to_irq(), but this doesn't seem to matter]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 59ee93a528 upstream.
The irq_to_gpio function was removed from the pxa platform
in linux-3.2, and this driver has been broken since.
There is actually no in-tree user of this driver that adds
this platform device, but the driver can and does get enabled
on some platforms.
Without this patch, building ezx_defconfig results in:
drivers/mfd/ezx-pcap.c: In function 'pcap_isr_work':
drivers/mfd/ezx-pcap.c:205:2: error: implicit declaration of function 'irq_to_gpio' [-Werror=implicit-function-declaration]
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Haojian Zhuang <haojian.zhuang@gmail.com>
Cc: Samuel Ortiz <sameo@linux.intel.com>
Cc: Daniel Ribeiro <drwyrm@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e9fc83cb2e upstream.
This computer is confirmed working with model=auto on kernel 3.2.
Also, parsing fails with hda-emu with the current model.
Signed-off-by: David Henningsson <david.henningsson@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c8415a48fc upstream.
As with the ThinkPad Models X230 Tablet and T530 the X230 needs a qurik to
correctly set up the pins for the dock port.
Signed-off-by: Felix Kaechele <felix@fetzig.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 50e2a30cf6 upstream.
There's a bug that causes the rate scaling to get stuck
when it has to use single-stream rates with a peer that
can do GF and SGI; the two are incompatible so we can't
use them together, but that causes the algorithm to not
work at all, it always rejects updates.
Disable greenfield for now to prevent that problem.
Reviewed-by: Emmanuel Grumbach <emmanuel.grumbach@intel.com>
Tested-by: Cesar Eduardo Barros <cesarb@cesarb.net>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust filename]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1f6fc43e62 upstream.
libertas currently calls cfg80211_disconnected() when it is being
brought down. This causes an event to be allocated, but since the
wdev is already removed from the rdev by the time that the event
processing work executes, the event is never processed or freed.
http://article.gmane.org/gmane.linux.kernel.wireless.general/95666
Fix this leak, and other possible situations, by processing the event
queue when a device is being unregistered. Thanks to Johannes Berg for
the suggestion.
Signed-off-by: Daniel Drake <dsd@laptop.org>
Reviewed-by: Johannes Berg <johannes@sipsolutions.net>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4407be6ba2 upstream.
Add a model/fixup string "lenovo-dock", for Thinkpad T430s, to allow
sound in docking station.
Tested on Lenovo T430s with ThinkPad Mini Dock Plus Series 3
Signed-off-by: Philipp A. Mohrenweiser <phiamo@googlemail.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3bed491c8d upstream.
The CONFIG_DEFAULT_MMAP_MIN_ADDR was set to 65536 in mxs_defconfig,
this caused severe breakage of userland applications since the upper
limit for ARM is 32768. By default CONFIG_DEFAULT_MMAP_MIN_ADDR is
set to 4096 and can also be changed via /proc/sys/vm/mmap_min_addr
if needed.
Quoting Russell King [1]:
"4096 is also fine for ARM too. There's not much point in having
defconfigs change it - that would just be pure noise in the config
files."
the CONFIG_DEFAULT_MMAP_MIN_ADDR can be removed from the defconfig
altogether.
This problem was introduced by commit cde7c41 (ARM: configs: add
defconfig for mach-mxs).
[1] http://marc.info/?l=linux-arm-kernel&m=134401593807820&w=2
Signed-off-by: Marek Vasut <marex@denx.de>
Cc: Russell King <linux@arm.linux.org.uk>
Cc: Wolfgang Denk <wd@denx.de>
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d4e5979c0d upstream.
AR1111 is same as AR9485. The h/w
difference between them is quite insignificant,
Felix suggests only very few baseband features
may not be available in AR1111. The h/w code for
AR9485 is already present, so AR1111 should
work fine with the addition of its PID/VID.
Cc: Felix Bitterli <felixb@qca.qualcomm.com>
Reported-by: Tim Bentley <Tim.Bentley@Gmail.com>
Signed-off-by: Mohammed Shafi Shajakhan <mohammed@qca.qualcomm.com>
Tested-by: Tim Bentley <Tim.Bentley@Gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dd4c9260e7 upstream.
The mesh path timer needs to be canceled when
leaving the mesh as otherwise it could fire
after the interface has been removed already.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Based on commit fee84b079d upstream.
Intercept RDPMC and forward it to the PMU emulation code.
Newer vmx support will only allow to load the kvm_intel module
if RDPMC_EXITING is supported. Even without the actual support
this part of the change is required on 3.2 hosts.
BugLink: http://bugs.launchpad.net/bugs/1031090
Signed-off-by: Stefan Bader <stefan.bader@canonical.com>
Signed-off-by: Avi Kivity <avi@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 53d227f282 upstream.
Currently we reserve seqnos only when we emit the request to the ring
(by bumping dev_priv->next_seqno), but start using it much earlier for
ring->oustanding_lazy_request. When 2 threads compete for the gpu and
run on two different rings (e.g. ddx on blitter vs. compositor)
hilarity ensued, especially when we get constantly interrupted while
reserving buffers.
Breakage seems to have been introduced in
commit 6f392d5486
Author: Chris Wilson <chris@chris-wilson.co.uk>
Date: Sat Aug 7 11:01:22 2010 +0100
drm/i915: Use a common seqno for all rings.
This patch fixes up the seqno reservation logic by moving it into
i915_gem_next_request_seqno. The ring->add_request functions now
superflously still return the new seqno through a pointer, that will
be refactored in the next patch.
Note that with this change we now unconditionally allocate a seqno,
even when ->add_request might fail because the rings are full and the
gpu died. But this does not open up a new can of worms because we can
already leave behind an outstanding_request_seqno if e.g. the caller
gets interrupted with a signal while stalling for the gpu in the
eviciton paths. And with the bugfix we only ever have one seqno
allocated per ring (and only that ring), so there are no ordering
issues with multiple outstanding seqnos on the same ring.
v2: Keep i915_gem_get_seqno (but move it to i915_gem.c) to make it
clear that we only have one seqno counter for all rings. Suggested by
Chris Wilson.
v3: As suggested by Chris Wilson use i915_gem_next_request_seqno
instead of ring->oustanding_lazy_request to make the follow-up
refactoring more clearly correct. Also improve the commit message
with issues discussed on irc.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=45181
Tested-by: Nicolas Kalkhof nkalkhof()at()web.de
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a6dc8c0421 upstream.
The variable io_size was unsigned int, which caused the wrong sector number
to be calculated after aligning it. This then caused mount to fail with big
volumes, as backup volume header information was searched from a
wrong sector.
Signed-off-by: Janne Kalliomäki <janne@tuxera.com>
Signed-off-by: Christoph Hellwig <hch@lst.de>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3ce4d85b76 upstream.
In commit a7959c1, the USB part of rtlwifi was switched to convert
_usb_read_sync() to using a preallocated buffer rather than one
that has been acquired using kmalloc. Although this routine is named
as though it were synchronous, there seem to be simultaneous users,
and the selection of the index to the data buffer is not multi-user
safe. This situation is addressed by adding a new spinlock. The routine
cannot sleep, thus a mutex is not allowed.
Signed-off-by: Larry Finger <Larry.Finger@lwfinger.net>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commits a117dacde0
and 8bbb181308 ]
The tun module leaks up to 36 bytes of memory by not fully initializing
a structure located on the stack that gets copied to user memory by the
TUNGETIFF and SIOCGIFHWADDR ioctl()s.
Signed-off-by: Mathias Krause <minipli@googlemail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 59ea33a68a ]
Back in 2006, commit 1a2449a87b ("[I/OAT]: TCP recv offload to I/OAT")
added support for receive offloading to IOAT dma engine if available.
The code in tcp_rcv_established() tries to perform early DMA copy if
applicable. It however does so without checking whether the userspace
task is actually expecting the data in the buffer.
This is not a problem under normal circumstances, but there is a corner
case where this doesn't work -- and that's when MSG_TRUNC flag to
recvmsg() is used.
If the IOAT dma engine is not used, the code properly checks whether
there is a valid ucopy.task and the socket is owned by userspace, but
misses the check in the dmaengine case.
This problem can be observed in real trivially -- for example 'tbench' is a
good reproducer, as it makes a heavy use of MSG_TRUNC. On systems utilizing
IOAT, you will soon find tbench waiting indefinitely in sk_wait_data(), as they
have been already early-copied in tcp_rcv_established() using dma engine.
This patch introduces the same check we are performing in the simple
iovec copy case to the IOAT case as well. It fixes the indefinite
recvmsg(MSG_TRUNC) hangs.
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit b1beb681cb ]
When device flags are set using rtnetlink, IFF_PROMISC and IFF_ALLMULTI
flags are handled specially. Function dev_change_flags sets IFF_PROMISC and
IFF_ALLMULTI bits in dev->gflags according to the passed value but
do_setlink passes a result of rtnl_dev_combine_flags which takes those bits
from dev->flags.
This can be easily trigerred by doing:
tcpdump -i eth0 &
ip l s up eth0
ip sets IFF_UP flag in ifi_flags and ifi_change, which is combined with
IFF_PROMISC by rtnl_dev_combine_flags, causing __dev_change_flags to set
IFF_PROMISC in gflags.
Reported-by: Max Matveev <makc@redhat.com>
Signed-off-by: Jiri Benc <jbenc@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit e4c7f259c5 ]
The problem is that we call this with a spin lock held. The call tree
is:
kaweth_start_xmit() holds kaweth->device_lock.
-> kaweth_async_set_rx_mode()
-> kaweth_control()
-> kaweth_internal_control_msg()
The kaweth_internal_control_msg() function is only called from
kaweth_control() which used GFP_ATOMIC for its allocations.
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 4249357010 ]
TCP_USER_TIMEOUT is a TCP level socket option that takes an unsigned int. But
patch "tcp: Add TCP_USER_TIMEOUT socket option"(dca43c75) didn't check the negative
values. If a user assign -1 to it, the socket will set successfully and wait
for 4294967295 miliseconds. This patch add a negative value check to avoid
this issue.
Signed-off-by: Hangbin Liu <liuhangbin@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 89d7ae34cd ]
As reported by Alan Cox, and verified by Lin Ming, when a user
attempts to add a CIPSO option to a socket using the CIPSO_V4_TAG_LOCAL
tag the kernel dies a terrible death when it attempts to follow a NULL
pointer (the skb argument to cipso_v4_validate() is NULL when called via
the setsockopt() syscall).
This patch fixes this by first checking to ensure that the skb is
non-NULL before using it to find the incoming network interface. In
the unlikely case where the skb is NULL and the user attempts to add
a CIPSO option with the _TAG_LOCAL tag we return an error as this is
not something we want to allow.
A simple reproducer, kindly supplied by Lin Ming, although you must
have the CIPSO DOI #3 configure on the system first or you will be
caught early in cipso_v4_validate():
#include <sys/types.h>
#include <sys/socket.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <string.h>
struct local_tag {
char type;
char length;
char info[4];
};
struct cipso {
char type;
char length;
char doi[4];
struct local_tag local;
};
int main(int argc, char **argv)
{
int sockfd;
struct cipso cipso = {
.type = IPOPT_CIPSO,
.length = sizeof(struct cipso),
.local = {
.type = 128,
.length = sizeof(struct local_tag),
},
};
memset(cipso.doi, 0, 4);
cipso.doi[3] = 3;
sockfd = socket(AF_INET, SOCK_DGRAM, 0);
#define SOL_IP 0
setsockopt(sockfd, SOL_IP, IP_OPTIONS,
&cipso, sizeof(struct cipso));
return 0;
}
CC: Lin Ming <mlin@ss.pku.edu.cn>
Reported-by: Alan Cox <alan@lxorguk.ukuu.org.uk>
Signed-off-by: Paul Moore <pmoore@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 96f80d123e ]
unregister_netdevice_notifier() must be called before
unregister_pernet_subsys() to avoid accessing already freed
pernet memory. This fixes the following oops when doing rmmod:
Call Trace:
[<ffffffffa0f802bd>] caif_device_notify+0x4d/0x5a0 [caif]
[<ffffffff81552ba9>] unregister_netdevice_notifier+0xb9/0x100
[<ffffffffa0f86dcc>] caif_device_exit+0x1c/0x250 [caif]
[<ffffffff810e7734>] sys_delete_module+0x1a4/0x300
[<ffffffff810da82d>] ? trace_hardirqs_on_caller+0x15d/0x1e0
[<ffffffff813517de>] ? trace_hardirqs_on_thunk+0x3a/0x3
[<ffffffff81696bad>] system_call_fastpath+0x1a/0x1f
RIP
[<ffffffffa0f7f561>] caif_get+0x51/0xb0 [caif]
Signed-off-by: Sjur Brændeland <sjur.brandeland@stericsson.com>
Acked-by: "Eric W. Biederman" <ebiederm@xmission.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 2eebc1e188 ]
A few days ago Dave Jones reported this oops:
[22766.294255] general protection fault: 0000 [#1] PREEMPT SMP
[22766.295376] CPU 0
[22766.295384] Modules linked in:
[22766.387137] ffffffffa169f292 6b6b6b6b6b6b6b6b ffff880147c03a90
ffff880147c03a74
[22766.387135] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 00000000000
[22766.387136] Process trinity-watchdo (pid: 10896, threadinfo ffff88013e7d2000,
[22766.387137] Stack:
[22766.387140] ffff880147c03a10
[22766.387140] ffffffffa169f2b6
[22766.387140] ffff88013ed95728
[22766.387143] 0000000000000002
[22766.387143] 0000000000000000
[22766.387143] ffff880003fad062
[22766.387144] ffff88013c120000
[22766.387144]
[22766.387145] Call Trace:
[22766.387145] <IRQ>
[22766.387150] [<ffffffffa169f292>] ? __sctp_lookup_association+0x62/0xd0
[sctp]
[22766.387154] [<ffffffffa169f2b6>] __sctp_lookup_association+0x86/0xd0 [sctp]
[22766.387157] [<ffffffffa169f597>] sctp_rcv+0x207/0xbb0 [sctp]
[22766.387161] [<ffffffff810d4da8>] ? trace_hardirqs_off_caller+0x28/0xd0
[22766.387163] [<ffffffff815827e3>] ? nf_hook_slow+0x133/0x210
[22766.387166] [<ffffffff815902fc>] ? ip_local_deliver_finish+0x4c/0x4c0
[22766.387168] [<ffffffff8159043d>] ip_local_deliver_finish+0x18d/0x4c0
[22766.387169] [<ffffffff815902fc>] ? ip_local_deliver_finish+0x4c/0x4c0
[22766.387171] [<ffffffff81590a07>] ip_local_deliver+0x47/0x80
[22766.387172] [<ffffffff8158fd80>] ip_rcv_finish+0x150/0x680
[22766.387174] [<ffffffff81590c54>] ip_rcv+0x214/0x320
[22766.387176] [<ffffffff81558c07>] __netif_receive_skb+0x7b7/0x910
[22766.387178] [<ffffffff8155856c>] ? __netif_receive_skb+0x11c/0x910
[22766.387180] [<ffffffff810d423e>] ? put_lock_stats.isra.25+0xe/0x40
[22766.387182] [<ffffffff81558f83>] netif_receive_skb+0x23/0x1f0
[22766.387183] [<ffffffff815596a9>] ? dev_gro_receive+0x139/0x440
[22766.387185] [<ffffffff81559280>] napi_skb_finish+0x70/0xa0
[22766.387187] [<ffffffff81559cb5>] napi_gro_receive+0xf5/0x130
[22766.387218] [<ffffffffa01c4679>] e1000_receive_skb+0x59/0x70 [e1000e]
[22766.387242] [<ffffffffa01c5aab>] e1000_clean_rx_irq+0x28b/0x460 [e1000e]
[22766.387266] [<ffffffffa01c9c18>] e1000e_poll+0x78/0x430 [e1000e]
[22766.387268] [<ffffffff81559fea>] net_rx_action+0x1aa/0x3d0
[22766.387270] [<ffffffff810a495f>] ? account_system_vtime+0x10f/0x130
[22766.387273] [<ffffffff810734d0>] __do_softirq+0xe0/0x420
[22766.387275] [<ffffffff8169826c>] call_softirq+0x1c/0x30
[22766.387278] [<ffffffff8101db15>] do_softirq+0xd5/0x110
[22766.387279] [<ffffffff81073bc5>] irq_exit+0xd5/0xe0
[22766.387281] [<ffffffff81698b03>] do_IRQ+0x63/0xd0
[22766.387283] [<ffffffff8168ee2f>] common_interrupt+0x6f/0x6f
[22766.387283] <EOI>
[22766.387284]
[22766.387285] [<ffffffff8168eed9>] ? retint_swapgs+0x13/0x1b
[22766.387285] Code: c0 90 5d c3 66 0f 1f 44 00 00 4c 89 c8 5d c3 0f 1f 00 55 48
89 e5 48 83
ec 20 48 89 5d e8 4c 89 65 f0 4c 89 6d f8 66 66 66 66 90 <0f> b7 87 98 00 00 00
48 89 fb
49 89 f5 66 c1 c0 08 66 39 46 02
[22766.387307]
[22766.387307] RIP
[22766.387311] [<ffffffffa168a2c9>] sctp_assoc_is_match+0x19/0x90 [sctp]
[22766.387311] RSP <ffff880147c039b0>
[22766.387142] ffffffffa16ab120
[22766.599537] ---[ end trace 3f6dae82e37b17f5 ]---
[22766.601221] Kernel panic - not syncing: Fatal exception in interrupt
It appears from his analysis and some staring at the code that this is likely
occuring because an association is getting freed while still on the
sctp_assoc_hashtable. As a result, we get a gpf when traversing the hashtable
while a freed node corrupts part of the list.
Nominally I would think that an mibalanced refcount was responsible for this,
but I can't seem to find any obvious imbalance. What I did note however was
that the two places where we create an association using
sctp_primitive_ASSOCIATE (__sctp_connect and sctp_sendmsg), have failure paths
which free a newly created association after calling sctp_primitive_ASSOCIATE.
sctp_primitive_ASSOCIATE brings us into the sctp_sf_do_prm_asoc path, which
issues a SCTP_CMD_NEW_ASOC side effect, which in turn adds a new association to
the aforementioned hash table. the sctp command interpreter that process side
effects has not way to unwind previously processed commands, so freeing the
association from the __sctp_connect or sctp_sendmsg error path would lead to a
freed association remaining on this hash table.
I've fixed this but modifying sctp_[un]hash_established to use hlist_del_init,
which allows us to proerly use hlist_unhashed to check if the node is on a
hashlist safely during a delete. That in turn alows us to safely call
sctp_unhash_established in the __sctp_connect and sctp_sendmsg error paths
before freeing them, regardles of what the associations state is on the hash
list.
I noted, while I was doing this, that the __sctp_unhash_endpoint was using
hlist_unhsashed in a simmilar fashion, but never nullified any removed nodes
pointers to make that function work properly, so I fixed that up in a simmilar
fashion.
I attempted to test this using a virtual guest running the SCTP_RR test from
netperf in a loop while running the trinity fuzzer, both in a loop. I wasn't
able to recreate the problem prior to this fix, nor was I able to trigger the
failure after (neither of which I suppose is suprising). Given the trace above
however, I think its likely that this is what we hit.
Signed-off-by: Neil Horman <nhorman@tuxdriver.com>
Reported-by: davej@redhat.com
CC: davej@redhat.com
CC: "David S. Miller" <davem@davemloft.net>
CC: Vlad Yasevich <vyasevich@gmail.com>
CC: Sridhar Samudrala <sri@us.ibm.com>
CC: linux-sctp@vger.kernel.org
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit c1f5163de4 ]
In rare cases, bnx2x_free_tx_skbs() can unmap the wrong DMA address
when it gets to the last entry of the tx ring. We were not using
the proper macro to skip the last entry when advancing the tx index.
Reported-by: Zongyun Lai <zlai@vmware.com>
Reviewed-by: Jeffrey Huang <huangjw@broadcom.com>
Signed-off-by: Michael Chan <mchan@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9539dfb7ac upstream.
Rx Error interrupt(E.G. parity error) is not enabled.
So, when parity error occurs, error interrupt is not occurred.
As a result, the received data is not dropped.
This patch adds enable/disable rx error interrupt code.
Signed-off-by: Tomoya MORINAGA <tomoya.rohm@gmail.com>
Acked-by: Alan Cox <alan@linux.intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[Backported by Tomoya MORINGA: adjusted context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bec4596b4e upstream.
drop_monitor calls several sleeping functions while in atomic context.
BUG: sleeping function called from invalid context at mm/slub.c:943
in_atomic(): 1, irqs_disabled(): 0, pid: 2103, name: kworker/0:2
Pid: 2103, comm: kworker/0:2 Not tainted 3.5.0-rc1+ #55
Call Trace:
[<ffffffff810697ca>] __might_sleep+0xca/0xf0
[<ffffffff811345a3>] kmem_cache_alloc_node+0x1b3/0x1c0
[<ffffffff8105578c>] ? queue_delayed_work_on+0x11c/0x130
[<ffffffff815343fb>] __alloc_skb+0x4b/0x230
[<ffffffffa00b0360>] ? reset_per_cpu_data+0x160/0x160 [drop_monitor]
[<ffffffffa00b022f>] reset_per_cpu_data+0x2f/0x160 [drop_monitor]
[<ffffffffa00b03ab>] send_dm_alert+0x4b/0xb0 [drop_monitor]
[<ffffffff810568e0>] process_one_work+0x130/0x4c0
[<ffffffff81058249>] worker_thread+0x159/0x360
[<ffffffff810580f0>] ? manage_workers.isra.27+0x240/0x240
[<ffffffff8105d403>] kthread+0x93/0xa0
[<ffffffff816be6d4>] kernel_thread_helper+0x4/0x10
[<ffffffff8105d370>] ? kthread_freezable_should_stop+0x80/0x80
[<ffffffff816be6d0>] ? gs_change+0xb/0xb
Rework the logic to call the sleeping functions in right context.
Use standard timer/workqueue api to let system chose any cpu to perform
the allocation and netlink send.
Also avoid a loop if reset_per_cpu_data() cannot allocate memory :
use mod_timer() to wait 1/10 second before next try.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Neil Horman <nhorman@tuxdriver.com>
Reviewed-by: Neil Horman <nhorman@tuxdriver.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4fdcfa1284 upstream.
I just noticed after some recent updates, that the init path for the drop
monitor protocol has a minor error. drop monitor maintains a per cpu structure,
that gets initalized from a single cpu. Normally this is fine, as the protocol
isn't in use yet, but I recently made a change that causes a failed skb
allocation to reschedule itself . Given the current code, the implication is
that this workqueue reschedule will take place on the wrong cpu. If drop
monitor is used early during the boot process, its possible that two cpus will
access a single per-cpu structure in parallel, possibly leading to data
corruption.
This patch fixes the situation, by storing the cpu number that a given instance
of this per-cpu data should be accessed from. In the case of a need for a
reschedule, the cpu stored in the struct is assigned the rescheule, rather than
the currently executing cpu
Tested successfully by myself.
Signed-off-by: Neil Horman <nhorman@tuxdriver.com>
CC: David Miller <davem@davemloft.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3885ca785a upstream.
Eric Dumazet pointed out to me that the drop_monitor protocol has some holes in
its smp protections. Specifically, its possible to replace data->skb while its
being written. This patch corrects that by making data->skb an rcu protected
variable. That will prevent it from being overwritten while a tracepoint is
modifying it.
Signed-off-by: Neil Horman <nhorman@tuxdriver.com>
Reported-by: Eric Dumazet <eric.dumazet@gmail.com>
CC: David Miller <davem@davemloft.net>
Acked-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cde2e9a651 upstream.
Eric Dumazet pointed out this warning in the drop_monitor protocol to me:
[ 38.352571] BUG: sleeping function called from invalid context at kernel/mutex.c:85
[ 38.352576] in_atomic(): 1, irqs_disabled(): 0, pid: 4415, name: dropwatch
[ 38.352580] Pid: 4415, comm: dropwatch Not tainted 3.4.0-rc2+ #71
[ 38.352582] Call Trace:
[ 38.352592] [<ffffffff8153aaf0>] ? trace_napi_poll_hit+0xd0/0xd0
[ 38.352599] [<ffffffff81063f2a>] __might_sleep+0xca/0xf0
[ 38.352606] [<ffffffff81655b16>] mutex_lock+0x26/0x50
[ 38.352610] [<ffffffff8153aaf0>] ? trace_napi_poll_hit+0xd0/0xd0
[ 38.352616] [<ffffffff810b72d9>] tracepoint_probe_register+0x29/0x90
[ 38.352621] [<ffffffff8153a585>] set_all_monitor_traces+0x105/0x170
[ 38.352625] [<ffffffff8153a8ca>] net_dm_cmd_trace+0x2a/0x40
[ 38.352630] [<ffffffff8154a81a>] genl_rcv_msg+0x21a/0x2b0
[ 38.352636] [<ffffffff810f8029>] ? zone_statistics+0x99/0xc0
[ 38.352640] [<ffffffff8154a600>] ? genl_rcv+0x30/0x30
[ 38.352645] [<ffffffff8154a059>] netlink_rcv_skb+0xa9/0xd0
[ 38.352649] [<ffffffff8154a5f0>] genl_rcv+0x20/0x30
[ 38.352653] [<ffffffff81549a7e>] netlink_unicast+0x1ae/0x1f0
[ 38.352658] [<ffffffff81549d76>] netlink_sendmsg+0x2b6/0x310
[ 38.352663] [<ffffffff8150824f>] sock_sendmsg+0x10f/0x130
[ 38.352668] [<ffffffff8150abe0>] ? move_addr_to_kernel+0x60/0xb0
[ 38.352673] [<ffffffff81515f04>] ? verify_iovec+0x64/0xe0
[ 38.352677] [<ffffffff81509c46>] __sys_sendmsg+0x386/0x390
[ 38.352682] [<ffffffff810ffaf9>] ? handle_mm_fault+0x139/0x210
[ 38.352687] [<ffffffff8165b5bc>] ? do_page_fault+0x1ec/0x4f0
[ 38.352693] [<ffffffff8106ba4d>] ? set_next_entity+0x9d/0xb0
[ 38.352699] [<ffffffff81310b49>] ? tty_ldisc_deref+0x9/0x10
[ 38.352703] [<ffffffff8106d363>] ? pick_next_task_fair+0x63/0x140
[ 38.352708] [<ffffffff8150b8d4>] sys_sendmsg+0x44/0x80
[ 38.352713] [<ffffffff8165f8e2>] system_call_fastpath+0x16/0x1b
It stems from holding a spinlock (trace_state_lock) while attempting to register
or unregister tracepoint hooks, making in_atomic() true in this context, leading
to the warning when the tracepoint calls might_sleep() while its taking a mutex.
Since we only use the trace_state_lock to prevent trace protocol state races, as
well as hardware stat list updates on an rcu write side, we can just convert the
spinlock to a mutex to avoid this problem.
Signed-off-by: Neil Horman <nhorman@tuxdriver.com>
Reported-by: Eric Dumazet <eric.dumazet@gmail.com>
CC: David Miller <davem@davemloft.net>
Acked-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2514bc510d upstream.
High frequency link configurations have the potential to cause trouble
with long and/or cheap cables, so prefer slow and wide configurations
instead. This patch has the potential to cause trouble for eDP
configurations that lie about available lanes, so if we run into that we
can make it conditional on eDP.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=45801
Tested-by: peter@colberg.org
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9e2760d18b upstream.
User space access must always go through uaccess accessors, since on
classic m68k user space and kernel space are completely separate.
Signed-off-by: Andreas Schwab <schwab@linux-m68k.org>
Tested-by: Thorsten Glaser <tg@debian.org>
Signed-off-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9e62bb4458 upstream.
_ios_obj() is accessed by group_index not device_table index.
The oc->comps array is only a group_full of devices at a time
it is not like ore_comp_dev() which is indexed by a global
device_table index.
This did not BUG until now because exofs only uses a single
COMP for all devices. But with other FSs like PanFS this is
not true.
This bug was only in the write_path, all other users were
using it correctly
[This is a bug since 3.2 Kernel]
Signed-off-by: Boaz Harrosh <bharrosh@panasas.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 707fba3fa7 upstream.
Lenovo Thinkpad T530 with ALC269VC codec has a dock port but BIOS
doesn't set up the pins properly. Enable the pins as well as on
Thinkpad X230 Tablet.
Reported-and-tested-by: Mario <anyc@hadiko.de>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit aff252a848 upstream.
uac_clock_source_is_valid() uses the control selector value to access
the bmControls bitmap of the clock source unit. This is wrong, as
control selector values start from 1, while the bitmap uses all
available bits.
In other words, "Clock Validity Control" is stored in D3..2, not D5..4
of the clock selector unit's bmControls.
Signed-off-by: Daniel Mack <zonque@gmail.com>
Reported-by: Andreas Koch <andreas@akdesigninc.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d833352a43 upstream.
If a process creates a large hugetlbfs mapping that is eligible for page
table sharing and forks heavily with children some of whom fault and
others which destroy the mapping then it is possible for page tables to
get corrupted. Some teardowns of the mapping encounter a "bad pmd" and
output a message to the kernel log. The final teardown will trigger a
BUG_ON in mm/filemap.c.
This was reproduced in 3.4 but is known to have existed for a long time
and goes back at least as far as 2.6.37. It was probably was introduced
in 2.6.20 by [39dde65c: shared page table for hugetlb page]. The messages
look like this;
[ ..........] Lots of bad pmd messages followed by this
[ 127.164256] mm/memory.c:391: bad pmd ffff880412e04fe8(80000003de4000e7).
[ 127.164257] mm/memory.c:391: bad pmd ffff880412e04ff0(80000003de6000e7).
[ 127.164258] mm/memory.c:391: bad pmd ffff880412e04ff8(80000003de0000e7).
[ 127.186778] ------------[ cut here ]------------
[ 127.186781] kernel BUG at mm/filemap.c:134!
[ 127.186782] invalid opcode: 0000 [#1] SMP
[ 127.186783] CPU 7
[ 127.186784] Modules linked in: af_packet cpufreq_conservative cpufreq_userspace cpufreq_powersave acpi_cpufreq mperf ext3 jbd dm_mod coretemp crc32c_intel usb_storage ghash_clmulni_intel aesni_intel i2c_i801 r8169 mii uas sr_mod cdrom sg iTCO_wdt iTCO_vendor_support shpchp serio_raw cryptd aes_x86_64 e1000e pci_hotplug dcdbas aes_generic container microcode ext4 mbcache jbd2 crc16 sd_mod crc_t10dif i915 drm_kms_helper drm i2c_algo_bit ehci_hcd ahci libahci usbcore rtc_cmos usb_common button i2c_core intel_agp video intel_gtt fan processor thermal thermal_sys hwmon ata_generic pata_atiixp libata scsi_mod
[ 127.186801]
[ 127.186802] Pid: 9017, comm: hugetlbfs-test Not tainted 3.4.0-autobuild #53 Dell Inc. OptiPlex 990/06D7TR
[ 127.186804] RIP: 0010:[<ffffffff810ed6ce>] [<ffffffff810ed6ce>] __delete_from_page_cache+0x15e/0x160
[ 127.186809] RSP: 0000:ffff8804144b5c08 EFLAGS: 00010002
[ 127.186810] RAX: 0000000000000001 RBX: ffffea000a5c9000 RCX: 00000000ffffffc0
[ 127.186811] RDX: 0000000000000000 RSI: 0000000000000009 RDI: ffff88042dfdad00
[ 127.186812] RBP: ffff8804144b5c18 R08: 0000000000000009 R09: 0000000000000003
[ 127.186813] R10: 0000000000000000 R11: 000000000000002d R12: ffff880412ff83d8
[ 127.186814] R13: ffff880412ff83d8 R14: 0000000000000000 R15: ffff880412ff83d8
[ 127.186815] FS: 00007fe18ed2c700(0000) GS:ffff88042dce0000(0000) knlGS:0000000000000000
[ 127.186816] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[ 127.186817] CR2: 00007fe340000503 CR3: 0000000417a14000 CR4: 00000000000407e0
[ 127.186818] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 127.186819] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
[ 127.186820] Process hugetlbfs-test (pid: 9017, threadinfo ffff8804144b4000, task ffff880417f803c0)
[ 127.186821] Stack:
[ 127.186822] ffffea000a5c9000 0000000000000000 ffff8804144b5c48 ffffffff810ed83b
[ 127.186824] ffff8804144b5c48 000000000000138a 0000000000001387 ffff8804144b5c98
[ 127.186825] ffff8804144b5d48 ffffffff811bc925 ffff8804144b5cb8 0000000000000000
[ 127.186827] Call Trace:
[ 127.186829] [<ffffffff810ed83b>] delete_from_page_cache+0x3b/0x80
[ 127.186832] [<ffffffff811bc925>] truncate_hugepages+0x115/0x220
[ 127.186834] [<ffffffff811bca43>] hugetlbfs_evict_inode+0x13/0x30
[ 127.186837] [<ffffffff811655c7>] evict+0xa7/0x1b0
[ 127.186839] [<ffffffff811657a3>] iput_final+0xd3/0x1f0
[ 127.186840] [<ffffffff811658f9>] iput+0x39/0x50
[ 127.186842] [<ffffffff81162708>] d_kill+0xf8/0x130
[ 127.186843] [<ffffffff81162812>] dput+0xd2/0x1a0
[ 127.186845] [<ffffffff8114e2d0>] __fput+0x170/0x230
[ 127.186848] [<ffffffff81236e0e>] ? rb_erase+0xce/0x150
[ 127.186849] [<ffffffff8114e3ad>] fput+0x1d/0x30
[ 127.186851] [<ffffffff81117db7>] remove_vma+0x37/0x80
[ 127.186853] [<ffffffff81119182>] do_munmap+0x2d2/0x360
[ 127.186855] [<ffffffff811cc639>] sys_shmdt+0xc9/0x170
[ 127.186857] [<ffffffff81410a39>] system_call_fastpath+0x16/0x1b
[ 127.186858] Code: 0f 1f 44 00 00 48 8b 43 08 48 8b 00 48 8b 40 28 8b b0 40 03 00 00 85 f6 0f 88 df fe ff ff 48 89 df e8 e7 cb 05 00 e9 d2 fe ff ff <0f> 0b 55 83 e2 fd 48 89 e5 48 83 ec 30 48 89 5d d8 4c 89 65 e0
[ 127.186868] RIP [<ffffffff810ed6ce>] __delete_from_page_cache+0x15e/0x160
[ 127.186870] RSP <ffff8804144b5c08>
[ 127.186871] ---[ end trace 7cbac5d1db69f426 ]---
The bug is a race and not always easy to reproduce. To reproduce it I was
doing the following on a single socket I7-based machine with 16G of RAM.
$ hugeadm --pool-pages-max DEFAULT:13G
$ echo $((18*1048576*1024)) > /proc/sys/kernel/shmmax
$ echo $((18*1048576*1024)) > /proc/sys/kernel/shmall
$ for i in `seq 1 9000`; do ./hugetlbfs-test; done
On my particular machine, it usually triggers within 10 minutes but
enabling debug options can change the timing such that it never hits.
Once the bug is triggered, the machine is in trouble and needs to be
rebooted. The machine will respond but processes accessing proc like "ps
aux" will hang due to the BUG_ON. shutdown will also hang and needs a
hard reset or a sysrq-b.
The basic problem is a race between page table sharing and teardown. For
the most part page table sharing depends on i_mmap_mutex. In some cases,
it is also taking the mm->page_table_lock for the PTE updates but with
shared page tables, it is the i_mmap_mutex that is more important.
Unfortunately it appears to be also insufficient. Consider the following
situation
Process A Process B
--------- ---------
hugetlb_fault shmdt
LockWrite(mmap_sem)
do_munmap
unmap_region
unmap_vmas
unmap_single_vma
unmap_hugepage_range
Lock(i_mmap_mutex)
Lock(mm->page_table_lock)
huge_pmd_unshare/unmap tables <--- (1)
Unlock(mm->page_table_lock)
Unlock(i_mmap_mutex)
huge_pte_alloc ...
Lock(i_mmap_mutex) ...
vma_prio_walk, find svma, spte ...
Lock(mm->page_table_lock) ...
share spte ...
Unlock(mm->page_table_lock) ...
Unlock(i_mmap_mutex) ...
hugetlb_no_page <--- (2)
free_pgtables
unlink_file_vma
hugetlb_free_pgd_range
remove_vma_list
In this scenario, it is possible for Process A to share page tables with
Process B that is trying to tear them down. The i_mmap_mutex on its own
does not prevent Process A walking Process B's page tables. At (1) above,
the page tables are not shared yet so it unmaps the PMDs. Process A sets
up page table sharing and at (2) faults a new entry. Process B then trips
up on it in free_pgtables.
This patch fixes the problem by adding a new function
__unmap_hugepage_range_final that is only called when the VMA is about to
be destroyed. This function clears VM_MAYSHARE during
unmap_hugepage_range() under the i_mmap_mutex. This makes the VMA
ineligible for sharing and avoids the race. Superficially this looks like
it would then be vunerable to truncate and madvise issues but hugetlbfs
has its own truncate handlers so does not use unmap_mapping_range() and
does not support madvise(DONTNEED).
This should be treated as a -stable candidate if it is merged.
Test program is as follows. The test case was mostly written by Michal
Hocko with a few minor changes to reproduce this bug.
==== CUT HERE ====
static size_t huge_page_size = (2UL << 20);
static size_t nr_huge_page_A = 512;
static size_t nr_huge_page_B = 5632;
unsigned int get_random(unsigned int max)
{
struct timeval tv;
gettimeofday(&tv, NULL);
srandom(tv.tv_usec);
return random() % max;
}
static void play(void *addr, size_t size)
{
unsigned char *start = addr,
*end = start + size,
*a;
start += get_random(size/2);
/* we could itterate on huge pages but let's give it more time. */
for (a = start; a < end; a += 4096)
*a = 0;
}
int main(int argc, char **argv)
{
key_t key = IPC_PRIVATE;
size_t sizeA = nr_huge_page_A * huge_page_size;
size_t sizeB = nr_huge_page_B * huge_page_size;
int shmidA, shmidB;
void *addrA = NULL, *addrB = NULL;
int nr_children = 300, n = 0;
if ((shmidA = shmget(key, sizeA, IPC_CREAT|SHM_HUGETLB|0660)) == -1) {
perror("shmget:");
return 1;
}
if ((addrA = shmat(shmidA, addrA, SHM_R|SHM_W)) == (void *)-1UL) {
perror("shmat");
return 1;
}
if ((shmidB = shmget(key, sizeB, IPC_CREAT|SHM_HUGETLB|0660)) == -1) {
perror("shmget:");
return 1;
}
if ((addrB = shmat(shmidB, addrB, SHM_R|SHM_W)) == (void *)-1UL) {
perror("shmat");
return 1;
}
fork_child:
switch(fork()) {
case 0:
switch (n%3) {
case 0:
play(addrA, sizeA);
break;
case 1:
play(addrB, sizeB);
break;
case 2:
break;
}
break;
case -1:
perror("fork:");
break;
default:
if (++n < nr_children)
goto fork_child;
play(addrA, sizeA);
break;
}
shmdt(addrA);
shmdt(addrB);
do {
wait(NULL);
} while (--n > 0);
shmctl(shmidA, IPC_RMID, NULL);
shmctl(shmidB, IPC_RMID, NULL);
return 0;
}
[akpm@linux-foundation.org: name the declaration's args, fix CONFIG_HUGETLBFS=n build]
Signed-off-by: Hugh Dickins <hughd@google.com>
Reviewed-by: Michal Hocko <mhocko@suse.cz>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2:
- Adjust context
- Drop the mmu_gather * parameters]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3ad3d901bb upstream.
mmu_notifier_release() is called when the process is exiting. It will
delete all the mmu notifiers. But at this time the page belonging to the
process is still present in page tables and is present on the LRU list, so
this race will happen:
CPU 0 CPU 1
mmu_notifier_release: try_to_unmap:
hlist_del_init_rcu(&mn->hlist);
ptep_clear_flush_notify:
mmu nofifler not found
free page !!!!!!
/*
* At the point, the page has been
* freed, but it is still mapped in
* the secondary MMU.
*/
mn->ops->release(mn, mm);
Then the box is not stable and sometimes we can get this bug:
[ 738.075923] BUG: Bad page state in process migrate-perf pfn:03bec
[ 738.075931] page:ffffea00000efb00 count:0 mapcount:0 mapping: (null) index:0x8076
[ 738.075936] page flags: 0x20000000000014(referenced|dirty)
The same issue is present in mmu_notifier_unregister().
We can call ->release before deleting the notifier to ensure the page has
been unmapped from the secondary MMU before it is freed.
Signed-off-by: Xiao Guangrong <xiaoguangrong@linux.vnet.ibm.com>
Cc: Avi Kivity <avi@redhat.com>
Cc: Marcelo Tosatti <mtosatti@redhat.com>
Cc: Paul Gortmaker <paul.gortmaker@windriver.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ca57df79d4 upstream.
On architectures with CONFIG_HUGETLB_PAGE_SIZE_VARIABLE set, such as
Itanium, pageblock_order is a variable with default value of 0. It's set
to the right value by set_pageblock_order() in function
free_area_init_core().
But pageblock_order may be used by sparse_init() before free_area_init_core()
is called along path:
sparse_init()
->sparse_early_usemaps_alloc_node()
->usemap_size()
->SECTION_BLOCKFLAGS_BITS
->((1UL << (PFN_SECTION_SHIFT - pageblock_order)) *
NR_PAGEBLOCK_BITS)
The uninitialized pageblock_size will cause memory wasting because
usemap_size() returns a much bigger value then it's really needed.
For example, on an Itanium platform,
sparse_init() pageblock_order=0 usemap_size=24576
free_area_init_core() before pageblock_order=0, usemap_size=24576
free_area_init_core() after pageblock_order=12, usemap_size=8
That means 24K memory has been wasted for each section, so fix it by calling
set_pageblock_order() from sparse_init().
Signed-off-by: Xishi Qiu <qiuxishi@huawei.com>
Signed-off-by: Jiang Liu <liuj97@gmail.com>
Cc: Tony Luck <tony.luck@intel.com>
Cc: Yinghai Lu <yinghai@kernel.org>
Cc: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Cc: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Cc: David Rientjes <rientjes@google.com>
Cc: Keping Chen <chenkeping@huawei.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f96a4216e8 upstream.
The default 10 microsecond delay for the controller to come out of
halt in dbgp_ehci_startup is too short, so increase it to 1 millisecond.
This is based on emperical testing on various USB debug ports on
modern machines such as a Lenovo X220i and an Ivybridge development
platform that needed to wait ~450-950 microseconds.
Signed-off-by: Colin Ian King <colin.king@canonical.com>
Signed-off-by: Jason Wessel <jason.wessel@windriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 15ac49b650 upstream.
While trying to get a v3.5 kernel booted on the cubox, I noticed that
VFP does not work correctly with VFP bounce handling. This is because
of the confusion over 16-bit vs 32-bit instructions, and where PC is
supposed to point to.
The rule is that FP handlers are entered with regs->ARM_pc pointing at
the _next_ instruction to be executed. However, if the exception is
not handled, regs->ARM_pc points at the faulting instruction.
This is easy for ARM mode, because we know that the next instruction and
previous instructions are separated by four bytes. This is not true of
Thumb2 though.
Since all FP instructions are 32-bit in Thumb2, it makes things easy.
We just need to select the appropriate adjustment. Do this by moving
the adjustment out of do_undefinstr() into the assembly code, as only
the assembly code knows whether it's dealing with a 32-bit or 16-bit
instruction.
Acked-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5a783cbc48 upstream.
Commit cdf357f1 ("ARM: 6299/1: errata: TLBIASIDIS and TLBIMVAIS
operations can broadcast a faulty ASID") replaced by-ASID TLB flushing
operations with all-ASID variants to workaround A9 erratum #720789.
This patch extends the workaround to include the tlb_range operations,
which were overlooked by the original patch.
Tested-by: Steve Capper <steve.capper@arm.com>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 24b35521b8 upstream.
vfp_pm_suspend should save the VFP state in suspend after
any lazy context switch. If it only saves when the VFP is enabled,
the state can get lost when, on a UP system:
Thread 1 uses the VFP
Context switch occurs to thread 2, VFP is disabled but the
VFP context is not saved
Thread 2 initiates suspend
vfp_pm_suspend is called with the VFP disabled, and the unsaved
VFP context of Thread 1 in the registers
Modify vfp_pm_suspend to save the VFP context whenever
vfp_current_hw_state is not NULL.
Includes a fix from Ido Yariv <ido@wizery.com>, who pointed out that on
SMP systems, the state pointer can be pointing to a freed task struct if
a task exited on another cpu, fixed by using #ifndef CONFIG_SMP in the
new if clause.
Cc: Barry Song <bs14@csr.com>
Cc: Catalin Marinas <catalin.marinas@arm.com>
Cc: Ido Yariv <ido@wizery.com>
Cc: Daniel Drake <dsd@laptop.org>
Cc: Will Deacon <will.deacon@arm.com>
Signed-off-by: Colin Cross <ccross@android.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a84b895a23 upstream.
vfp_pm_suspend runs on each cpu, only clear the hardware state
pointer for the current cpu. Prevents a possible crash if one
cpu clears the hw state pointer when another cpu has already
checked if it is valid.
Signed-off-by: Colin Cross <ccross@android.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a76d7bd96d upstream.
The open-coded mutex implementation for ARMv6+ cores suffers from a
severe lack of barriers, so in the uncontended case we don't actually
protect any accesses performed during the critical section.
Furthermore, the code is largely a duplication of the ARMv6+ atomic_dec
code but optimised to remove a branch instruction, as the mutex fastpath
was previously inlined. Now that this is executed out-of-line, we can
reuse the atomic access code for the locking (in fact, we use the xchg
code as this produces shorter critical sections).
This patch uses the generic xchg based implementation for mutexes on
ARMv6+, which introduces barriers to the lock/unlock operations and also
has the benefit of removing a fair amount of inline assembly code.
Acked-by: Arnd Bergmann <arnd@arndb.de>
Acked-by: Nicolas Pitre <nico@linaro.org>
Reported-by: Shan Kang <kangshan0910@gmail.com>
Signed-off-by: Will Deacon <will.deacon@arm.com>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 98bd8b96b2 upstream.
The CPU will endlessly spin at the end of machine_halt and
machine_restart calls. However, this will lead to a soft lockup
warning after about 20 seconds, if CONFIG_LOCKUP_DETECTOR is enabled,
as system timer is still alive.
Disable interrupt before going to spin endlessly, so that the lockup
warning will never be seen.
Reported-by: Marek Vasut <marex@denx.de>
Signed-off-by: Shawn Guo <shawn.guo@linaro.org>
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit caea33da89 upstream.
Without this patch kernel will panic on LockD start, because lockd_up() checks
lockd_up_net() result for negative value.
From my pow it's better to return negative value from rpcbind routines instead
of replacing all such checks like in lockd_up().
Signed-off-by: Stanislav Kinsbursky <skinsbursky@parallels.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 572d8b3945 upstream.
An fs-thaw ioctl causes deadlock with a chcp or mkcp -s command:
chcp D ffff88013870f3d0 0 1325 1324 0x00000004
...
Call Trace:
nilfs_transaction_begin+0x11c/0x1a0 [nilfs2]
wake_up_bit+0x20/0x20
copy_from_user+0x18/0x30 [nilfs2]
nilfs_ioctl_change_cpmode+0x7d/0xcf [nilfs2]
nilfs_ioctl+0x252/0x61a [nilfs2]
do_page_fault+0x311/0x34c
get_unmapped_area+0x132/0x14e
do_vfs_ioctl+0x44b/0x490
__set_task_blocked+0x5a/0x61
vm_mmap_pgoff+0x76/0x87
__set_current_blocked+0x30/0x4a
sys_ioctl+0x4b/0x6f
system_call_fastpath+0x16/0x1b
thaw D ffff88013870d890 0 1352 1351 0x00000004
...
Call Trace:
rwsem_down_failed_common+0xdb/0x10f
call_rwsem_down_write_failed+0x13/0x20
down_write+0x25/0x27
thaw_super+0x13/0x9e
do_vfs_ioctl+0x1f5/0x490
vm_mmap_pgoff+0x76/0x87
sys_ioctl+0x4b/0x6f
filp_close+0x64/0x6c
system_call_fastpath+0x16/0x1b
where the thaw ioctl deadlocked at thaw_super() when called while chcp was
waiting at nilfs_transaction_begin() called from
nilfs_ioctl_change_cpmode(). This deadlock is 100% reproducible.
This is because nilfs_ioctl_change_cpmode() first locks sb->s_umount in
read mode and then waits for unfreezing in nilfs_transaction_begin(),
whereas thaw_super() locks sb->s_umount in write mode. The locking of
sb->s_umount here was intended to make snapshot mounts and the downgrade
of snapshots to checkpoints exclusive.
This fixes the deadlock issue by replacing the sb->s_umount usage in
nilfs_ioctl_change_cpmode() with a dedicated mutex which protects snapshot
mounts.
Signed-off-by: Ryusuke Konishi <konishi.ryusuke@lab.ntt.co.jp>
Cc: Fernando Luis Vazquez Cao <fernando@oss.ntt.co.jp>
Tested-by: Ryusuke Konishi <konishi.ryusuke@lab.ntt.co.jp>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3715c5309f upstream.
When using ALT+SysRq+Q all the pointers are replaced with "pK-error" like
this:
[23153.208033] .base: pK-error
with echo h > /proc/sysrq-trigger it works:
[23107.776363] .base: ffff88023e60d540
The intent behind this behavior was to return "pK-error" in cases where
the %pK format specifier was used in interrupt context, because the
CAP_SYSLOG check wouldn't be meaningful. Clearly this should only apply
when kptr_restrict is actually enabled though.
Reported-by: Stevie Trujillo <stevie.trujillo@gmail.com>
Signed-off-by: Dan Rosenberg <dan.j.rosenberg@gmail.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6c4088ac3a upstream.
efi_setup_pcdp_console() is called during boot to parse the HCDP/PCDP
EFI system table and setup an early console for printk output. The
routine uses ioremap/iounmap to setup access to the HCDP/PCDP table
information.
The call to ioremap is happening early in the boot process which leads
to a panic on x86_64 systems:
panic+0x01ca
do_exit+0x043c
oops_end+0x00a7
no_context+0x0119
__bad_area_nosemaphore+0x0138
bad_area_nosemaphore+0x000e
do_page_fault+0x0321
page_fault+0x0020
reserve_memtype+0x02a1
__ioremap_caller+0x0123
ioremap_nocache+0x0012
efi_setup_pcdp_console+0x002b
setup_arch+0x03a9
start_kernel+0x00d4
x86_64_start_reservations+0x012c
x86_64_start_kernel+0x00fe
This replaces the calls to ioremap/iounmap in efi_setup_pcdp_console()
with calls to early_ioremap/early_iounmap which can be called during
early boot.
This patch was tested on an x86_64 prototype system which uses the
HCDP/PCDP table for early console setup.
Signed-off-by: Greg Pearson <greg.pearson@hp.com>
Acked-by: Khalid Aziz <khalid.aziz@hp.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b7219ccb33 upstream.
If a resync of a RAID1 array with 2 devices finds a known bad block
one device it will neither read from, or write to, that device for
this block offset.
So there will be one read_target (The other device) and zero write
targets.
This condition causes md/raid1 to abort the resync assuming that it
has finished - without known bad blocks this would be true.
When there are no write targets because of the presence of bad blocks
we should only skip over the area covered by the bad block.
RAID10 already gets this right, raid1 doesn't. Or didn't.
As this can cause a 'sync' to abort early and appear to have succeeded
it could lead to some data corruption, so it suitable for -stable.
Reported-by: Alexander Lyakas <alex.bolshoy@gmail.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5cf02d09b5 upstream.
We've had some reports of a deadlock where rpciod ends up with a stack
trace like this:
PID: 2507 TASK: ffff88103691ab40 CPU: 14 COMMAND: "rpciod/14"
#0 [ffff8810343bf2f0] schedule at ffffffff814dabd9
#1 [ffff8810343bf3b8] nfs_wait_bit_killable at ffffffffa038fc04 [nfs]
#2 [ffff8810343bf3c8] __wait_on_bit at ffffffff814dbc2f
#3 [ffff8810343bf418] out_of_line_wait_on_bit at ffffffff814dbcd8
#4 [ffff8810343bf488] nfs_commit_inode at ffffffffa039e0c1 [nfs]
#5 [ffff8810343bf4f8] nfs_release_page at ffffffffa038bef6 [nfs]
#6 [ffff8810343bf528] try_to_release_page at ffffffff8110c670
#7 [ffff8810343bf538] shrink_page_list.clone.0 at ffffffff81126271
#8 [ffff8810343bf668] shrink_inactive_list at ffffffff81126638
#9 [ffff8810343bf818] shrink_zone at ffffffff8112788f
#10 [ffff8810343bf8c8] do_try_to_free_pages at ffffffff81127b1e
#11 [ffff8810343bf958] try_to_free_pages at ffffffff8112812f
#12 [ffff8810343bfa08] __alloc_pages_nodemask at ffffffff8111fdad
#13 [ffff8810343bfb28] kmem_getpages at ffffffff81159942
#14 [ffff8810343bfb58] fallback_alloc at ffffffff8115a55a
#15 [ffff8810343bfbd8] ____cache_alloc_node at ffffffff8115a2d9
#16 [ffff8810343bfc38] kmem_cache_alloc at ffffffff8115b09b
#17 [ffff8810343bfc78] sk_prot_alloc at ffffffff81411808
#18 [ffff8810343bfcb8] sk_alloc at ffffffff8141197c
#19 [ffff8810343bfce8] inet_create at ffffffff81483ba6
#20 [ffff8810343bfd38] __sock_create at ffffffff8140b4a7
#21 [ffff8810343bfd98] xs_create_sock at ffffffffa01f649b [sunrpc]
#22 [ffff8810343bfdd8] xs_tcp_setup_socket at ffffffffa01f6965 [sunrpc]
#23 [ffff8810343bfe38] worker_thread at ffffffff810887d0
#24 [ffff8810343bfee8] kthread at ffffffff8108dd96
#25 [ffff8810343bff48] kernel_thread at ffffffff8100c1ca
rpciod is trying to allocate memory for a new socket to talk to the
server. The VM ends up calling ->releasepage to get more memory, and it
tries to do a blocking commit. That commit can't succeed however without
a connected socket, so we deadlock.
Fix this by setting PF_FSTRANS on the workqueue task prior to doing the
socket allocation, and having nfs_release_page check for that flag when
deciding whether to do a commit call. Also, set PF_FSTRANS
unconditionally in rpc_async_schedule since that function can also do
allocations sometimes.
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 008c2e8f24 upstream.
Make sure the kernel does not incorrectly create a SIGBUS signal during
user space accesses:
For user space accesses in the switched addressing mode case the kernel
may walk page tables and access user address space via the kernel
mapping. If a page table entry is invalid the function __handle_fault()
gets called in order to emulate a page fault and trigger all the usual
actions like paging in a missing page etc. by calling handle_mm_fault().
If handle_mm_fault() returns with an error fixup handling is necessary.
For the switched addressing mode case all errors need to be mapped to
-EFAULT, so that the calling uaccess function can return -EFAULT to
user space.
Unfortunately the __handle_fault() incorrectly calls do_sigbus() if
VM_FAULT_SIGBUS is set. This however should only happen if a page fault
was triggered by a user space instruction. For kernel mode uaccesses
the correct action is to only return -EFAULT.
So user space may incorrectly see SIGBUS signals because of this bug.
For current machines this would only be possible for the switched
addressing mode case in conjunction with futex operations.
Signed-off-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
[bwh: Backported to 3.2: do_exception() and do_sigbus() parameters differ]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2c95a32909 upstream.
Block layer will allocate a spinlock for the queue if the driver does
not provide one in blk_init_queue().
The reason to use the internal spinlock is that blk_cleanup_queue() will
switch to use the internal spinlock in the cleanup code path.
if (q->queue_lock != &q->__queue_lock)
q->queue_lock = &q->__queue_lock;
However, processes which are in D state might have taken the driver
provided spinlock, when the processes wake up, they would release the
block provided spinlock.
=====================================
[ BUG: bad unlock balance detected! ]
3.4.0-rc7+ #238 Not tainted
-------------------------------------
fio/3587 is trying to release lock (&(&q->__queue_lock)->rlock) at:
[<ffffffff813274d2>] blk_queue_bio+0x2a2/0x380
but there are no more locks to release!
other info that might help us debug this:
1 lock held by fio/3587:
#0: (&(&vblk->lock)->rlock){......}, at:
[<ffffffff8132661a>] get_request_wait+0x19a/0x250
Other drivers use block layer provided spinlock as well, e.g. SCSI.
Switching to the block layer provided spinlock saves a bit of memory and
does not increase lock contention. Performance test shows no real
difference is observed before and after this patch.
Changes in v2: Improve commit log as Michael suggested.
Cc: virtualization@lists.linux-foundation.org
Cc: kvm@vger.kernel.org
Signed-off-by: Asias He <asias@redhat.com>
Acked-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Rusty Russell <rusty@rustcorp.com.au>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 63a78bb105 upstream.
According to responses from the BIOS team, ASUS_WMI_METHODID_DSTS2
(0x53545344) will be used as future DSTS ID. In addition, calling
asus_wmi_evaluate_method(ASUS_WMI_METHODID_DSTS2, 0, 0, NULL) returns
ASUS_WMI_UNSUPPORTED_METHOD in new ASUS laptop PCs. This patch fixes
no DSTS ID will be assigned in this case.
Signed-off-by: Alex Hung <alex.hung@canonical.com>
Signed-off-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d2e7c96af1 upstream.
Mix in any architectural randomness in extract_buf() instead of
xfer_secondary_buf(). This allows us to mix in more architectural
randomness, and it also makes xfer_secondary_buf() faster, moving a
tiny bit of additional CPU overhead to process which is extracting the
randomness.
[ Commit description modified by tytso to remove an extended
advertisement for the RDRAND instruction. ]
Signed-off-by: H. Peter Anvin <hpa@linux.intel.com>
Acked-by: Ingo Molnar <mingo@kernel.org>
Cc: DJ Johnston <dj.johnston@intel.com>
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 905386f82d upstream.
Fix memory leak in process_prepared_mapping by always freeing
the dm_thin_new_mapping structs from the mapping_pool mempool on
the error paths.
Signed-off-by: Joe Thornber <ejt@redhat.com>
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7768ed33cc upstream.
Reduce the slab size used for the dm_thin_endio_hook mempool.
Allocation has been seen to fail on machines with smaller amounts
of memory due to fragmentation.
lvm: page allocation failure. order:5, mode:0xd0
device-mapper: table: 253:38: thin-pool: Error creating pool's endio_hook mempool
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a119365586 upstream.
The following build error occured during a ia64 build with
swap-over-NFS patches applied.
net/core/sock.c:274:36: error: initializer element is not constant
net/core/sock.c:274:36: error: (near initialization for 'memalloc_socks')
net/core/sock.c:274:36: error: initializer element is not constant
This is identical to a parisc build error. Fengguang Wu, Mel Gorman
and James Bottomley did all the legwork to track the root cause of
the problem. This fix and entire commit log is shamelessly copied
from them with one extra detail to change a dubious runtime use of
ATOMIC_INIT() to atomic_set() in drivers/char/mspec.c
Dave Anglin says:
> Here is the line in sock.i:
>
> struct static_key memalloc_socks = ((struct static_key) { .enabled =
> ((atomic_t) { (0) }) });
The above line contains two compound literals. It also uses a designated
initializer to initialize the field enabled. A compound literal is not a
constant expression.
The location of the above statement isn't fully clear, but if a compound
literal occurs outside the body of a function, the initializer list must
consist of constant expressions.
Signed-off-by: Tony Luck <tony.luck@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0f6f281b73 upstream.
The downgrade of the 4 level page table created by init_new_context is
currently done only in start_thread31. If a 31 bit process forks the
new mm uses a 4 level page table, including the task size of 2<<42
that goes along with it. This is incorrect as now a 31 bit process
can map memory beyond 2GB. Define arch_dup_mmap to do the downgrade
after fork.
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bc733d4952 upstream.
The irq field of struct snd_mpu401 is supposed to be initialized to -1.
Since it's set to zero as of now, a probing error before the irq
installation results in a kernel warning "Trying to free already-free
IRQ 0".
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=44821
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6162552b0d upstream.
We've got a bug report about the silent output from the headphone on a
mobo with VT2021, and spotted out that this was because of the wrong
D3 state on the DAC for the headphone output. The bug is triggered by
the incomplete check for this DAC in set_widgets_power_state_vt1718S().
It checks only the connectivity of the primary output (0x27) but
doesn't consider the path from the headphone pin (0x28).
Now this patch fixes the problem by checking both pins for DAC 0x0b.
Signed-off-by: Takashi Iwai <tiwai@suse.de>
[bwh: Backported to 3.2: keep using snd_hda_codec_write() as
update_power_state() is missing]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c0394506e6 upstream.
The touchpad on the Acer Aspire One D250 will report out of range values
in the extreme lower portion of the touchpad. These appear as abrupt
changes in the values reported by the hardware from very low values to
very high values, which can cause unexpected vertical jumps in the
position of the mouse pointer.
What seems to be happening is that the value is wrapping to a two's
compliment negative value of higher resolution than the 13-bit value
reported by the hardware, with the high-order bits being truncated. This
patch adds handling for these values by converting them to the
appropriate negative values.
The only tricky part about this is deciding when to treat a number as
negative. It stands to reason that if out of range values can be
reported on the low end then it could also happen on the high end, so
not all out of range values should be treated as negative. The approach
taken here is to split the difference between the maximum legitimate
value for the axis and the maximum possible value that the hardware can
report, treating values greater than this number as negative and all
other values as positive. This can be tweaked later if hardware is found
that operates outside of these parameters.
BugLink: http://bugs.launchpad.net/bugs/1001251
Signed-off-by: Seth Forshee <seth.forshee@canonical.com>
Reviewed-by: Daniel Kurtz <djkurtz@chromium.org>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2fe2d9f47c upstream.
Line 0 and 1 were both written to line 0 (on the display) and all subsequent
lines had an offset of -1. The result was that the last line on the display
was never overwritten by writes to /dev/fbN.
The origin of this bug seems to have been udlfb.
Signed-off-by: Alexander Holler <holler@ahsoftware.de>
Signed-off-by: Florian Tobias Schandinat <FlorianSchandinat@gmx.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b8edf3e552 upstream.
Otherwise if someone tries to use all four channels on AIF1 with the
device in master mode we won't be able to clock out all the data.
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 27130f0cc3 upstream.
wm831x devices contain a unique ID value. Feed this into the newly added
device_add_randomness() to add some per device seed data to the pool.
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9dccf55f4c upstream.
The tamper evident features of the RTC include the "write counter" which
is a pseudo-random number regenerated whenever we set the RTC. Since this
value is unpredictable it should provide some useful seeding to the random
number generator.
Only do this on boot since the goal is to seed the pool rather than add
useful entropy.
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c2557a303a upstream.
Create a new function, get_random_bytes_arch() which will use the
architecture-specific hardware random number generator if it is
present. Change get_random_bytes() to not use the HW RNG, even if it
is avaiable.
The reason for this is that the hw random number generator is fast (if
it is present), but it requires that we trust the hardware
manufacturer to have not put in a back door. (For example, an
increasing counter encrypted by an AES key known to the NSA.)
It's unlikely that Intel (for example) was paid off by the US
Government to do this, but it's impossible for them to prove otherwise
commit e6d4947b12 upstream.
If the CPU supports a hardware random number generator, use it in
xfer_secondary_pool(), where it will significantly improve things and
where we can afford it.
Also, remove the use of the arch-specific rng in
add_timer_randomness(), since the call is significantly slower than
get_cycles(), and we're much better off using it in
xfer_secondary_pool() anyway.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a2080a67ab upstream.
Add a new interface, add_device_randomness() for adding data to the
random pool that is likely to differ between two devices (or possibly
even per boot). This would be things like MAC addresses or serial
numbers, or the read-out of the RTC. This does *not* add any actual
entropy to the pool, but it initializes the pool to different values
for devices that might otherwise be identical and have very little
entropy available to them (particularly common in the embedded world).
[ Modified by tytso to mix in a timestamp, since there may be some
variability caused by the time needed to detect/configure the hardware
in question. ]
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 902c098a36 upstream.
The real-time Linux folks don't like add_interrupt_randomness() taking
a spinlock since it is called in the low-level interrupt routine.
This also allows us to reduce the overhead in the fast path, for the
random driver, which is the interrupt collection path.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 775f4b297b upstream.
We've been moving away from add_interrupt_randomness() for various
reasons: it's too expensive to do on every interrupt, and flooding the
CPU with interrupts could theoretically cause bogus floods of entropy
from a somewhat externally controllable source.
This solves both problems by limiting the actual randomness addition
to just once a second or after 64 interrupts, whicever comes first.
During that time, the interrupt cycle data is buffered up in a per-cpu
pool. Also, we make sure the the nonblocking pool used by urandom is
initialized before we start feeding the normal input pool. This
assures that /dev/urandom is returning unpredictable data as soon as
possible.
(Based on an original patch by Linus, but significantly modified by
tytso.)
Tested-by: Eric Wustrow <ewust@umich.edu>
Reported-by: Eric Wustrow <ewust@umich.edu>
Reported-by: Nadia Heninger <nadiah@cs.ucsd.edu>
Reported-by: Zakir Durumeric <zakir@umich.edu>
Reported-by: J. Alex Halderman <jhalderm@umich.edu>.
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3e88bdff1c upstream.
If there is an architecture-specific random number generator (such as
RDRAND for Intel architectures), use it to initialize /dev/random's
entropy stores. Even in the worst case, if RDRAND is something like
AES(NSA_KEY, counter++), it won't hurt, and it will definitely help
against any other adversaries.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Link: http://lkml.kernel.org/r/1324589281-31931-1-git-send-email-tytso@mit.edu
Signed-off-by: H. Peter Anvin <hpa@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cf833d0b99 upstream.
We still don't use rdrand in /dev/random, which just seems stupid. We
accept the *cycle*counter* as a random input, but we don't accept
rdrand? That's just broken.
Sure, people can do things in user space (write to /dev/random, use
rdrand in addition to /dev/random themselves etc etc), but that
*still* seems to be a particularly stupid reason for saying "we
shouldn't bother to try to do better in /dev/random".
And even if somebody really doesn't trust rdrand as a source of random
bytes, it seems singularly stupid to trust the cycle counter *more*.
So I'd suggest the attached patch. I'm not going to even bother
arguing that we should add more bits to the entropy estimate, because
that's not the point - I don't care if /dev/random fills up slowly or
not, I think it's just stupid to not use the bits we can get from
rdrand and mix them into the strong randomness pool.
Link: http://lkml.kernel.org/r/CA%2B55aFwn59N1=m651QAyTy-1gO1noGbK18zwKDwvwqnravA84A@mail.gmail.com
Acked-by: "David S. Miller" <davem@davemloft.net>
Acked-by: "Theodore Ts'o" <tytso@mit.edu>
Acked-by: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Matt Mackall <mpm@selenic.com>
Cc: Tony Luck <tony.luck@intel.com>
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Signed-off-by: H. Peter Anvin <hpa@linux.intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2930d381d2 upstream.
Actually, xfs and jfs can optionally be case insensitive; we'll handle
that case in later patches.
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b31b021988 upstream.
commit 9ef449c6b3 ("[media] rc: Postpone ISR
registration") fixed an early ISR registration on several drivers. It did
however also introduced a bug by moving the invocation of pnp_port_start()
to the end of the probe function.
This patch fixes this issue by moving the invocation of pnp_port_start() to
an earlier stage in the probe function.
Cc: Jarod Wilson <jarod@redhat.com>
Signed-off-by: Luis Henriques <luis.henriques@canonical.com>
Signed-off-by: Mauro Carvalho Chehab <mchehab@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c663600584 upstream.
Booting a 3.2, 3.3, or 3.4-rc4 kernel on an Atari using the
`nfeth' ethernet device triggers a WARN_ONCE() in generic irq
handling code on the first irq for that device:
WARNING: at kernel/irq/handle.c:146 handle_irq_event_percpu+0x134/0x142()
irq 3 handler nfeth_interrupt+0x0/0x194 enabled interrupts
Modules linked in:
Call Trace: [<000299b2>] warn_slowpath_common+0x48/0x6a
[<000299c0>] warn_slowpath_common+0x56/0x6a
[<00029a4c>] warn_slowpath_fmt+0x2a/0x32
[<0005b34c>] handle_irq_event_percpu+0x134/0x142
[<0005b34c>] handle_irq_event_percpu+0x134/0x142
[<0000a584>] nfeth_interrupt+0x0/0x194
[<001ba0a8>] schedule_preempt_disabled+0x0/0xc
[<0005b37a>] handle_irq_event+0x20/0x2c
[<0005add4>] generic_handle_irq+0x2c/0x3a
[<00002ab6>] do_IRQ+0x20/0x32
[<0000289e>] auto_irqhandler_fixup+0x4/0x6
[<00003144>] cpu_idle+0x22/0x2e
[<001b8a78>] printk+0x0/0x18
[<0024d112>] start_kernel+0x37a/0x386
[<0003021d>] __do_proc_dointvec+0xb1/0x366
[<0003021d>] __do_proc_dointvec+0xb1/0x366
[<0024c31e>] _sinittext+0x31e/0x9c0
After invoking the irq's handler the kernel sees !irqs_disabled()
and concludes that the handler erroneously enabled interrupts.
However, debugging shows that !irqs_disabled() is true even before
the handler is invoked, which indicates a problem in the platform
code rather than the specific driver.
The warning does not occur in 3.1 or older kernels.
It turns out that the ALLOWINT definition for Atari is incorrect.
The Atari definition of ALLOWINT is ~0x400, the stated purpose of
that is to avoid taking HSYNC interrupts. irqs_disabled() returns
true if the 3-bit ipl & 4 is non-zero. The nfeth interrupt runs at
ipl 3 (it's autovector 3), but 3 & 4 is zero so irqs_disabled() is
false, and the warning above is generated.
When interrupts are explicitly disabled, ipl is set to 7. When they
are enabled, ipl is masked with ALLOWINT. On Atari this will result
in ipl = 3, which blocks interrupts at ipl 3 and below. So how come
nfeth interrupts at ipl 3 are received at all? That's because ipl
is reset to 2 by Atari-specific code in default_idle(), again with
the stated purpose of blocking HSYNC interrupts. This discrepancy
means that ipl 3 can remain blocked for longer than intended.
Both default_idle() and falcon_hblhandler() identify HSYNC with
ipl 2, and the "Atari ST/.../F030 Hardware Register Listing" agrees,
but ALLOWINT is defined as if HSYNC was ipl 3.
[As an experiment I modified default_idle() to reset ipl to 3, and
as expected that resulted in all nfeth interrupts being blocked.]
The fix is simple: define ALLOWINT as ~0x500 instead. This makes
arch_local_irq_enable() consistent with default_idle(), and prevents
the !irqs_disabled() problems for ipl 3 interrupts.
Tested on Atari running in an Aranym VM.
Signed-off-by: Mikael Pettersson <mikpe@it.uu.se>
Tested-by: Michael Schmitz <schmitzmic@googlemail.com> (on Falcon/CT60)
[Geert Uytterhoeven: This version applies to v3.2..v3.4.]
Signed-off-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
partial of commit 8e8b41f9d8 upstream.
As part of commit 463454b5db ("cfg80211: fix interface
combinations check"), this extra check was introduced:
if ((all_iftypes & used_iftypes) != used_iftypes)
goto cont;
However, most wireless NIC drivers did not advertise ADHOC in
wiphy.iface_combinations[i].limits[] and hence we'll get -EBUSY
when we bring up a ADHOC wlan with commands similar to:
# iwconfig wlan0 mode ad-hoc && ifconfig wlan0 up
In commit 8e8b41f9d8 ("cfg80211: enforce lack of interface
combinations"), the change below fixes the issue:
if (total == 1)
return 0;
But it also introduces other dependencies for stable. For example,
a full cherry pick of 8e8b41f9d8 would introduce additional
regressions unless we also start cherry picking driver specific
fixes like the following:
9b4760e ath5k: add possible wiphy interface combinations
1ae2fc2 mac80211_hwsim: advertise interface combinations
20c8e8d ath9k: add possible wiphy interface combinations
And the purpose of the 'if (total == 1)' is to cover the specific
use case (IBSS, adhoc) that was mentioned above. So we just pick
the specific part out from 8e8b41f9d8 here.
Doing so gives stable kernels a way to fix the change introduced
by 463454b5db, without having to make cherry picks specific to
various NIC drivers.
Signed-off-by: Liang Li <liang.li@windriver.com>
Signed-off-by: Paul Gortmaker <paul.gortmaker@windriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4b71ca6bce upstream.
For one, the driver device pointer needs to be filled in, or the lirc core
will refuse to load the driver. And we really need to wire up all the
platform_device bits. This has been tested via the lirc sourceforge tree
and verified to work, been sitting there for months, finally getting
around to sending it. :\
CC: Josh Boyer <jwboyer@redhat.com>
Signed-off-by: Jarod Wilson <jarod@redhat.com>
Signed-off-by: Mauro Carvalho Chehab <mchehab@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b9e0d95c04 upstream.
When the frontend and the backend reside on the same domain, even if we
add pages to the m2p_override, these pages will never be returned by
mfn_to_pfn because the check "get_phys_to_machine(pfn) != mfn" will
always fail, so the pfn of the frontend will be returned instead
(resulting in a deadlock because the frontend pages are already locked).
INFO: task qemu-system-i38:1085 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
qemu-system-i38 D ffff8800cfc137c0 0 1085 1 0x00000000
ffff8800c47ed898 0000000000000282 ffff8800be4596b0 00000000000137c0
ffff8800c47edfd8 ffff8800c47ec010 00000000000137c0 00000000000137c0
ffff8800c47edfd8 00000000000137c0 ffffffff82213020 ffff8800be4596b0
Call Trace:
[<ffffffff81101ee0>] ? __lock_page+0x70/0x70
[<ffffffff81a0fdd9>] schedule+0x29/0x70
[<ffffffff81a0fe80>] io_schedule+0x60/0x80
[<ffffffff81101eee>] sleep_on_page+0xe/0x20
[<ffffffff81a0e1ca>] __wait_on_bit_lock+0x5a/0xc0
[<ffffffff81101ed7>] __lock_page+0x67/0x70
[<ffffffff8106f750>] ? autoremove_wake_function+0x40/0x40
[<ffffffff811867e6>] ? bio_add_page+0x36/0x40
[<ffffffff8110b692>] set_page_dirty_lock+0x52/0x60
[<ffffffff81186021>] bio_set_pages_dirty+0x51/0x70
[<ffffffff8118c6b4>] do_blockdev_direct_IO+0xb24/0xeb0
[<ffffffff811e71a0>] ? ext3_get_blocks_handle+0xe00/0xe00
[<ffffffff8118ca95>] __blockdev_direct_IO+0x55/0x60
[<ffffffff811e71a0>] ? ext3_get_blocks_handle+0xe00/0xe00
[<ffffffff811e91c8>] ext3_direct_IO+0xf8/0x390
[<ffffffff811e71a0>] ? ext3_get_blocks_handle+0xe00/0xe00
[<ffffffff81004b60>] ? xen_mc_flush+0xb0/0x1b0
[<ffffffff81104027>] generic_file_aio_read+0x737/0x780
[<ffffffff813bedeb>] ? gnttab_map_refs+0x15b/0x1e0
[<ffffffff811038f0>] ? find_get_pages+0x150/0x150
[<ffffffff8119736c>] aio_rw_vect_retry+0x7c/0x1d0
[<ffffffff811972f0>] ? lookup_ioctx+0x90/0x90
[<ffffffff81198856>] aio_run_iocb+0x66/0x1a0
[<ffffffff811998b8>] do_io_submit+0x708/0xb90
[<ffffffff81199d50>] sys_io_submit+0x10/0x20
[<ffffffff81a18d69>] system_call_fastpath+0x16/0x1b
The explanation is in the comment within the code:
We need to do this because the pages shared by the frontend
(xen-blkfront) can be already locked (lock_page, called by
do_read_cache_page); when the userspace backend tries to use them
with direct_IO, mfn_to_pfn returns the pfn of the frontend, so
do_blockdev_direct_IO is going to try to lock the same pages
again resulting in a deadlock.
A simplified call graph looks like this:
pygrub QEMU
-----------------------------------------------
do_read_cache_page io_submit
| |
lock_page ext3_direct_IO
|
bio_add_page
|
lock_page
Internally the xen-blkback uses m2p_add_override to swizzle (temporarily)
a 'struct page' to have a different MFN (so that it can point to another
guest). It also can easily find out whether another pfn corresponding
to the mfn exists in the m2p, and can set the FOREIGN bit
in the p2m, making sure that mfn_to_pfn returns the pfn of the backend.
This allows the backend to perform direct_IO on these pages, but as a
side effect prevents the frontend from using get_user_pages_fast on
them while they are being shared with the backend.
Signed-off-by: Stefano Stabellini <stefano.stabellini@eu.citrix.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3f9a5aabd0 upstream.
add_disk() takes gendisk reference on request queue. If driver failed during
initialization and never called add_disk() then that extra reference is not
taken. That reference is put in put_disk(). floppy driver allocates the
disk, allocates queue, sets disk->queue and then relizes that floppy
controller is not present. It tries to tear down everything and tries to
put a reference down in put_disk() which was never taken.
In such error cases cleanup disk->queue before calling put_disk() so that
we never try to put down a reference which was never taken in first place.
Reported-and-tested-by: Suresh Jayaraman <sjayaraman@suse.com>
Tested-by: Dirk Gouders <gouders@et.bocholt.fh-gelsenkirchen.de>
Signed-off-by: Vivek Goyal <vgoyal@redhat.com>
Acked-by: Tejun Heo <tj@kernel.org>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8323f26ce3 upstream
Stefan reported a crash on a kernel before a3e5d1091c ("sched:
Don't call task_group() too many times in set_task_rq()"), he
found the reason to be that the multiple task_group()
invocations in set_task_rq() returned different values.
Looking at all that I found a lack of serialization and plain
wrong comments.
The below tries to fix it using an extra pointer which is
updated under the appropriate scheduler locks. Its not pretty,
but I can't really see another way given how all the cgroup
stuff works.
Reported-and-tested-by: Stefan Bader <stefan.bader@canonical.com>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Link: http://lkml.kernel.org/r/1340364965.18025.71.camel@twins
Signed-off-by: Ingo Molnar <mingo@kernel.org>
(backported to previous file names and layout)
Signed-off-by: Stefan Bader <stefan.bader@canonical.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 141168c36c and
commit 3f806e5098 upstream.
Several fields in struct cpuinfo_x86 were not defined for the
!SMP case, likely to save space. However, those fields still
have some meaning for UP, and keeping them allows some #ifdef
removal from other files. The additional size of the UP kernel
from this change is not significant enough to worry about
keeping up the distinction:
text data bss dec hex filename
4737168 506459 972040 6215667 5ed7f3 vmlinux.o.before
4737444 506459 972040 6215943 5ed907 vmlinux.o.after
for a difference of 276 bytes for an example UP config.
If someone wants those 276 bytes back badly then it should
be implemented in a cleaner way.
Signed-off-by: Kevin Winchester <kjwinchester@gmail.com>
Cc: Steffen Persvold <sp@numascale.com>
Link: http://lkml.kernel.org/r/1324428742-12498-1-git-send-email-kjwinchester@gmail.com
Signed-off-by: Ingo Molnar <mingo@elte.hu>
Signed-off-by: Borislav Petkov <borislav.petkov@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dc32f63453 upstream.
Commit a6bc32b899 ("mm: compaction: introduce sync-light migration for
use by compaction") changed the declaration of migrate_pages() and
migrate_huge_pages().
But it missed changing the argument of migrate_huge_pages() in
soft_offline_huge_page(). In this case, we should call
migrate_huge_pages() with MIGRATE_SYNC.
Additionally, there is a mismatch between type the of argument and the
function declaration for migrate_pages().
Signed-off-by: Joonsoo Kim <js1304@gmail.com>
Cc: Christoph Lameter <cl@linux.com>
Cc: Mel Gorman <mgorman@suse.de>
Acked-by: David Rientjes <rientjes@google.com>
Cc: "Aneesh Kumar K.V" <aneesh.kumar@linux.vnet.ibm.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ce806a3047 upstream.
Linear copy works by adding the offset to the buffer address,
which may end up not being 16-byte aligned.
Some tests I've written for prime_pcopy show that the engine
allows this correctly, so the restriction on lowest 4 bits of
address can be lifted safely.
The comments added were by envyas, I think because I used
a newer version.
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@canonical.com>
[bwh: Backported to 3.2: no # prefixes in nva3_copy.fuc]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e9fbcb4220 upstream.
Each ordered operation has a free callback, and this was called with the
worker spinlock held. Josef made the free callback also call iput,
which we can't do with the spinlock.
This drops the spinlock for the free operation and grabs it again before
moving through the rest of the list. We'll circle back around to this
and find a cleaner way that doesn't bounce the lock around so much.
Signed-off-by: Chris Mason <chris.mason@fusionio.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ca2ccde5e2 upstream.
To have DP behave like VGA/DVI we need to retrain the link
on hotplug. For this to happen we need to force link
training to happen by setting connector dpms to off
before asking it turning it on again.
v2: agd5f
- drop the dp_get_link_status() change in atombios_dp.c
for now. We still need the dpms OFF change.
Signed-off-by: Jerome Glisse <jglisse@redhat.com>
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 266dcba541 upstream.
No need to retrain the link for passive adapters.
v2: agd5f
- no passive DP to VGA adapters, update comments
- assign radeon_connector_atom_dig after we are sure
we have a digital connector as analog connectors
have different private data.
- get new sink type before checking for retrain. No
need to check if it's no longer a DP connection.
Signed-off-by: Jerome Glisse <jglisse@redhat.com>
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8d1c702aa0 upstream.
We want to print link status query failed only if it's
an unexepected fail. If we query to see if we need
link training it might be because there is nothing
connected and thus link status query have the right
to fail in that case.
To avoid printing failure when it's expected, move the
failure message to proper place.
Signed-off-by: Jerome Glisse <jglisse@redhat.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f197ac13f6 upstream.
In the ac.c, power_supply_register()'s return value is not checked.
As a result, the driver's add() ops may return success
even though the device failed to initialize.
For example, some BIOS may describe two ACADs in the same DSDT.
The second ACAD device will fail to register,
but ACPI driver's add() ops returns sucessfully.
The ACPI device will receive ACPI notification and cause OOPS.
https://bugzilla.redhat.com/show_bug.cgi?id=772730
Signed-off-by: Lan Tianyu <tianyu.lan@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0ec4f431eb upstream.
The only checks of the long argument passed to fcntl(fd,F_SETLEASE,.)
are done after converting the long to an int. Thus some illegal values
may be let through and cause problems in later code.
[ They actually *don't* cause problems in mainline, as of Dave Jones's
commit 8d657eb3b4 "Remove easily user-triggerable BUG from
generic_setlease", but we should fix this anyway. And this patch will
be necessary to fix real bugs on earlier kernels. ]
Signed-off-by: J. Bruce Fields <bfields@redhat.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0ff97ebf08 upstream.
Ever since the DAPM performance improvements we've been marking all widgets
as not dirty after each DAPM run. Since _PRE and _POST events aren't part
of the DAPM graph this has rendered them non-functional, they will never be
marked dirty again and thus will never be run again.
Fix this by skipping them when marking widgets as not dirty.
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Acked-by: Liam Girdwood <lrg@ti.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 03179fe923 upstream.
The function ext4_calc_metadata_amount() has side effects, although
it's not obvious from its function name. So if we fail to claim
space, regardless of whether we retry to claim the space again, or
return an error, we need to undo these side effects.
Otherwise we can end up incorrectly calculating the number of metadata
blocks needed for the operation, which was responsible for an xfstests
failure for test #271 when using an ext2 file system with delalloc
enabled.
Reported-by: Brian Foster <bfoster@redhat.com>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 97795d2a5b upstream.
If we hit a condition where we have allocated metadata blocks that
were not appropriately reserved, we risk underflow of
ei->i_reserved_meta_blocks. In turn, this can throw
sbi->s_dirtyclusters_counter significantly out of whack and undermine
the nondelalloc fallback logic in ext4_nonda_switch(). Warn if this
occurs and set i_allocated_meta_blocks to avoid this problem.
This condition is reproduced by xfstests 270 against ext2 with
delalloc enabled:
Mar 28 08:58:02 localhost kernel: [ 171.526344] EXT4-fs (loop1): delayed block allocation failed for inode 14 at logical offset 64486 with max blocks 64 with error -28
Mar 28 08:58:02 localhost kernel: [ 171.526346] EXT4-fs (loop1): This should not happen!! Data will be lost
270 ultimately fails with an inconsistent filesystem and requires an
fsck to repair. The cause of the error is an underflow in
ext4_da_update_reserve_space() due to an unreserved meta block
allocation.
Signed-off-by: Brian Foster <bfoster@redhat.com>
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 55fc05b741 upstream.
At http://dev.laptop.org/ticket/11980 we have determined that the
Marvell CaFe SDHCI controller reports bad card presence during
resume. It reports that no card is present even when it is.
This is a regression -- resume worked back around 2.6.37.
Around 400ms after resuming, a "card inserted" interrupt is
generated, at which point it starts reporting presence.
Work around this hardware oddity by setting the
SDHCI_QUIRK_BROKEN_CARD_DETECTION flag.
Thanks to Chris Ball for helping with diagnosis.
Signed-off-by: Daniel Drake <dsd@laptop.org>
[stable@: please apply to 3.0+]
Signed-off-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bf6932f44a upstream.
From Al Viro:
BTW, speaking of struct file treatment related to sockets -
there's this piece of code in iscsi:
/*
* The SCTP stack needs struct socket->file.
*/
if ((np->np_network_transport == ISCSI_SCTP_TCP) ||
(np->np_network_transport == ISCSI_SCTP_UDP)) {
if (!new_sock->file) {
new_sock->file = kzalloc(
sizeof(struct file), GFP_KERNEL);
For one thing, as far as I can see it'not true - sctp does *not* depend on
socket->file being non-NULL; it does, in one place, check socket->file->f_flags
for O_NONBLOCK, but there it treats NULL socket->file as "flag not set".
Which is the case here anyway - the fake struct file created in
__iscsi_target_login_thread() (and in iscsi_target_setup_login_socket(), with
the same excuse) do *not* get that flag set.
Moreover, it's a bloody serious violation of a bunch of asserts in VFS;
all struct file instances should come from filp_cachep, via get_empty_filp()
(or alloc_file(), which is a wrapper for it). FWIW, I'm very tempted to
do this and be done with the entire mess:
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
Cc: Andy Grover <agrover@redhat.com>
Cc: Hannes Reinecke <hare@suse.de>
Cc: Christoph Hellwig <hch@lst.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b17caa174a upstream.
commit 198439e4 [SCSI] libsas: do not set res = 0 in sas_ex_discover_dev()
commit 19252de6 [SCSI] libsas: fix wide port hotplug issues
The above commits seem to have confused the return value of
sas_ex_discover_dev which is non-zero on failure and
sas_ex_join_wide_port which just indicates short circuiting discovery on
already established ports. The result is random discovery failures
depending on configuration.
Calls to sas_ex_join_wide_port are the source of the trouble as its
return value is errantly assigned to 'res'. Convert it to bool and stop
returning its result up the stack.
Tested-by: Dan Melnic <dan.melnic@amd.com>
Reported-by: Dan Melnic <dan.melnic@amd.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Reviewed-by: Jack Wang <jack_wang@usish.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 26f2f199ff upstream.
Continue running revalidation until no more broadcast devices are
discovered. Fixes cases where re-discovery completes too early in a
domain with multiple expanders with pending re-discovery events.
Servicing BCNs can get backed up behind error recovery.
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 57fc2e335f upstream.
Rapid ata hotplug on a libsas controller results in cases where libsas
is waiting indefinitely on eh to perform an ata probe.
A race exists between scsi_schedule_eh() and scsi_restart_operations()
in the case when scsi_restart_operations() issues i/o to other devices
in the sas domain. When this happens the host state transitions from
SHOST_RECOVERY (set by scsi_schedule_eh) back to SHOST_RUNNING and
->host_busy is non-zero so we put the eh thread to sleep even though
->host_eh_scheduled is active.
Before putting the error handler to sleep we need to check if the
host_state needs to return to SHOST_RECOVERY for another trip through
eh. Since i/o that is released by scsi_restart_operations has been
blocked for at least one eh cycle, this implementation allows those
i/o's to run before another eh cycle starts to discourage hung task
timeouts.
Reported-by: Tom Jackson <thomas.p.jackson@intel.com>
Tested-by: Tom Jackson <thomas.p.jackson@intel.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3b661a92e8 upstream.
The following crash results from cases where the end_device has been
removed before scsi_sysfs_add_sdev has had a chance to run.
BUG: unable to handle kernel NULL pointer dereference at 0000000000000098
IP: [<ffffffff8115e100>] sysfs_create_dir+0x32/0xb6
...
Call Trace:
[<ffffffff8125e4a8>] kobject_add_internal+0x120/0x1e3
[<ffffffff81075149>] ? trace_hardirqs_on+0xd/0xf
[<ffffffff8125e641>] kobject_add_varg+0x41/0x50
[<ffffffff8125e70b>] kobject_add+0x64/0x66
[<ffffffff8131122b>] device_add+0x12d/0x63a
[<ffffffff814b65ea>] ? _raw_spin_unlock_irqrestore+0x47/0x56
[<ffffffff8107de15>] ? module_refcount+0x89/0xa0
[<ffffffff8132f348>] scsi_sysfs_add_sdev+0x4e/0x28a
[<ffffffff8132dcbb>] do_scan_async+0x9c/0x145
...teach scsi_sysfs_add_devices() to check for deleted devices() before
trying to add them, and teach scsi_remove_target() how to remove targets
that have not been added via device_add().
Reported-by: Dariusz Majchrzak <dariusz.majchrzak@intel.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 940f5d47e2 upstream.
When we call scsi_unprep_request() the command associated with the request
gets destroyed and therefore drops its reference on the device. If this was
the only reference, the device may get released and we end up with a NULL
pointer deref when we call blk_requeue_request.
Reported-by: Mike Christie <michaelc@cs.wisc.edu>
Signed-off-by: Bart Van Assche <bvanassche@acm.org>
Reviewed-by: Mike Christie <michaelc@cs.wisc.edu>
Reviewed-by: Tejun Heo <tj@kernel.org>
[jejb: enhance commend and add commit log for stable]
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 67bd941300 upstream.
Use blk_queue_dead() to test whether the queue is dead instead
of !sdev. Since scsi_prep_fn() may be invoked concurrently with
__scsi_remove_device(), keep the queuedata (sdev) pointer in
__scsi_remove_device(). This patch fixes a kernel oops that
can be triggered by USB device removal. See also
http://www.spinics.net/lists/linux-scsi/msg56254.html.
Other changes included in this patch:
- Swap the blk_cleanup_queue() and kfree() calls in
scsi_host_dev_release() to make that code easier to grasp.
- Remove the queue dead check from scsi_run_queue() since the
queue state can change anyway at any point in that function
where the queue lock is not held.
- Remove the queue dead check from the start of scsi_request_fn()
since it is redundant with the scsi_device_online() check.
Reported-by: Jun'ichi Nomura <j-nomura@ce.jp.nec.com>
Signed-off-by: Bart Van Assche <bvanassche@acm.org>
Reviewed-by: Mike Christie <michaelc@cs.wisc.edu>
Reviewed-by: Tejun Heo <tj@kernel.org>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 34f6055c80 upstream.
There are a number of QUEUE_FLAG_DEAD tests. Add blk_queue_dead()
macro and use it.
This patch doesn't introduce any functional difference.
Signed-off-by: Tejun Heo <tj@kernel.org>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9e76e6d031 upstream.
Turn on the pin widget's PIN_OUT bit from playback prepare. The pin is
enabled in open, but is disabled in hdmi_init_pin which is called during
system resume. This causes a system suspend/resume during playback to
mute HDMI/DP. Enabling the pin in prepare instead of open allows calling
snd_pcm_prepare after a system resume to restore audio.
Signed-off-by: Dylan Reid <dgreid@chromium.org>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f60ec4c7df upstream.
This could previously fail if either of the enabled displays was using a
horizontal resolution that is a multiple of 128, and only the leftmost column
of the cursor was (supposed to be) visible at the right edge of that display.
The solution is to move the cursor one pixel to the left in that case.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=33183
Signed-off-by: Michel Dänzer <michel.daenzer@amd.com>
Reviewed-by: Alex Deucher <alexander.deucher@amd.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2c9195e990 upstream.
This did not work because devices are not put into the
pt_domain. Fix this.
Signed-off-by: Joerg Roedel <joerg.roedel@amd.com>
[bwh: Backported to 3.2: do not use iommu_dev_data::passthrough]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6575820221 upstream.
Currently, all workqueue cpu hotplug operations run off
CPU_PRI_WORKQUEUE which is higher than normal notifiers. This is to
ensure that workqueue is up and running while bringing up a CPU before
other notifiers try to use workqueue on the CPU.
Per-cpu workqueues are supposed to remain working and bound to the CPU
for normal CPU_DOWN_PREPARE notifiers. This holds mostly true even
with workqueue offlining running with higher priority because
workqueue CPU_DOWN_PREPARE only creates a bound trustee thread which
runs the per-cpu workqueue without concurrency management without
explicitly detaching the existing workers.
However, if the trustee needs to create new workers, it creates
unbound workers which may wander off to other CPUs while
CPU_DOWN_PREPARE notifiers are in progress. Furthermore, if the CPU
down is cancelled, the per-CPU workqueue may end up with workers which
aren't bound to the CPU.
While reliably reproducible with a convoluted artificial test-case
involving scheduling and flushing CPU burning work items from CPU down
notifiers, this isn't very likely to happen in the wild, and, even
when it happens, the effects are likely to be hidden by the following
successful CPU down.
Fix it by using different priorities for up and down notifiers - high
priority for up operations and low priority for down operations.
Workqueue cpu hotplug operations will soon go through further cleanup.
Signed-off-by: Tejun Heo <tj@kernel.org>
Acked-by: "Rafael J. Wysocki" <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f1b00f4dab upstream.
Commit d83579e2a5 incorporated some
changes from the vendor driver that made it newly important that the
calculated hardware version correctly include the CHIP_92D bit, as all
of the IS_92D_* macros were changed to depend on it. However, this bit
was being unset for dual-mac, dual-phy devices. The vendor driver
behavior was modified to not do this, but unfortunately this change was
not picked up along with the others. This caused scanning in the 2.4GHz
band to be broken, and possibly other bugs as well.
This patch brings the version calculation logic in parity with the
vendor driver in this regard, and in doing so fixes the regression.
However, the version calculation code in general continues to be largely
incoherent and messy, and needs to be cleaned up.
Signed-off-by: Forest Bond <forest.bond@rapidrollout.com>
Signed-off-by: Larry Finger <Larry.Finger@lwfinger.net>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0008204ffe upstream.
The s390 idle accounting code uses a sequence counter which gets used
when the per cpu idle statistics get updated and read.
One assumption on read access is that only when the sequence counter is
even and did not change while reading all values the result is valid.
On cpu hotplug however the per cpu data structure gets initialized via
a cpu hotplug notifier on CPU_ONLINE.
CPU_ONLINE however is too late, since the onlined cpu is already running
and might access the per cpu data. Worst case is that the data structure
gets initialized while an idle thread is updating its idle statistics.
This will result in an uneven sequence counter after an update.
As a result user space tools like top, which access /proc/stat in order
to get idle stats, will busy loop waiting for the sequence counter to
become even again, which will never happen until the queried cpu will
update its idle statistics again. And even then the sequence counter
will only have an even value for a couple of cpu cycles.
Fix this by moving the initialization of the per cpu idle statistics
to cpu_init(). I prefer that solution in favor of changing the
notifier to CPU_UP_PREPARE, which would be a different solution to
the problem.
Signed-off-by: Heiko Carstens <heiko.carstens@de.ibm.com>
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7409a6657a upstream.
Fail UNMAP commands that have more than our reported limit on unmap
descriptors.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
[bwh: Backported to 3.2: adjust filename]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b7fc7f3777 upstream.
It's possible for an initiator to send us an UNMAP command with a
descriptor that is less than 8 bytes; in that case it's really bad for
us to set an unsigned int to that value, subtract 8 from it, and then
use that as a limit for our loop (since the value will wrap around to
a huge positive value).
Fix this by making size be signed and only looping if size >= 16 (ie
if we have at least a full descriptor available).
Also remove offset as an obfuscated name for the constant 8.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1a5fa4576e upstream.
The UNMAP DATA LENGTH and UNMAP BLOCK DESCRIPTOR DATA LENGTH fields
are in the unmap descriptor (the payload transferred to our data out
buffer), not in the CDB itself. Read them from the correct place in
target_emulated_unmap.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2594e29865 upstream.
When processing an UNMAP command, we need to make sure that the number
of blocks we're asked to UNMAP does not exceed our reported maximum
number of blocks per UNMAP, and that the range of blocks we're
unmapping doesn't go past the end of the device.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
[bwh: Backported to 3.2: adjust filename, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e2397c7044 upstream.
Many SCSI commands are defined to return a CHECK CONDITION / ILLEGAL
REQUEST with ASC set to LOGICAL BLOCK ADDRESS OUT OF RANGE if the
initiator sends a command that accesses a too-big LBA. Add an enum
value and case entries so that target code can return this status.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fe020120cb upstream.
mwifiex driver supports 2x2 chips as well. Hence valid mcs values
are 0 to 15. The check for mcs index is corrected in this patch.
For example: if 40MHz is enabled and mcs index is 11, "iw link"
command would show "tx bitrate: 108.0 MBit/s" without this patch.
Now it shows "tx bitrate: 108.0 MBit/s MCS 11 40Mhz" with the patch.
Signed-off-by: Amitkumar Karwar <akarwar@marvell.com>
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b416c9a10b upstream.
Add "memory" attribute in inline assembly language as a compiler
barrier to make sure 4.6.x GCC don't reorder mfmsr().
Signed-off-by: Tiejun Chen <tiejun.chen@windriver.com>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 57b9655d01 upstream.
When a partition table length is corrupted to be close to 1 << 32, the
check for its length may overflow on 32-bit systems and we will think
the length is valid. Later on the kernel can crash trying to read beyond
end of buffer. Fix the check to avoid possible overflow.
Reported-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 952fc18ef9 upstream.
Commit f975d6bcc7 introduced bug which caused ext4_statfs() to
miscalculate the number of file system overhead blocks. This causes
the f_blocks field in the statfs structure to be larger than it should
be. This would in turn cause the "df" output to show the number of
data blocks in the file system and the number of data blocks used to
be larger than they should be.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2102e06a5f upstream.
iso data buffers may have holes in them if some packets were short, so for
iso urbs we should always copy the entire buffer, just like the regular
processcompl does.
Signed-off-by: Hans de Goede <hdegoede@redhat.com>
Acked-by: Alan Stern <stern@rowland.harvard.edu>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c9fc3f778a upstream.
Microcode reloading in a per-core manner is a very bad idea for both
major x86 vendors. And the thing is, we have such interface with which
we can end up with different microcode versions applied on different
cores of an otherwise homogeneous wrt (family,model,stepping) system.
So turn off the possibility of doing that per core and allow it only
system-wide.
This is a minimal fix which we'd like to see in stable too thus the
more-or-less arbitrary decision to allow system-wide reloading only on
the BSP:
$ echo 1 > /sys/devices/system/cpu/cpu0/microcode/reload
...
and disable the interface on the other cores:
$ echo 1 > /sys/devices/system/cpu/cpu23/microcode/reload
-bash: echo: write error: Invalid argument
Also, allowing the reload only from one CPU (the BSP in
that case) doesn't allow the reload procedure to degenerate
into an O(n^2) deal when triggering reloads from all
/sys/devices/system/cpu/cpuX/microcode/reload sysfs nodes
simultaneously.
A more generic fix will follow.
Cc: Henrique de Moraes Holschuh <hmh@hmh.eng.br>
Cc: Peter Zijlstra <peterz@infradead.org>
Signed-off-by: Borislav Petkov <borislav.petkov@amd.com>
Link: http://lkml.kernel.org/r/1340280437-7718-2-git-send-email-bp@amd64.org
Signed-off-by: H. Peter Anvin <hpa@zytor.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 443772d408 upstream.
If function tracing is enabled for some of the low-level suspend/resume
functions, it leads to triple fault during resume from suspend, ultimately
ending up in a reboot instead of a resume (or a total refusal to come out
of suspended state, on some machines).
This issue was explained in more detail in commit f42ac38c59 (ftrace:
disable tracing for suspend to ram). However, the changes made by that commit
got reverted by commit cbe2f5a6e8 (tracing: allow tracing of
suspend/resume & hibernation code again). So, unfortunately since things are
not yet robust enough to allow tracing of low-level suspend/resume functions,
suspend/resume is still broken when ftrace is enabled.
So fix this by disabling function tracing during suspend/resume & hibernation.
Signed-off-by: Srivatsa S. Bhat <srivatsa.bhat@linux.vnet.ibm.com>
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f6fb99cadc upstream.
Make it possible for ext4_count_free to operate on buffers and not
just data in buffer_heads.
Signed-off-by: "Theodore Ts'o" <tytso@mit.edu>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 31bde1ceaa upstream.
A "usb0" interface that has never been connected to a host has an unknown
operstate, and therefore the IFF_RUNNING flag is (incorrectly) asserted
when queried by ifconfig, ifplugd, etc. This is a result of calling
netif_carrier_off() too early in the probe function; it should be called
after register_netdev().
Similar problems have been fixed in many other drivers, e.g.:
e826eafa6 (bonding: Call netif_carrier_off after register_netdevice)
0d672e9f8 (drivers/net: Call netif_carrier_off at the end of the probe)
6a3c869a6 (cxgb4: fix reported state of interfaces without link)
Fix is to move netif_carrier_off() to the end of the function.
Signed-off-by: Kevin Cernekee <cernekee@gmail.com>
Signed-off-by: Felipe Balbi <balbi@ti.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e828b9fb4f upstream.
found in 2012_03_22_RT5572_Linux_STA_v2.6.0.0_DPO
RT3070:
(0x2019,0x5201) Planex Communications, Inc. RT8070
(0x7392,0x4085) 2L Central Europe BV 8070
7392 is Edimax
RT35xx:
(0x1690,0x0761) Askey
was Fujitsu Stylistic 550, but 1690 is Askey
Signed-off-by: Xose Vazquez Perez <xose.vazquez@gmail.com>
Acked-by: Gertjan van Wingerde <gwingerde@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3cf003c08b upstream.
Jian found that when he ran fsx on a 32 bit arch with a large wsize the
process and one of the bdi writeback kthreads would sometimes deadlock
with a stack trace like this:
crash> bt
PID: 2789 TASK: f02edaa0 CPU: 3 COMMAND: "fsx"
#0 [eed63cbc] schedule at c083c5b3
#1 [eed63d80] kmap_high at c0500ec8
#2 [eed63db0] cifs_async_writev at f7fabcd7 [cifs]
#3 [eed63df0] cifs_writepages at f7fb7f5c [cifs]
#4 [eed63e50] do_writepages at c04f3e32
#5 [eed63e54] __filemap_fdatawrite_range at c04e152a
#6 [eed63ea4] filemap_fdatawrite at c04e1b3e
#7 [eed63eb4] cifs_file_aio_write at f7fa111a [cifs]
#8 [eed63ecc] do_sync_write at c052d202
#9 [eed63f74] vfs_write at c052d4ee
#10 [eed63f94] sys_write at c052df4c
#11 [eed63fb0] ia32_sysenter_target at c0409a98
EAX: 00000004 EBX: 00000003 ECX: abd73b73 EDX: 012a65c6
DS: 007b ESI: 012a65c6 ES: 007b EDI: 00000000
SS: 007b ESP: bf8db178 EBP: bf8db1f8 GS: 0033
CS: 0073 EIP: 40000424 ERR: 00000004 EFLAGS: 00000246
Each task would kmap part of its address array before getting stuck, but
not enough to actually issue the write.
This patch fixes this by serializing the marshal_iov operations for
async reads and writes. The idea here is to ensure that cifs
aggressively tries to populate a request before attempting to fulfill
another one. As soon as all of the pages are kmapped for a request, then
we can unlock and allow another one to proceed.
There's no need to do this serialization on non-CONFIG_HIGHMEM arches
however, so optimize all of this out when CONFIG_HIGHMEM isn't set.
Reported-by: Jian Li <jiali@redhat.com>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Steve French <smfrench@gmail.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit eb2dc35d99 upstream.
The 8168evl (RTL_GIGA_MAC_VER_34) based Gigabyte GA-990FXA motherboards
are very prone to NETDEV watchdog problems without this change. See
https://bugzilla.kernel.org/show_bug.cgi?id=42899 for instance.
I don't know why it *works*. It's depressingly effective though.
For the record:
- the problem may go along IOMMU (AMD-Vi) errors but it really looks
like a red herring.
- the patch sets the RX_MULTI_EN bit. If the 8168c doc is any guide,
the chipset now fetches several Rx descriptors at a time.
- long ago the driver ignored the RX_MULTI_EN bit.
e542a2269f changed the RxConfig
settings. Whatever the problem it's now labeled a regression.
- Realtek's own driver can identify two different 8168evl devices
(CFG_METHOD_16 and CFG_METHOD_17) where the r8169 driver only
sees one. It sucks.
Signed-off-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 380e99fc44 upstream.
The strcpy was being used to set the name of the board. Since the
destination char* was read-only and the name is set statically at
compile time; this was both wrong and redundant.
The type of char* is changed to const char* to prevent future errors.
Reported-by: Radek Masin <radek@masin.eu>
Signed-off-by: Ezequiel Garcia <elezegarcia@gmail.com>
[ Taking directly due to vacations - Linus ]
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fd5a42980e upstream.
Just like the module loader, ftrace needs to be updated to use r12
instead of r11 with newer gcc's.
Signed-off-by: Roger Blofeld <blofeldus@yahoo.com>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5aaa0b7a2e upstream.
Follow up on commit 556061b00 ("sched/nohz: Fix rq->cpu_load[]
calculations") since while that fixed the busy case it regressed the
mostly idle case.
Add a callback from the nohz exit to also age the rq->cpu_load[]
array. This closes the hole where either there was no nohz load
balance pass during the nohz, or there was a 'significant' amount of
idle time between the last nohz balance and the nohz exit.
So we'll update unconditionally from the tick to not insert any
accidental 0 load periods while busy, and we try and catch up from
nohz idle balance and nohz exit. Both these are still prone to missing
a jiffy, but that has always been the case.
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: pjt@google.com
Cc: Venkatesh Pallipadi <venki@google.com>
Link: http://lkml.kernel.org/n/tip-kt0trz0apodbf84ucjfdbr1a@git.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
[bwh: Backported to 3.2: adjust filenames and context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 556061b00c upstream.
While investigating why the load-balancer did funny I found that the
rq->cpu_load[] tables were completely screwy.. a bit more digging
revealed that the updates that got through were missing ticks followed
by a catchup of 2 ticks.
The catchup assumes the cpu was idle during that time (since only nohz
can cause missed ticks and the machine is idle etc..) this means that
esp. the higher indices were significantly lower than they ought to
be.
The reason for this is that its not correct to compare against jiffies
on every jiffy on any other cpu than the cpu that updates jiffies.
This patch cludges around it by only doing the catch-up stuff from
nohz_idle_balance() and doing the regular stuff unconditionally from
the tick.
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: pjt@google.com
Cc: Venkatesh Pallipadi <venki@google.com>
Link: http://lkml.kernel.org/n/tip-tp4kj18xdd5aj4vvj0qg55s2@git.kernel.org
Signed-off-by: Ingo Molnar <mingo@kernel.org>
[bwh: Backported to 3.2: adjust filenames and context; keep functions static]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b1c12cbcd0 upstream.
Stable note: Not tracked in Bugzilla. [get|put]_mems_allowed() is extremely
expensive and severely impacted page allocator performance. This
is part of a series of patches that reduce page allocator overhead.
Fix a gcc warning (and bug?) introduced in cc9a6c877 ("cpuset: mm: reduce
large amounts of memory barrier related damage v3")
Local variable "page" can be uninitialized if the nodemask from vma policy
does not intersects with nodemask from cpuset. Even if it doesn't happens
it is better to initialize this variable explicitly than to introduce
a kernel oops in a weird corner case.
mm/hugetlb.c: In function `alloc_huge_page':
mm/hugetlb.c:1135:5: warning: `page' may be used uninitialized in this function
Signed-off-by: Konstantin Khlebnikov <khlebnikov@openvz.org>
Acked-by: Mel Gorman <mgorman@suse.de>
Acked-by: David Rientjes <rientjes@google.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cc9a6c8776 upstream.
Stable note: Not tracked in Bugzilla. [get|put]_mems_allowed() is extremely
expensive and severely impacted page allocator performance. This
is part of a series of patches that reduce page allocator overhead.
Commit c0ff7453bb ("cpuset,mm: fix no node to alloc memory when
changing cpuset's mems") wins a super prize for the largest number of
memory barriers entered into fast paths for one commit.
[get|put]_mems_allowed is incredibly heavy with pairs of full memory
barriers inserted into a number of hot paths. This was detected while
investigating at large page allocator slowdown introduced some time
after 2.6.32. The largest portion of this overhead was shown by
oprofile to be at an mfence introduced by this commit into the page
allocator hot path.
For extra style points, the commit introduced the use of yield() in an
implementation of what looks like a spinning mutex.
This patch replaces the full memory barriers on both read and write
sides with a sequence counter with just read barriers on the fast path
side. This is much cheaper on some architectures, including x86. The
main bulk of the patch is the retry logic if the nodemask changes in a
manner that can cause a false failure.
While updating the nodemask, a check is made to see if a false failure
is a risk. If it is, the sequence number gets bumped and parallel
allocators will briefly stall while the nodemask update takes place.
In a page fault test microbenchmark, oprofile samples from
__alloc_pages_nodemask went from 4.53% of all samples to 1.15%. The
actual results were
3.3.0-rc3 3.3.0-rc3
rc3-vanilla nobarrier-v2r1
Clients 1 UserTime 0.07 ( 0.00%) 0.08 (-14.19%)
Clients 2 UserTime 0.07 ( 0.00%) 0.07 ( 2.72%)
Clients 4 UserTime 0.08 ( 0.00%) 0.07 ( 3.29%)
Clients 1 SysTime 0.70 ( 0.00%) 0.65 ( 6.65%)
Clients 2 SysTime 0.85 ( 0.00%) 0.82 ( 3.65%)
Clients 4 SysTime 1.41 ( 0.00%) 1.41 ( 0.32%)
Clients 1 WallTime 0.77 ( 0.00%) 0.74 ( 4.19%)
Clients 2 WallTime 0.47 ( 0.00%) 0.45 ( 3.73%)
Clients 4 WallTime 0.38 ( 0.00%) 0.37 ( 1.58%)
Clients 1 Flt/sec/cpu 497620.28 ( 0.00%) 520294.53 ( 4.56%)
Clients 2 Flt/sec/cpu 414639.05 ( 0.00%) 429882.01 ( 3.68%)
Clients 4 Flt/sec/cpu 257959.16 ( 0.00%) 258761.48 ( 0.31%)
Clients 1 Flt/sec 495161.39 ( 0.00%) 517292.87 ( 4.47%)
Clients 2 Flt/sec 820325.95 ( 0.00%) 850289.77 ( 3.65%)
Clients 4 Flt/sec 1020068.93 ( 0.00%) 1022674.06 ( 0.26%)
MMTests Statistics: duration
Sys Time Running Test (seconds) 135.68 132.17
User+Sys Time Running Test (seconds) 164.2 160.13
Total Elapsed Time (seconds) 123.46 120.87
The overall improvement is small but the System CPU time is much
improved and roughly in correlation to what oprofile reported (these
performance figures are without profiling so skew is expected). The
actual number of page faults is noticeably improved.
For benchmarks like kernel builds, the overall benefit is marginal but
the system CPU time is slightly reduced.
To test the actual bug the commit fixed I opened two terminals. The
first ran within a cpuset and continually ran a small program that
faulted 100M of anonymous data. In a second window, the nodemask of the
cpuset was continually randomised in a loop.
Without the commit, the program would fail every so often (usually
within 10 seconds) and obviously with the commit everything worked fine.
With this patch applied, it also worked fine so the fix should be
functionally equivalent.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Cc: Miao Xie <miaox@cn.fujitsu.com>
Cc: David Rientjes <rientjes@google.com>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Christoph Lameter <cl@linux.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
[bwh: Forward-ported from 3.0 to 3.2: apply the upstream changes
to get_any_partial()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b95a2f2d48 upstream - WARNING: this is a substitute patch.
Stable note: Not tracked in Bugzilla. This is a partial backport of an
upstream commit addressing a completely different issue
that accidentally contained an important fix. The workload
this patch helps was memcached when IO is started in the
background. memcached should stay resident but without this patch
it gets swapped. Sometimes this manifests as a drop in throughput
but mostly it was observed through /proc/vmstat.
Commit [246e87a9: memcg: fix get_scan_count() for small targets] was meant
to fix a problem whereby small scan targets on memcg were ignored causing
priority to raise too sharply. It forced scanning to take place if the
target was small, memcg or kswapd.
From the time it was introduced it caused excessive reclaim by kswapd
with workloads being pushed to swap that previously would have stayed
resident. This was accidentally fixed in commit [b95a2f2d: mm: vmscan:
convert global reclaim to per-memcg LRU lists] by making it harder for
kswapd to force scan small targets but that patchset is not suitable for
backporting. This was later changed again by commit [90126375: mm/vmscan:
push lruvec pointer into get_scan_count()] into a format that looks
like it would be a straight-forward backport but there is a subtle
difference due to the use of lruvecs.
The impact of the accidental fix is to make it harder for kswapd to force
scan small targets by taking zone->all_unreclaimable into account. This
patch is the closest equivalent available based on what is backported.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 043bcbe5ec upstream.
Stable note: Not tracked in Bugzilla. There were reports of shared
mapped pages being unfairly reclaimed in comparison to older kernels.
This is being addressed over time. Even though the subject
refers to lumpy reclaim, it impacts compaction as well.
Lumpy reclaim does well to stop at a PageAnon when there's no swap, but
better is to stop at any PageSwapBacked, which includes shmem/tmpfs too.
Signed-off-by: Hugh Dickins <hughd@google.com>
Reviewed-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Reviewed-by: Minchan Kim <minchan@kernel.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 86cfd3a450 upstream.
Stable note: Not tracked in Bugzilla. This patch reduces kswapd CPU
usage on swapless systems with high anonymous memory usage.
It's pointless to continue reclaiming when we have no swap space and lots
of anon pages in the inactive list.
Without this patch, it is possible when swap is disabled to continue
trying to reclaim when there are only anonymous pages in the system even
though that will not make any progress.
Signed-off-by: Minchan Kim <minchan@kernel.org>
Cc: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Acked-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c909e99364 upstream.
Stable note: Not tracked in Bugzilla. There were reports of shared
mapped pages being unfairly reclaimed in comparison to older kernels.
This is being addressed over time.
Logic added in commit 8cab4754d2 ("vmscan: make mapped executable pages
the first class citizen") was noticeably weakened in commit
6457474624 ("vmscan: detect mapped file pages used only once").
Currently these pages can become "first class citizens" only after second
usage. After this patch page_check_references() will activate they after
first usage, and executable code gets yet better chance to stay in memory.
Signed-off-by: Konstantin Khlebnikov <khlebnikov@openvz.org>
Cc: Pekka Enberg <penberg@kernel.org>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Wu Fengguang <fengguang.wu@intel.com>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Nick Piggin <npiggin@kernel.dk>
Cc: Mel Gorman <mel@csn.ul.ie>
Cc: Shaohua Li <shaohua.li@intel.com>
Cc: Rik van Riel <riel@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 34dbc67a64 upstream.
Stable note: Not tracked in Bugzilla. There were reports of shared
mapped pages being unfairly reclaimed in comparison to older kernels.
This is being addressed over time. The specific workload being
addressed here in described in paragraph four and while paragraph
five says it did not help performance as such, it made a difference
to major page faults. I'm aware of at least one bug for a large
vendor that was due to increased major faults.
Commit 6457474624 ("vmscan: detect mapped file pages used only once")
greatly decreases lifetime of single-used mapped file pages.
Unfortunately it also decreases life time of all shared mapped file
pages. Because after commit bf3f3bc5e7 ("mm: don't mark_page_accessed
in fault path") page-fault handler does not mark page active or even
referenced.
Thus page_check_references() activates file page only if it was used twice
while it stays in inactive list, meanwhile it activates anon pages after
first access. Inactive list can be small enough, this way reclaimer can
accidentally throw away any widely used page if it wasn't used twice in
short period.
After this patch page_check_references() also activate file mapped page at
first inactive list scan if this page is already used multiple times via
several ptes.
I found this while trying to fix degragation in rhel6 (~2.6.32) from rhel5
(~2.6.18). There a complete mess with >100 web/mail/spam/ftp containers,
they share all their files but there a lot of anonymous pages: ~500mb
shared file mapped memory and 15-20Gb non-shared anonymous memory. In
this situation major-pagefaults are very costly, because all containers
share the same page. In my load kernel created a disproportionate
pressure on the file memory, compared with the anonymous, they equaled
only if I raise swappiness up to 150 =)
These patches actually wasn't helped a lot in my problem, but I saw
noticable (10-20 times) reduce in count and average time of
major-pagefault in file-mapped areas.
Actually both patches are fixes for commit v2.6.33-5448-g6457474, because
it was aimed at one scenario (singly used pages), but it breaks the logic
in other scenarios (shared and/or executable pages)
Signed-off-by: Konstantin Khlebnikov <khlebnikov@openvz.org>
Acked-by: Pekka Enberg <penberg@kernel.org>
Acked-by: Minchan Kim <minchan.kim@gmail.com>
Reviewed-by: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Wu Fengguang <fengguang.wu@intel.com>
Cc: Johannes Weiner <hannes@cmpxchg.org>
Cc: Nick Piggin <npiggin@kernel.dk>
Cc: Mel Gorman <mel@csn.ul.ie>
Cc: Shaohua Li <shaohua.li@intel.com>
Cc: Rik van Riel <riel@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0cee34fd72 upstream.
Stable note: Not tracked on Bugzilla. THP and compaction was found to
aggressively reclaim pages and stall systems under different
situations that was addressed piecemeal over time.
If compaction can proceed for a given zone, shrink_zones() does not
reclaim any more pages from it. After commit [e0c2327: vmscan: abort
reclaim/compaction if compaction can proceed], do_try_to_free_pages()
tries to finish as soon as possible once one zone can compact.
This was intended to prevent slabs being shrunk unnecessarily but there
are side-effects. One is that a small zone that is ready for compaction
will abort reclaim even if the chances of successfully allocating a THP
from that zone is small. It also means that reclaim can return too early
even though sc->nr_to_reclaim pages were not reclaimed.
This partially reverts the commit until it is proven that slabs are really
being shrunk unnecessarily but preserves the check to return 1 to avoid
OOM if reclaim was aborted prematurely.
[aarcange@redhat.com: This patch replaces a revert from Andrea]
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7335084d44 upstream.
Stable note: Not tracked in Bugzilla. This patch makes later patches
easier to apply but otherwise has little to justify it. The
problem it fixes was never observed but the source of the
theoretical problem did not exist for very long.
During direct reclaim it is possible that reclaim will be aborted so that
compaction can be attempted to satisfy a high-order allocation. If this
decision is made before any pages are reclaimed, it is possible that 0 is
returned to the page allocator potentially triggering an OOM. This has
not been observed but it is a possibility so this patch addresses it.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fe4b1b244b upstream.
Stable note: Not tracked on Bugzilla. THP and compaction was found to
aggressively reclaim pages and stall systems under different
situations that was addressed piecemeal over time. This patch
addresses a problem where the fix regressed THP allocation
success rates.
In commit e0887c19 ("vmscan: limit direct reclaim for higher order
allocations"), Rik noted that reclaim was too aggressive when THP was
enabled. In his initial patch he used the number of free pages to decide
if reclaim should abort for compaction. My feedback was that reclaim and
compaction should be using the same logic when deciding if reclaim should
be aborted.
Unfortunately, this had the effect of reducing THP success rates when the
workload included something like streaming reads that continually
allocated pages. The window during which compaction could run and return
a THP was too small.
This patch combines Rik's two patches together. compaction_suitable() is
still used to decide if reclaim should be aborted to allow compaction is
used. However, it will also ensure that there is a reasonable buffer of
free pages available. This improves upon the THP allocation success rates
but bounds the number of pages that are freed for compaction.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel<riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a6bc32b899 upstream.
Stable note: Not tracked in Buzilla. This was part of a series that
reduced interactivity stalls experienced when THP was enabled.
These stalls were particularly noticable when copying data
to a USB stick but the experiences for users varied a lot.
This patch adds a lightweight sync migrate operation MIGRATE_SYNC_LIGHT
mode that avoids writing back pages to backing storage. Async compaction
maps to MIGRATE_ASYNC while sync compaction maps to MIGRATE_SYNC_LIGHT.
For other migrate_pages users such as memory hotplug, MIGRATE_SYNC is
used.
This avoids sync compaction stalling for an excessive length of time,
particularly when copying files to a USB stick where there might be a
large number of dirty pages backed by a filesystem that does not support
->writepages.
[aarcange@redhat.com: This patch is heavily based on Andrea's work]
[akpm@linux-foundation.org: fix fs/nfs/write.c build]
[akpm@linux-foundation.org: fix fs/btrfs/disk-io.c build]
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c824493528 upstream.
Stable note: Not tracked in Bugzilla. A fix aimed at preserving page aging
information by reducing LRU list churning had the side-effect of
reducing THP allocation success rates. This was part of a series
to restore the success rates while preserving the reclaim fix.
Commit 39deaf85 ("mm: compaction: make isolate_lru_page() filter-aware")
noted that compaction does not migrate dirty or writeback pages and that
is was meaningless to pick the page and re-add it to the LRU list. This
had to be partially reverted because some dirty pages can be migrated by
compaction without blocking.
This patch updates "mm: compaction: make isolate_lru_page" by skipping
over pages that migration has no possibility of migrating to minimise LRU
disruption.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel<riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Reviewed-by: Minchan Kim <minchan@kernel.org>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 66199712e9 upstream.
Stable note: Not tracked in Buzilla. This was part of a series that
reduced interactivity stalls experienced when THP was enabled.
If compaction is deferred, direct reclaim is used to try to free enough
pages for the allocation to succeed. For small high-orders, this has a
reasonable chance of success. However, if the caller has specified
__GFP_NO_KSWAPD to limit the disruption to the system, it makes more sense
to fail the allocation rather than stall the caller in direct reclaim.
This patch skips direct reclaim if compaction is deferred and the caller
specifies __GFP_NO_KSWAPD.
Async compaction only considers a subset of pages so it is possible for
compaction to be deferred prematurely and not enter direct reclaim even in
cases where it should. To compensate for this, this patch also defers
compaction only if sync compaction failed.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Acked-by: Minchan Kim <minchan.kim@gmail.com>
Reviewed-by: Rik van Riel<riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b969c4ab9f upstream.
Stable note: Not tracked in Bugzilla. A fix aimed at preserving page
aging information by reducing LRU list churning had the side-effect
of reducing THP allocation success rates. This was part of a series
to restore the success rates while preserving the reclaim fix.
Asynchronous compaction is used when allocating transparent hugepages to
avoid blocking for long periods of time. Due to reports of stalling,
there was a debate on disabling synchronous compaction but this severely
impacted allocation success rates. Part of the reason was that many dirty
pages are skipped in asynchronous compaction by the following check;
if (PageDirty(page) && !sync &&
mapping->a_ops->migratepage != migrate_page)
rc = -EBUSY;
This skips over all mapping aops using buffer_migrate_page() even though
it is possible to migrate some of these pages without blocking. This
patch updates the ->migratepage callback with a "sync" parameter. It is
the responsibility of the callback to fail gracefully if migration would
block.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Rik van Riel <riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a77ebd333c upstream.
Stable note: Not tracked in Bugzilla. A fix aimed at preserving page aging
information by reducing LRU list churning had the side-effect of
reducing THP allocation success rates. This was part of a series
to restore the success rates while preserving the reclaim fix.
Short summary: There are severe stalls when a USB stick using VFAT is
used with THP enabled that are reduced by this series. If you are
experiencing this problem, please test and report back and considering I
have seen complaints from openSUSE and Fedora users on this as well as a
few private mails, I'm guessing it's a widespread issue. This is a new
type of USB-related stall because it is due to synchronous compaction
writing where as in the past the big problem was dirty pages reaching
the end of the LRU and being written by reclaim.
Am cc'ing Andrew this time and this series would replace
mm-do-not-stall-in-synchronous-compaction-for-thp-allocations.patch.
I'm also cc'ing Dave Jones as he might have merged that patch to Fedora
for wider testing and ideally it would be reverted and replaced by this
series.
That said, the later patches could really do with some review. If this
series is not the answer then a new direction needs to be discussed
because as it is, the stalls are unacceptable as the results in this
leader show.
For testers that try backporting this to 3.1, it won't work because
there is a non-obvious dependency on not writing back pages in direct
reclaim so you need those patches too.
Changelog since V5
o Rebase to 3.2-rc5
o Tidy up the changelogs a bit
Changelog since V4
o Added reviewed-bys, credited Andrea properly for sync-light
o Allow dirty pages without mappings to be considered for migration
o Bound the number of pages freed for compaction
o Isolate PageReclaim pages on their own LRU list
This is against 3.2-rc5 and follows on from discussions on "mm: Do
not stall in synchronous compaction for THP allocations" and "[RFC
PATCH 0/5] Reduce compaction-related stalls". Initially, the proposed
patch eliminated stalls due to compaction which sometimes resulted in
user-visible interactivity problems on browsers by simply never using
sync compaction. The downside was that THP success allocation rates
were lower because dirty pages were not being migrated as reported by
Andrea. His approach at fixing this was nacked on the grounds that
it reverted fixes from Rik merged that reduced the amount of pages
reclaimed as it severely impacted his workloads performance.
This series attempts to reconcile the requirements of maximising THP
usage, without stalling in a user-visible fashion due to compaction
or cheating by reclaiming an excessive number of pages.
Patch 1 partially reverts commit 39deaf85 to allow migration to isolate
dirty pages. This is because migration can move some dirty
pages without blocking.
Patch 2 notes that the /proc/sys/vm/compact_memory handler is not using
synchronous compaction when it should be. This is unrelated
to the reported stalls but is worth fixing.
Patch 3 checks if we isolated a compound page during lumpy scan and
account for it properly. For the most part, this affects
tracing so it's unrelated to the stalls but worth fixing.
Patch 4 notes that it is possible to abort reclaim early for compaction
and return 0 to the page allocator potentially entering the
"may oom" path. This has not been observed in practice but
the rest of the series potentially makes it easier to happen.
Patch 5 adds a sync parameter to the migratepage callback and gives
the callback responsibility for migrating the page without
blocking if sync==false. For example, fallback_migrate_page
will not call writepage if sync==false. This increases the
number of pages that can be handled by asynchronous compaction
thereby reducing stalls.
Patch 6 restores filter-awareness to isolate_lru_page for migration.
In practice, it means that pages under writeback and pages
without a ->migratepage callback will not be isolated
for migration.
Patch 7 avoids calling direct reclaim if compaction is deferred but
makes sure that compaction is only deferred if sync
compaction was used.
Patch 8 introduces a sync-light migration mechanism that sync compaction
uses. The objective is to allow some stalls but to not call
->writepage which can lead to significant user-visible stalls.
Patch 9 notes that while we want to abort reclaim ASAP to allow
compation to go ahead that we leave a very small window of
opportunity for compaction to run. This patch allows more pages
to be freed by reclaim but bounds the number to a reasonable
level based on the high watermark on each zone.
Patch 10 allows slabs to be shrunk even after compaction_ready() is
true for one zone. This is to avoid a problem whereby a single
small zone can abort reclaim even though no pages have been
reclaimed and no suitably large zone is in a usable state.
Patch 11 fixes a problem with the rate of page scanning. As reclaim is
rarely stalling on pages under writeback it means that scan
rates are very high. This is particularly true for direct
reclaim which is not calling writepage. The vmstat figures
implied that much of this was busy work with PageReclaim pages
marked for immediate reclaim. This patch is a prototype that
moves these pages to their own LRU list.
This has been tested and other than 2 USB keys getting trashed,
nothing horrible fell out. That said, I am a bit unhappy with the
rescue logic in patch 11 but did not find a better way around it. It
does significantly reduce scan rates and System CPU time indicating
it is the right direction to take.
What is of critical importance is that stalls due to compaction
are massively reduced even though sync compaction was still
allowed. Testing from people complaining about stalls copying to USBs
with THP enabled are particularly welcome.
The following tests all involve THP usage and USB keys in some
way. Each test follows this type of pattern
1. Read from some fast fast storage, be it raw device or file. Each time
the copy finishes, start again until the test ends
2. Write a large file to a filesystem on a USB stick. Each time the copy
finishes, start again until the test ends
3. When memory is low, start an alloc process that creates a mapping
the size of physical memory to stress THP allocation. This is the
"real" part of the test and the part that is meant to trigger
stalls when THP is enabled. Copying continues in the background.
4. Record the CPU usage and time to execute of the alloc process
5. Record the number of THP allocs and fallbacks as well as the number of THP
pages in use a the end of the test just before alloc exited
6. Run the test 5 times to get an idea of variability
7. Between each run, sync is run and caches dropped and the test
waits until nr_dirty is a small number to avoid interference
or caching between iterations that would skew the figures.
The individual tests were then
writebackCPDeviceBasevfat
Disable THP, read from a raw device (sda), vfat on USB stick
writebackCPDeviceBaseext4
Disable THP, read from a raw device (sda), ext4 on USB stick
writebackCPDevicevfat
THP enabled, read from a raw device (sda), vfat on USB stick
writebackCPDeviceext4
THP enabled, read from a raw device (sda), ext4 on USB stick
writebackCPFilevfat
THP enabled, read from a file on fast storage and USB, both vfat
writebackCPFileext4
THP enabled, read from a file on fast storage and USB, both ext4
The kernels tested were
3.1 3.1
vanilla 3.2-rc5
freemore Patches 1-10
immediate Patches 1-11
andrea The 8 patches Andrea posted as a basis of comparison
The results are very long unfortunately. I'll start with the case
where we are not using THP at all
writebackCPDeviceBasevfat
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
System Time 1.28 ( 0.00%) 54.49 (-4143.46%) 48.63 (-3687.69%) 4.69 ( -265.11%) 51.88 (-3940.81%)
+/- 0.06 ( 0.00%) 2.45 (-4305.55%) 4.75 (-8430.57%) 7.46 (-13282.76%) 4.76 (-8440.70%)
User Time 0.09 ( 0.00%) 0.05 ( 40.91%) 0.06 ( 29.55%) 0.07 ( 15.91%) 0.06 ( 27.27%)
+/- 0.02 ( 0.00%) 0.01 ( 45.39%) 0.02 ( 25.07%) 0.00 ( 77.06%) 0.01 ( 52.24%)
Elapsed Time 110.27 ( 0.00%) 56.38 ( 48.87%) 49.95 ( 54.70%) 11.77 ( 89.33%) 53.43 ( 51.54%)
+/- 7.33 ( 0.00%) 3.77 ( 48.61%) 4.94 ( 32.63%) 6.71 ( 8.50%) 4.76 ( 35.03%)
THP Active 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
+/- 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
Fault Alloc 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
+/- 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
Fault Fallback 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
+/- 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%) 0.00 ( 0.00%)
The THP figures are obviously all 0 because THP was enabled. The
main thing to watch is the elapsed times and how they compare to
times when THP is enabled later. It's also important to note that
elapsed time is improved by this series as System CPu time is much
reduced.
writebackCPDevicevfat
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
System Time 1.22 ( 0.00%) 13.89 (-1040.72%) 46.40 (-3709.20%) 4.44 ( -264.37%) 47.37 (-3789.33%)
+/- 0.06 ( 0.00%) 22.82 (-37635.56%) 3.84 (-6249.44%) 6.48 (-10618.92%) 6.60
(-10818.53%)
User Time 0.06 ( 0.00%) 0.06 ( -6.90%) 0.05 ( 17.24%) 0.05 ( 13.79%) 0.04 ( 31.03%)
+/- 0.01 ( 0.00%) 0.01 ( 33.33%) 0.01 ( 33.33%) 0.01 ( 39.14%) 0.01 ( 25.46%)
Elapsed Time 10445.54 ( 0.00%) 2249.92 ( 78.46%) 70.06 ( 99.33%) 16.59 ( 99.84%) 472.43 (
95.48%)
+/- 643.98 ( 0.00%) 811.62 ( -26.03%) 10.02 ( 98.44%) 7.03 ( 98.91%) 59.99 ( 90.68%)
THP Active 15.60 ( 0.00%) 35.20 ( 225.64%) 65.00 ( 416.67%) 70.80 ( 453.85%) 62.20 ( 398.72%)
+/- 18.48 ( 0.00%) 51.29 ( 277.59%) 15.99 ( 86.52%) 37.91 ( 205.18%) 22.02 ( 119.18%)
Fault Alloc 121.80 ( 0.00%) 76.60 ( 62.89%) 155.40 ( 127.59%) 181.20 ( 148.77%) 286.60 ( 235.30%)
+/- 73.51 ( 0.00%) 61.11 ( 83.12%) 34.89 ( 47.46%) 31.88 ( 43.36%) 68.13 ( 92.68%)
Fault Fallback 881.20 ( 0.00%) 926.60 ( -5.15%) 847.60 ( 3.81%) 822.00 ( 6.72%) 716.60 ( 18.68%)
+/- 73.51 ( 0.00%) 61.26 ( 16.67%) 34.89 ( 52.54%) 31.65 ( 56.94%) 67.75 ( 7.84%)
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 3540.88 1945.37 716.04 64.97 1937.03
Total Elapsed Time (seconds) 52417.33 11425.90 501.02 230.95 2520.28
The first thing to note is the "Elapsed Time" for the vanilla kernels
of 2249 seconds versus 56 with THP disabled which might explain the
reports of USB stalls with THP enabled. Applying the patches brings
performance in line with THP-disabled performance while isolating
pages for immediate reclaim from the LRU cuts down System CPU time.
The "Fault Alloc" success rate figures are also improved. The vanilla
kernel only managed to allocate 76.6 pages on average over the course
of 5 iterations where as applying the series allocated 181.20 on
average albeit it is well within variance. It's worth noting that
applies the series at least descreases the amount of variance which
implies an improvement.
Andrea's series had a higher success rate for THP allocations but
at a severe cost to elapsed time which is still better than vanilla
but still much worse than disabling THP altogether. One can bring my
series close to Andrea's by removing this check
/*
* If compaction is deferred for high-order allocations, it is because
* sync compaction recently failed. In this is the case and the caller
* has requested the system not be heavily disrupted, fail the
* allocation now instead of entering direct reclaim
*/
if (deferred_compaction && (gfp_mask & __GFP_NO_KSWAPD))
goto nopage;
I didn't include a patch that removed the above check because hurting
overall performance to improve the THP figure is not what the average
user wants. It's something to consider though if someone really wants
to maximise THP usage no matter what it does to the workload initially.
This is summary of vmstat figures from the same test.
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
Page Ins 3257266139 1111844061 17263623 10901575 161423219
Page Outs 81054922 30364312 3626530 3657687 8753730
Swap Ins 3294 2851 6560 4964 4592
Swap Outs 390073 528094 620197 790912 698285
Direct pages scanned 1077581700 3024951463 1764930052 115140570 5901188831
Kswapd pages scanned 34826043 7112868 2131265 1686942 1893966
Kswapd pages reclaimed 28950067 4911036 1246044 966475 1497726
Direct pages reclaimed 805148398 280167837 3623473 2215044 40809360
Kswapd efficiency 83% 69% 58% 57% 79%
Kswapd velocity 664.399 622.521 4253.852 7304.360 751.490
Direct efficiency 74% 9% 0% 1% 0%
Direct velocity 20557.737 264745.137 3522673.849 498551.938 2341481.435
Percentage direct scans 96% 99% 99% 98% 99%
Page writes by reclaim 722646 529174 620319 791018 699198
Page writes file 332573 1080 122 106 913
Page writes anon 390073 528094 620197 790912 698285
Page reclaim immediate 0 2552514720 1635858848 111281140 5478375032
Page rescued immediate 0 0 0 87848 0
Slabs scanned 23552 23552 9216 8192 9216
Direct inode steals 231 0 0 0 0
Kswapd inode steals 0 0 0 0 0
Kswapd skipped wait 28076 786 0 61 6
THP fault alloc 609 383 753 906 1433
THP collapse alloc 12 6 0 0 6
THP splits 536 211 456 593 1136
THP fault fallback 4406 4633 4263 4110 3583
THP collapse fail 120 127 0 0 4
Compaction stalls 1810 728 623 779 3200
Compaction success 196 53 60 80 123
Compaction failures 1614 675 563 699 3077
Compaction pages moved 193158 53545 243185 333457 226688
Compaction move failure 9952 9396 16424 23676 45070
The main things to look at are
1. Page In/out figures are much reduced by the series.
2. Direct page scanning is incredibly high (264745.137 pages scanned
per second on the vanilla kernel) but isolating PageReclaim pages
on their own list reduces the number of pages scanned significantly.
3. The fact that "Page rescued immediate" is a positive number implies
that we sometimes race removing pages from the LRU_IMMEDIATE list
that need to be put back on a normal LRU but it happens only for
0.07% of the pages marked for immediate reclaim.
writebackCPDeviceext4
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
System Time 1.51 ( 0.00%) 1.77 ( -17.66%) 1.46 ( 2.92%) 1.15 ( 23.77%) 1.89 ( -25.63%)
+/- 0.27 ( 0.00%) 0.67 ( -148.52%) 0.33 ( -22.76%) 0.30 ( -11.15%) 0.19 ( 30.16%)
User Time 0.03 ( 0.00%) 0.04 ( -37.50%) 0.05 ( -62.50%) 0.07 ( -112.50%) 0.04 ( -18.75%)
+/- 0.01 ( 0.00%) 0.02 ( -146.64%) 0.02 ( -97.91%) 0.02 ( -75.59%) 0.02 ( -63.30%)
Elapsed Time 124.93 ( 0.00%) 114.49 ( 8.36%) 96.77 ( 22.55%) 27.48 ( 78.00%) 205.70 ( -64.65%)
+/- 20.20 ( 0.00%) 74.39 ( -268.34%) 59.88 ( -196.48%) 7.72 ( 61.79%) 25.03 ( -23.95%)
THP Active 161.80 ( 0.00%) 83.60 ( 51.67%) 141.20 ( 87.27%) 84.60 ( 52.29%) 82.60 ( 51.05%)
+/- 71.95 ( 0.00%) 43.80 ( 60.88%) 26.91 ( 37.40%) 59.02 ( 82.03%) 52.13 ( 72.45%)
Fault Alloc 471.40 ( 0.00%) 228.60 ( 48.49%) 282.20 ( 59.86%) 225.20 ( 47.77%) 388.40 ( 82.39%)
+/- 88.07 ( 0.00%) 87.42 ( 99.26%) 73.79 ( 83.78%) 109.62 ( 124.47%) 82.62 ( 93.81%)
Fault Fallback 531.60 ( 0.00%) 774.60 ( -45.71%) 720.80 ( -35.59%) 777.80 ( -46.31%) 614.80 ( -15.65%)
+/- 88.07 ( 0.00%) 87.26 ( 0.92%) 73.79 ( 16.22%) 109.62 ( -24.47%) 82.29 ( 6.56%)
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 50.22 33.76 30.65 24.14 128.45
Total Elapsed Time (seconds) 1113.73 1132.19 1029.45 759.49 1707.26
Similar test but the USB stick is using ext4 instead of vfat. As
ext4 does not use writepage for migration, the large stalls due to
compaction when THP is enabled are not observed. Still, isolating
PageReclaim pages on their own list helped completion time largely
by reducing the number of pages scanned by direct reclaim although
time spend in congestion_wait could also be a factor.
Again, Andrea's series had far higher success rates for THP allocation
at the cost of elapsed time. I didn't look too closely but a quick
look at the vmstat figures tells me kswapd reclaimed 8 times more pages
than the patch series and direct reclaim reclaimed roughly three times
as many pages. It follows that if memory is aggressively reclaimed,
there will be more available for THP.
writebackCPFilevfat
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
System Time 1.76 ( 0.00%) 29.10 (-1555.52%) 46.01 (-2517.18%) 4.79 ( -172.35%) 54.89 (-3022.53%)
+/- 0.14 ( 0.00%) 25.61 (-18185.17%) 2.15 (-1434.83%) 6.60 (-4610.03%) 9.75
(-6863.76%)
User Time 0.05 ( 0.00%) 0.07 ( -45.83%) 0.05 ( -4.17%) 0.06 ( -29.17%) 0.06 ( -16.67%)
+/- 0.02 ( 0.00%) 0.02 ( 20.11%) 0.02 ( -3.14%) 0.01 ( 31.58%) 0.01 ( 47.41%)
Elapsed Time 22520.79 ( 0.00%) 1082.85 ( 95.19%) 73.30 ( 99.67%) 32.43 ( 99.86%) 291.84 ( 98.70%)
+/- 7277.23 ( 0.00%) 706.29 ( 90.29%) 19.05 ( 99.74%) 17.05 ( 99.77%) 125.55 ( 98.27%)
THP Active 83.80 ( 0.00%) 12.80 ( 15.27%) 15.60 ( 18.62%) 13.00 ( 15.51%) 0.80 ( 0.95%)
+/- 66.81 ( 0.00%) 20.19 ( 30.22%) 5.92 ( 8.86%) 15.06 ( 22.54%) 1.17 ( 1.75%)
Fault Alloc 171.00 ( 0.00%) 67.80 ( 39.65%) 97.40 ( 56.96%) 125.60 ( 73.45%) 133.00 ( 77.78%)
+/- 82.91 ( 0.00%) 30.69 ( 37.02%) 53.91 ( 65.02%) 55.05 ( 66.40%) 21.19 ( 25.56%)
Fault Fallback 832.00 ( 0.00%) 935.20 ( -12.40%) 906.00 ( -8.89%) 877.40 ( -5.46%) 870.20 ( -4.59%)
+/- 82.91 ( 0.00%) 30.69 ( 62.98%) 54.01 ( 34.86%) 55.05 ( 33.60%) 20.91 ( 74.78%)
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 7229.81 928.42 704.52 80.68 1330.76
Total Elapsed Time (seconds) 112849.04 5618.69 571.11 360.54 1664.28
In this case, the test is reading/writing only from filesystems but as
it's vfat, it's slow due to calling writepage during compaction. Little
to observe really - the time to complete the test goes way down
with the series applied and THP allocation success rates go up in
comparison to 3.2-rc5. The success rates are lower than 3.1.0 but
the elapsed time for that kernel is abysmal so it is not really a
sensible comparison.
As before, Andrea's series allocates more THPs at the cost of overall
performance.
writebackCPFileext4
3.1.0-vanilla rc5-vanilla freemore-v6r1 isolate-v6r1 andrea-v2r1
System Time 1.51 ( 0.00%) 1.77 ( -17.66%) 1.46 ( 2.92%) 1.15 ( 23.77%) 1.89 ( -25.63%)
+/- 0.27 ( 0.00%) 0.67 ( -148.52%) 0.33 ( -22.76%) 0.30 ( -11.15%) 0.19 ( 30.16%)
User Time 0.03 ( 0.00%) 0.04 ( -37.50%) 0.05 ( -62.50%) 0.07 ( -112.50%) 0.04 ( -18.75%)
+/- 0.01 ( 0.00%) 0.02 ( -146.64%) 0.02 ( -97.91%) 0.02 ( -75.59%) 0.02 ( -63.30%)
Elapsed Time 124.93 ( 0.00%) 114.49 ( 8.36%) 96.77 ( 22.55%) 27.48 ( 78.00%) 205.70 ( -64.65%)
+/- 20.20 ( 0.00%) 74.39 ( -268.34%) 59.88 ( -196.48%) 7.72 ( 61.79%) 25.03 ( -23.95%)
THP Active 161.80 ( 0.00%) 83.60 ( 51.67%) 141.20 ( 87.27%) 84.60 ( 52.29%) 82.60 ( 51.05%)
+/- 71.95 ( 0.00%) 43.80 ( 60.88%) 26.91 ( 37.40%) 59.02 ( 82.03%) 52.13 ( 72.45%)
Fault Alloc 471.40 ( 0.00%) 228.60 ( 48.49%) 282.20 ( 59.86%) 225.20 ( 47.77%) 388.40 ( 82.39%)
+/- 88.07 ( 0.00%) 87.42 ( 99.26%) 73.79 ( 83.78%) 109.62 ( 124.47%) 82.62 ( 93.81%)
Fault Fallback 531.60 ( 0.00%) 774.60 ( -45.71%) 720.80 ( -35.59%) 777.80 ( -46.31%) 614.80 ( -15.65%)
+/- 88.07 ( 0.00%) 87.26 ( 0.92%) 73.79 ( 16.22%) 109.62 ( -24.47%) 82.29 ( 6.56%)
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 50.22 33.76 30.65 24.14 128.45
Total Elapsed Time (seconds) 1113.73 1132.19 1029.45 759.49 1707.26
Same type of story - elapsed times go down. In this case, allocation
success rates are roughtly the same. As before, Andrea's has higher
success rates but takes a lot longer.
Overall the series does reduce latencies and while the tests are
inherency racy as alloc competes with the cp processes, the variability
was included. The THP allocation rates are not as high as they could
be but that is because we would have to be more aggressive about
reclaim and compaction impacting overall performance.
This patch:
Commit 39deaf85 ("mm: compaction: make isolate_lru_page() filter-aware")
noted that compaction does not migrate dirty or writeback pages and that
is was meaningless to pick the page and re-add it to the LRU list.
What was missed during review is that asynchronous migration moves dirty
pages if their ->migratepage callback is migrate_page() because these can
be moved without blocking. This potentially impacted hugepage allocation
success rates by a factor depending on how many dirty pages are in the
system.
This patch partially reverts 39deaf85 to allow migration to isolate dirty
pages again. This increases how much compaction disrupts the LRU but that
is addressed later in the series.
Signed-off-by: Mel Gorman <mgorman@suse.de>
Reviewed-by: Andrea Arcangeli <aarcange@redhat.com>
Reviewed-by: Rik van Riel <riel@redhat.com>
Reviewed-by: Minchan Kim <minchan.kim@gmail.com>
Cc: Dave Jones <davej@redhat.com>
Cc: Jan Kara <jack@suse.cz>
Cc: Andy Isaacson <adi@hexapodia.org>
Cc: Nai Xia <nai.xia@gmail.com>
Cc: Johannes Weiner <jweiner@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 938929f14c upstream.
Stable note: Fixes https://bugzilla.novell.com/show_bug.cgi?id=726210 .
Large machines with 1TB or more of RAM take a long time to boot
without this patch and may spew out soft lockup warnings.
When min_free_kbytes is updated, some pageblocks are marked
MIGRATE_RESERVE. Ordinarily, this work is unnoticable as it happens early
in boot but on large machines with 1TB of memory, this has been reported
to delay boot times, probably due to the NUMA distances involved.
The bulk of the work is due to calling calling pageblock_is_reserved() an
unnecessary amount of times and accessing far more struct page metadata
than is necessary. This patch significantly reduces the amount of work
done by setup_zone_migrate_reserve() improving boot times on 1TB machines.
[akpm@linux-foundation.org: coding-style fixes]
Signed-off-by: Mel Gorman <mgorman@suse.de>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b2e6ad7dfe upstream.
Add support for the 15'' MacBook Pro Retina. The keyboard is
the same as recent models.
The patch needs to be synchronized with the bcm5974 patch for
the trackpad - as usual.
Patch originally written by clipcarl (forums.opensuse.org).
[rydberg@euromail.se: Amended mouse ignore lines]
Signed-off-by: Ryan Bourgeois <bluedragonx@gmail.com>
Signed-off-by: Henrik Rydberg <rydberg@euromail.se>
Acked-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit e76b8ee25e upstream.
I couldn't find the vendor ID in any of the online databases, but this
mat has a Pump It Up logo on the top side of the controller compartment,
and a disclaimer stating that Andamiro will not be liable on the bottom.
Signed-off-by: Yuri Khan <yurivkhan@gmail.com>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3dde22a98e upstream.
Add support for the 15'' MacBook Pro Retina model (MacBookPro10,1).
Patch originally written by clipcarl (forums.opensuse.org).
Signed-off-by: Henrik Rydberg <rydberg@euromail.se>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a64d49c3dd upstream.
It was recently reported that moving a bonding device between network
namespaces causes warnings from /proc. It turns out after the move we
were trying to add and to remove the /proc/net/bonding entries from the
wrong network namespace.
Move the bonding /proc registration code into the NETDEV_REGISTER and
NETDEV_UNREGISTER events where the proc registration and unregistration
will always happen at the right time.
Signed-off-by: "Eric W. Biederman" <ebiederm@xmission.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 96ca7ffe74 upstream.
The bonding debugfs support has been broken in the presence of network
namespaces since it has been added. The debugfs support does not handle
multiple bonding devices with the same name in different network
namespaces.
I haven't had any bug reports, and I'm not interested in getting any.
Disable the debugfs support when network namespaces are enabled.
Signed-off-by: "Eric W. Biederman" <ebiederm@xmission.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8e83989106 upstream.
It was observed that during multiple reboots nfs hangs. The status of
receive descriptors shows that all the descriptors were in control of
CPU, and none were assigned to DMA.
Also the DMA status register confirmed that the Rx buffer is
unavailable.
This patch adds the fix for the same by adding the memory barriers to
ascertain that the all instructions before enabling the Rx or Tx DMA are
completed which involves the proper setting of the ownership bit in DMA
descriptors.
Signed-off-by: Deepak Sikri <deepak.sikri@st.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6de0298ec9 upstream.
This adds support for the iPad to the ipheth driver.
(product id = 0x129a)
Signed-off-by: Davide Gerhard <rainbow@irh.it>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dbe9a2edd1 upstream.
The comparison between the system sleep state being entered
and the lowest system sleep state the given device may wake up
from in acpi_pm_device_sleep_state() is reversed, because the
specification (ACPI 5.0) says that for wakeup to work:
"The sleeping state being entered must be less than or equal to the
power state declared in element 1 of the _PRW object."
In other words, the state returned by _PRW is the deepest
(lowest-power) system sleep state the device is capable of waking up
the system from.
Moreover, acpi_pm_device_sleep_state() also should check if the
wakeup capability is supported through ACPI, because in principle it
may be done via native PCIe PME, for example, in which case _SxW
should not be evaluated.
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9fe79d7600 upstream.
If the first attempt at opening the lower file read/write fails,
eCryptfs will retry using a privileged kthread. However, the privileged
retry should not happen if the lower file's inode is read-only because a
read/write open will still be unsuccessful.
The check for determining if the open should be retried was intended to
be based on the access mode of the lower file's open flags being
O_RDONLY, but the check was incorrectly performed. This would cause the
open to be retried by the privileged kthread, resulting in a second
failed open of the lower file. This patch corrects the check to
determine if the open request should be handled by the privileged
kthread.
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Dan Carpenter <dan.carpenter@oracle.com>
Acked-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8dc6780587 upstream.
File operations on /dev/ecryptfs would BUG() when the operations were
performed by processes other than the process that originally opened the
file. This could happen with open files inherited after fork() or file
descriptors passed through IPC mechanisms. Rather than calling BUG(), an
error code can be safely returned in most situations.
In ecryptfs_miscdev_release(), eCryptfs still needs to handle the
release even if the last file reference is being held by a process that
didn't originally open the file. ecryptfs_find_daemon_by_euid() will not
be successful, so a pointer to the daemon is stored in the file's
private_data. The private_data pointer is initialized when the miscdev
file is opened and only used when the file is released.
https://launchpad.net/bugs/994247
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Sasha Levin <levinsasha928@gmail.com>
Tested-by: Sasha Levin <levinsasha928@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b939c2acf1 upstream.
commit f6b54f083c upstream.
This is the 2nd part of fix for kernel bugzilla 40002:
"IRQ 0 assigned to VGA"
https://bugzilla.kernel.org/show_bug.cgi?id=40002
The root cause is the buggy FW, whose ACPI tables assign the GSI 16
to 2 irqs 0 and 16(VGA), and the VGA is the right owner of GSI 16.
So add a quirk to ignore the irq0 overriding GSI 16 for the
FUJITSU SIEMENS AMILO PRO V2030 platform will solve this issue.
Reported-and-tested-by: Szymon Kowalczyk <fazerxlo@o2.pl>
Signed-off-by: Feng Tang <feng.tang@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5752cdb805 upstream.
commit 7f68b4c2e1 upstream.
Current WARN msg is only for the ati_ixp4x0 board, while this function
is used by mulitple platforms. So this one board specific warning
is not appropriate any more.
Signed-off-by: Feng Tang <feng.tang@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ae10ccdc30 upstream.
Currently when acpi_skip_timer_override is set, it only cover the
(source_irq == 0 && global_irq == 2) cases. While there is also
platform which need use this option and its global_irq is not 2.
This patch will extend acpi_skip_timer_override to cover all
timer overriding cases as long as the source irq is 0.
This is the first part of a fix to kernel bug bugzilla 40002:
"IRQ 0 assigned to VGA"
https://bugzilla.kernel.org/show_bug.cgi?id=40002
Reported-and-tested-by: Szymon Kowalczyk <fazerxlo@o2.pl>
Signed-off-by: Feng Tang <feng.tang@intel.com>
Signed-off-by: Len Brown <len.brown@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 62b1a8ab9b upstream.
Orphaning skb in dev_hard_start_xmit() makes bonding behavior
unfriendly for applications sending big UDP bursts : Once packets
pass the bonding device and come to real device, they might hit a full
qdisc and be dropped. Without orphaning, the sender is automatically
throttled because sk->sk_wmemalloc reaches sk->sk_sndbuf (assuming
sk_sndbuf is not too big)
We could try to defer the orphaning adding another test in
dev_hard_start_xmit(), but all this seems of little gain,
now that BQL tends to make packets more likely to be parked
in Qdisc queues instead of NIC TX ring, in cases where performance
matters.
Reverts commits :
fc6055a5ba net: Introduce skb_orphan_try()
87fd308cfc net: skb_tx_hash() fix relative to skb_orphan_try()
and removes SKBTX_DRV_NEEDS_SK_REF flag
Reported-and-bisected-by: Jean-Michel Hautbois <jhautbois@gmail.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Tested-by: Oliver Hartkopp <socketcan@hartkopp.net>
Acked-by: Oliver Hartkopp <socketcan@hartkopp.net>
Signed-off-by: David S. Miller <davem@davemloft.net>
[bwh: Backported to 3.2:
- Adjust context
- SKBTX_WIFI_STATUS is not defined]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bc14786a10 upstream.
There is a off by one error in the minimal number of BD in
bnx2x_start_xmit() and bnx2x_tx_int() before stopping/resuming tx queue.
A full size GSO packet, with data included in skb->head really needs
(MAX_SKB_FRAGS + 4) BDs, because of bnx2x_tx_split()
This error triggers if BQL is disabled and heavy TCP transmit traffic
occurs.
bnx2x_tx_split() definitely can be called, remove a wrong comment.
Reported-by: Tomas Hruby <thruby@google.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Eilon Greenstein <eilong@broadcom.com>
Cc: Yaniv Rosner <yanivr@broadcom.com>
Cc: Merav Sicron <meravs@broadcom.com>
Cc: Tom Herbert <therbert@google.com>
Cc: Robert Evans <evansr@google.com>
Cc: Willem de Bruijn <willemb@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d6cb3e4138 upstream.
bnx2x driver incorrectly sets ip_summed to CHECKSUM_UNNECESSARY on
encapsulated segments. TCP stack happily accepts frames with bad
checksums, if they are inside a GRE or IPIP encapsulation.
Our understanding is that if no IP or L4 csum validation was done by the
hardware, we should leave ip_summed as is (CHECKSUM_NONE), since
hardware doesn't provide CHECKSUM_COMPLETE support in its cqe.
Then, if IP/L4 checksumming was done by the hardware, set
CHECKSUM_UNNECESSARY if no error was flagged.
Patch based on findings and analysis from Robert Evans
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Eilon Greenstein <eilong@broadcom.com>
Cc: Yaniv Rosner <yanivr@broadcom.com>
Cc: Merav Sicron <meravs@broadcom.com>
Cc: Tom Herbert <therbert@google.com>
Cc: Robert Evans <evansr@google.com>
Cc: Willem de Bruijn <willemb@google.com>
Acked-by: Eilon Greenstein <eilong@broadcom.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
[bwh: Backported to 3.2: adjust context, indentation]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ad1be8d345 upstream.
when register_netdev fails, the init'ed NAPIs by netif_napi_add must be
deleted with netif_napi_del, and also when driver unloads, it should
delete the NAPI before unregistering netdevice using unregister_netdev.
Signed-off-by: Devendra Naga <devendra.aaru@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d550dda192 upstream.
This is a tiny, but important, patch to vhost.
Vhost's worker thread only called schedule() when it had no work to do, and
it wanted to go to sleep. But if there's always work to do, e.g., the guest
is running a network-intensive program like netperf with small message sizes,
schedule() was *never* called. This had several negative implications (on
non-preemptive kernels):
1. Passing time was not properly accounted to the "vhost" process (ps and
top would wrongly show it using zero CPU time).
2. Sometimes error messages about RCU timeouts would be printed, if the
core running the vhost thread didn't schedule() for a very long time.
3. Worst of all, a vhost thread would "hog" the core. If several vhost
threads need to share the same core, typically one would get most of the
CPU time (and its associated guest most of the performance), while the
others hardly get any work done.
The trivial solution is to add
if (need_resched())
schedule();
After doing every piece of work. This will not do the heavy schedule() all
the time, just when the timer interrupt decided a reschedule is warranted
(so need_resched returns true).
Thanks to Abel Gordon for this patch.
Signed-off-by: Nadav Har'El <nyh@il.ibm.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9f5072d4f6 upstream.
Commit d57af9b (taskstats: use real microsecond granularity for CPU times)
renamed msecs_to_cputime to usecs_to_cputime, but failed to update all
numbers on the way. This causes nonsensical cpu idle/iowait values to be
displayed in /proc/stat (the only user of usecs_to_cputime so far).
This also renames __cputime_msec_factor to __cputime_usec_factor, adapting
its value and using it directly in cputime_to_usecs instead of doing two
multiplications.
Signed-off-by: Andreas Schwab <schwab@linux-m68k.org>
Acked-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5baefd6d84 upstream.
The update of the hrtimer base offsets on all cpus cannot be made
atomically from the timekeeper.lock held and interrupt disabled region
as smp function calls are not allowed there.
clock_was_set(), which enforces the update on all cpus, is called
either from preemptible process context in case of do_settimeofday()
or from the softirq context when the offset modification happened in
the timer interrupt itself due to a leap second.
In both cases there is a race window for an hrtimer interrupt between
dropping timekeeper lock, enabling interrupts and clock_was_set()
issuing the updates. Any interrupt which arrives in that window will
see the new time but operate on stale offsets.
So we need to make sure that an hrtimer interrupt always sees a
consistent state of time and offsets.
ktime_get_update_offsets() allows us to get the current monotonic time
and update the per cpu hrtimer base offsets from hrtimer_interrupt()
to capture a consistent state of monotonic time and the offsets. The
function replaces the existing ktime_get() calls in hrtimer_interrupt().
The overhead of the new function vs. ktime_get() is minimal as it just
adds two store operations.
This ensures that any changes to realtime or boottime offsets are
noticed and stored into the per-cpu hrtimer base structures, prior to
any hrtimer expiration and guarantees that timers are not expired early.
Signed-off-by: John Stultz <johnstul@us.ibm.com>
Reviewed-by: Ingo Molnar <mingo@kernel.org>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Acked-by: Prarit Bhargava <prarit@redhat.com>
Link: http://lkml.kernel.org/r/1341960205-56738-8-git-send-email-johnstul@us.ibm.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
This is a backport of 4873fa070a
The timekeeping code misses an update of the hrtimer subsystem after a
leap second happened. Due to that timers based on CLOCK_REALTIME are
either expiring a second early or late depending on whether a leap
second has been inserted or deleted until an operation is initiated
which causes that update. Unless the update happens by some other
means this discrepancy between the timekeeping and the hrtimer data
stays forever and timers are expired either early or late.
The reported immediate workaround - $ data -s "`date`" - is causing a
call to clock_was_set() which updates the hrtimer data structures.
See: http://www.sheeri.com/content/mysql-and-leap-second-high-cpu-and-fix
Add the missing clock_was_set() call to update_wall_time() in case of
a leap second event. The actual update is deferred to softirq context
as the necessary smp function call cannot be invoked from hard
interrupt context.
Signed-off-by: John Stultz <johnstul@us.ibm.com>
Reported-by: Jan Engelhardt <jengelh@inai.de>
Reviewed-by: Ingo Molnar <mingo@kernel.org>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Acked-by: Prarit Bhargava <prarit@redhat.com>
Link: http://lkml.kernel.org/r/1341960205-56738-3-git-send-email-johnstul@us.ibm.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Cc: Prarit Bhargava <prarit@redhat.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Linux Kernel <linux-kernel@vger.kernel.org>
Signed-off-by: John Stultz <johnstul@us.ibm.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f55a6faa38 upstream.
clock_was_set() cannot be called from hard interrupt context because
it calls on_each_cpu().
For fixing the widely reported leap seconds issue it is necessary to
call it from hard interrupt context, i.e. the timer tick code, which
does the timekeeping updates.
Provide a new function which denotes it in the hrtimer cpu base
structure of the cpu on which it is called and raise the hrtimer
softirq. We then execute the clock_was_set() notificiation from
softirq context in run_hrtimer_softirq(). The hrtimer softirq is
rarely used, so polling the flag there is not a performance issue.
[ tglx: Made it depend on CONFIG_HIGH_RES_TIMERS. We really should get
rid of all this ifdeffery ASAP ]
Signed-off-by: John Stultz <johnstul@us.ibm.com>
Reported-by: Jan Engelhardt <jengelh@inai.de>
Reviewed-by: Ingo Molnar <mingo@kernel.org>
Acked-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Acked-by: Prarit Bhargava <prarit@redhat.com>
Link: http://lkml.kernel.org/r/1341960205-56738-2-git-send-email-johnstul@us.ibm.com
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dd48d708ff upstream.
When repeating a UTC time value during a leap second (when the UTC
time should be 23:59:60), the TAI timescale should not stop. The kernel
NTP code increments the TAI offset one second too late. This patch fixes
the issue by incrementing the offset during the leap second itself.
Signed-off-by: Richard Cochran <richardcochran@gmail.com>
Signed-off-by: John Stultz <john.stultz@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
This is a backport of 6b43ae8a61
This should have been backported when it was commited, but I
mistook the problem as requiring the ntp_lock changes
that landed in 3.4 in order for it to occur.
Unfortunately the same issue can happen (with only one cpu)
as follows:
do_adjtimex()
write_seqlock_irq(&xtime_lock);
process_adjtimex_modes()
process_adj_status()
ntp_start_leap_timer()
hrtimer_start()
hrtimer_reprogram()
tick_program_event()
clockevents_program_event()
ktime_get()
seq = req_seqbegin(xtime_lock); [DEADLOCK]
This deadlock will no always occur, as it requires the
leap_timer to force a hrtimer_reprogram which only happens
if its set and there's no sooner timer to expire.
NOTE: This patch, being faithful to the original commit,
introduces a bug (we don't update wall_to_monotonic),
which will be resovled by backporting a following fix.
Original commit message below:
Since commit 7dffa3c673 the ntp
subsystem has used an hrtimer for triggering the leapsecond
adjustment. However, this can cause a potential livelock.
Thomas diagnosed this as the following pattern:
CPU 0 CPU 1
do_adjtimex()
spin_lock_irq(&ntp_lock);
process_adjtimex_modes(); timer_interrupt()
process_adj_status(); do_timer()
ntp_start_leap_timer(); write_lock(&xtime_lock);
hrtimer_start(); update_wall_time();
hrtimer_reprogram(); ntp_tick_length()
tick_program_event() spin_lock(&ntp_lock);
clockevents_program_event()
ktime_get()
seq = req_seqbegin(xtime_lock);
This patch tries to avoid the problem by reverting back to not using
an hrtimer to inject leapseconds, and instead we handle the leapsecond
processing in the second_overflow() function.
The downside to this change is that on systems that support highres
timers, the leap second processing will occur on a HZ tick boundary,
(ie: ~1-10ms, depending on HZ) after the leap second instead of
possibly sooner (~34us in my tests w/ x86_64 lapic).
This patch applies on top of tip/timers/core.
CC: Sasha Levin <levinsasha928@gmail.com>
CC: Thomas Gleixner <tglx@linutronix.de>
Reported-by: Sasha Levin <levinsasha928@gmail.com>
Diagnoised-by: Thomas Gleixner <tglx@linutronix.de>
Tested-by: Sasha Levin <levinsasha928@gmail.com>
Cc: Prarit Bhargava <prarit@redhat.com>
Cc: Thomas Gleixner <tglx@linutronix.de>
Cc: Linux Kernel <linux-kernel@vger.kernel.org>
Signed-off-by: John Stultz <john.stultz@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7c8d3a42fe upstream.
We can't guarantee that REQ_DISCARD on dm-mirror zeroes the data even if
the underlying disks support zero on discard. So this patch sets
ti->discard_zeroes_data_unsupported.
For example, if the mirror is in the process of resynchronizing, it may
happen that kcopyd reads a piece of data, then discard is sent on the
same area and then kcopyd writes the piece of data to another leg.
Consequently, the data is not zeroed.
The flag was made available by commit 983c7db347
(dm crypt: always disable discard_zeroes_data).
Signed-off-by: Mikulas Patocka <mpatocka@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 751f188dd5 upstream.
This patch fixes a crash when a discard request is sent during mirror
recovery.
Firstly, some background. Generally, the following sequence happens during
mirror synchronization:
- function do_recovery is called
- do_recovery calls dm_rh_recovery_prepare
- dm_rh_recovery_prepare uses a semaphore to limit the number
simultaneously recovered regions (by default the semaphore value is 1,
so only one region at a time is recovered)
- dm_rh_recovery_prepare calls __rh_recovery_prepare,
__rh_recovery_prepare asks the log driver for the next region to
recover. Then, it sets the region state to DM_RH_RECOVERING. If there
are no pending I/Os on this region, the region is added to
quiesced_regions list. If there are pending I/Os, the region is not
added to any list. It is added to the quiesced_regions list later (by
dm_rh_dec function) when all I/Os finish.
- when the region is on quiesced_regions list, there are no I/Os in
flight on this region. The region is popped from the list in
dm_rh_recovery_start function. Then, a kcopyd job is started in the
recover function.
- when the kcopyd job finishes, recovery_complete is called. It calls
dm_rh_recovery_end. dm_rh_recovery_end adds the region to
recovered_regions or failed_recovered_regions list (depending on
whether the copy operation was successful or not).
The above mechanism assumes that if the region is in DM_RH_RECOVERING
state, no new I/Os are started on this region. When I/O is started,
dm_rh_inc_pending is called, which increases reg->pending count. When
I/O is finished, dm_rh_dec is called. It decreases reg->pending count.
If the count is zero and the region was in DM_RH_RECOVERING state,
dm_rh_dec adds it to the quiesced_regions list.
Consequently, if we call dm_rh_inc_pending/dm_rh_dec while the region is
in DM_RH_RECOVERING state, it could be added to quiesced_regions list
multiple times or it could be added to this list when kcopyd is copying
data (it is assumed that the region is not on any list while kcopyd does
its jobs). This results in memory corruption and crash.
There already exist bypasses for REQ_FLUSH requests: REQ_FLUSH requests
do not belong to any region, so they are always added to the sync list
in do_writes. dm_rh_inc_pending does not increase count for REQ_FLUSH
requests. In mirror_end_io, dm_rh_dec is never called for REQ_FLUSH
requests. These bypasses avoid the crash possibility described above.
These bypasses were improperly implemented for REQ_DISCARD when
the mirror target gained discard support in commit
5fc2ffeabb (dm raid1: support discard).
In do_writes, REQ_DISCARD requests is always added to the sync queue and
immediately dispatched (even if the region is in DM_RH_RECOVERING). However,
dm_rh_inc and dm_rh_dec is called for REQ_DISCARD resusts. So it violates the
rule that no I/Os are started on DM_RH_RECOVERING regions, and causes the list
corruption described above.
This patch changes it so that REQ_DISCARD requests follow the same path
as REQ_FLUSH. This avoids the crash.
Reference: https://bugzilla.redhat.com/837607
Signed-off-by: Mikulas Patocka <mpatocka@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c999ff6802 upstream.
It is very common for the end of the file to be unaligned on
stripe size. But since we know it's beyond file's end then
the XOR should be preformed with all zeros.
Old code used to just read zeros out of the OSD devices, which is a great
waist. But what scares me more about this situation is that, we now have
pages attached to the file's mapping that are beyond i_size. I don't
like the kind of bugs this calls for.
Fix both birds, by returning a global zero_page, if offset is beyond
i_size.
TODO:
Change the API to ->__r4w_get_page() so a NULL can be
returned without being considered as error, since XOR API
treats NULL entries as zero_pages.
[Bug since 3.2. Should apply the same way to all Kernels since]
Signed-off-by: Boaz Harrosh <bharrosh@panasas.com>
[bwh: Backported to 3.2: adjust for lack of wdata->header]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 62b62ad873 upstream.
Do to OOM situations the ore might fail to allocate all resources
needed for IO of the full request. If some progress was possible
it would proceed with a partial/short request, for the sake of
forward progress.
Since this crashes NFS-core and exofs is just fine without it just
remove this contraption, and fail.
TODO:
Support real forward progress with some reserved allocations
of resources, such as mem pools and/or bio_sets
[Bug since 3.2 Kernel]
CC: Benny Halevy <bhalevy@tonian.com>
Signed-off-by: Boaz Harrosh <bharrosh@panasas.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9ff19309a9 upstream.
In RAID_5/6 We used to not permit an IO that it's end
byte is not stripe_size aligned and spans more than one stripe.
.i.e the caller must check if after submission the actual
transferred bytes is shorter, and would need to resubmit
a new IO with the remainder.
Exofs supports this, and NFS was supposed to support this
as well with it's short write mechanism. But late testing has
exposed a CRASH when this is used with none-RPC layout-drivers.
The change at NFS is deep and risky, in it's place the fix
at ORE to lift the limitation is actually clean and simple.
So here it is below.
The principal here is that in the case of unaligned IO on
both ends, beginning and end, we will send two read requests
one like old code, before the calculation of the first stripe,
and also a new site, before the calculation of the last stripe.
If any "boundary" is aligned or the complete IO is within a single
stripe. we do a single read like before.
The code is clean and simple by splitting the old _read_4_write
into 3 even parts:
1._read_4_write_first_stripe
2. _read_4_write_last_stripe
3. _read_4_write_execute
And calling 1+3 at the same place as before. 2+3 before last
stripe, and in the case of all in a single stripe then 1+2+3
is preformed additively.
Why did I not think of it before. Well I had a strike of
genius because I have stared at this code for 2 years, and did
not find this simple solution, til today. Not that I did not try.
This solution is much better for NFS than the previous supposedly
solution because the short write was dealt with out-of-band after
IO_done, which would cause for a seeky IO pattern where as in here
we execute in order. At both solutions we do 2 separate reads, only
here we do it within a single IO request. (And actually combine two
writes into a single submission)
NFS/exofs code need not change since the ORE API communicates the new
shorter length on return, what will happen is that this case would not
occur anymore.
hurray!!
[Stable this is an NFS bug since 3.2 Kernel should apply cleanly]
Signed-off-by: Boaz Harrosh <bharrosh@panasas.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c6727932cf upstream.
UBIFS has a feature called "empty space fix-up" which is a quirk to work-around
limitations of dumb flasher programs. Namely, of those flashers that are unable
to skip NAND pages full of 0xFFs while flashing, resulting in empty space at
the end of half-filled eraseblocks to be unusable for UBIFS. This feature is
relatively new (introduced in v3.0).
The fix-up routine (fixup_free_space()) is executed only once at the very first
mount if the superblock has the 'space_fixup' flag set (can be done with -F
option of mkfs.ubifs). It basically reads all the UBIFS data and metadata and
writes it back to the same LEB. The routine assumes the image is pristine and
does not have anything in the journal.
There was a bug in 'fixup_free_space()' where it fixed up the log incorrectly.
All but one LEB of the log of a pristine file-system are empty. And one
contains just a commit start node. And 'fixup_free_space()' just unmapped this
LEB, which resulted in wiping the commit start node. As a result, some users
were unable to mount the file-system next time with the following symptom:
UBIFS error (pid 1): replay_log_leb: first log node at LEB 3:0 is not CS node
UBIFS error (pid 1): replay_log_leb: log error detected while replaying the log at LEB 3:0
The root-cause of this bug was that 'fixup_free_space()' wrongly assumed
that the beginning of empty space in the log head (c->lhead_offs) was known
on mount. However, it is not the case - it was always 0. UBIFS does not store
in it the master node and finds out by scanning the log on every mount.
The fix is simple - just pass commit start node size instead of 0 to
'fixup_leb()'.
Signed-off-by: Artem Bityutskiy <Artem.Bityutskiy@linux.intel.com>
Reported-by: Iwo Mergler <Iwo.Mergler@netcommwireless.com>
Tested-by: Iwo Mergler <Iwo.Mergler@netcommwireless.com>
Reported-by: James Nute <newten82@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 58e94ae184 upstream.
commit 4367af5561
md/raid1: clear bad-block record when write succeeds.
Added a 'reschedule_retry' call possibility at the end of
end_sync_write, but didn't add matching code at the end of
sync_request_write. So if the writes complete very quickly, or
scheduling makes it seem that way, then we can miss rescheduling
the request and the resync could hang.
Also commit 73d5c38a95
md: avoid races when stopping resync.
Fix a race condition in this same code in end_sync_write but didn't
make the change in sync_request_write.
This patch updates sync_request_write to fix both of those.
Patch is suitable for 3.1 and later kernels.
Reported-by: Alexander Lyakas <alex.bolshoy@gmail.com>
Original-version-by: Alexander Lyakas <alex.bolshoy@gmail.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit a05b7ea03d upstream.
md will refuse to stop an array if any other fd (or mounted fs) is
using it.
When any fs is unmounted of when the last open fd is closed all
pending IO will be flushed (e.g. sync_blockdev call in __blkdev_put)
so there will be no pending IO to worry about when the array is
stopped.
However in order to send the STOP_ARRAY ioctl to stop the array one
must first get and open fd on the block device.
If some fd is being used to write to the block device and it is closed
after mdadm open the block device, but before mdadm issues the
STOP_ARRAY ioctl, then there will be no last-close on the md device so
__blkdev_put will not call sync_blockdev.
If this happens, then IO can still be in-flight while md tears down
the array and bad things can happen (use-after-free and subsequent
havoc).
So in the case where do_md_stop is being called from an open file
descriptor, call sync_block after taking the mutex to ensure there
will be no new openers.
This is needed when setting a read-write device to read-only too.
Reported-by: majianpeng <majianpeng@gmail.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1c7e7f6c07 upstream.
Offlining memory may block forever, waiting for kswapd() to wake up
because kswapd() does not check the event kthread->should_stop before
sleeping.
The proper pattern, from Documentation/memory-barriers.txt, is:
--- waker ---
event_indicated = 1;
wake_up_process(event_daemon);
--- sleeper ---
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (event_indicated)
break;
schedule();
}
set_current_state() may be wrapped by:
prepare_to_wait();
In the kswapd() case, event_indicated is kthread->should_stop.
=== offlining memory (waker) ===
kswapd_stop()
kthread_stop()
kthread->should_stop = 1
wake_up_process()
wait_for_completion()
=== kswapd_try_to_sleep (sleeper) ===
kswapd_try_to_sleep()
prepare_to_wait()
.
.
schedule()
.
.
finish_wait()
The schedule() needs to be protected by a test of kthread->should_stop,
which is wrapped by kthread_should_stop().
Reproducer:
Do heavy file I/O in background.
Do a memory offline/online in a tight loop
Signed-off-by: Aaditya Kumar <aaditya.kumar@ap.sony.com>
Acked-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Reviewed-by: Minchan Kim <minchan@kernel.org>
Acked-by: Mel Gorman <mel@csn.ul.ie>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit cd60042cc1 upstream.
When we get back a FIND_FIRST/NEXT result, we have some info about the
dentry that we use to instantiate a new inode. We were ignoring and
discarding that info when we had an existing dentry in the cache.
Fix this by updating the inode in place when we find an existing dentry
and the uniqueid is the same.
Reported-and-Tested-by: Andrew Bartlett <abartlet@samba.org>
Reported-by: Bill Robertson <bill_robertson@debortoli.com.au>
Reported-by: Dion Edwards <dion_edwards@debortoli.com.au>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Steve French <smfrench@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3ae629d98b upstream.
We currently rely on being able to kmap all of the pages in an async
read or write request. If you're on a machine that has CONFIG_HIGHMEM
set then that kmap space is limited, sometimes to as low as 512 slots.
With 512 slots, we can only support up to a 2M r/wsize, and that's
assuming that we can get our greedy little hands on all of them. There
are other users however, so it's possible we'll end up stuck with a
size that large.
Since we can't handle a rsize or wsize larger than that currently, cap
those options at the number of kmap slots we have. We could consider
capping it even lower, but we currently default to a max of 1M. Might as
well allow those luddites on 32 bit arches enough rope to hang
themselves.
A more robust fix would be to teach the send and receive routines how
to contend with an array of pages so we don't need to marshal up a kvec
array at all. That's a fairly significant overhaul though, so we'll need
this limit in place until that's ready.
Reported-by: Jian Li <jiali@redhat.com>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Steve French <smfrench@gmail.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1765fe5edc upstream.
When NUMBER OF LOGICAL BLOCKS is 0, WRITE SAME is supposed to write
all the blocks from the specified LBA through the end of the device.
However, dev->transport->get_blocks(dev) (perhaps confusingly) returns
the last valid LBA rather than the number of blocks, so the correct
number of blocks to write starting with lba is
dev->transport->get_blocks(dev) - lba + 1
(nab: Backport roland's for-3.6 patch to for-3.5)
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d35212f3ca upstream.
- instead of (PTR_ERR(file) < 0) just use IS_ERR(file)
- return -EINVAL instead of EINVAL
- all other error returns in target_scsi3_emulate_pr_out() use
"goto out" -- get rid of the one remaining straight "return."
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 05d290d66b upstream.
If a parent and child process open the two ends of a fifo, and the
child immediately exits, the parent may receive a SIGCHLD before its
open() returns. In that case, we need to make sure that open() will
return successfully after the SIGCHLD handler returns, instead of
throwing EINTR or being restarted. Otherwise, the restarted open()
would incorrectly wait for a second partner on the other end.
The following test demonstrates the EINTR that was wrongly thrown from
the parent’s open(). Change .sa_flags = 0 to .sa_flags = SA_RESTART
to see a deadlock instead, in which the restarted open() waits for a
second reader that will never come. (On my systems, this happens
pretty reliably within about 5 to 500 iterations. Others report that
it manages to loop ~forever sometimes; YMMV.)
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define CHECK(x) do if ((x) == -1) {perror(#x); abort();} while(0)
void handler(int signum) {}
int main()
{
struct sigaction act = {.sa_handler = handler, .sa_flags = 0};
CHECK(sigaction(SIGCHLD, &act, NULL));
CHECK(mknod("fifo", S_IFIFO | S_IRWXU, 0));
for (;;) {
int fd;
pid_t pid;
putc('.', stderr);
CHECK(pid = fork());
if (pid == 0) {
CHECK(fd = open("fifo", O_RDONLY));
_exit(0);
}
CHECK(fd = open("fifo", O_WRONLY));
CHECK(close(fd));
CHECK(waitpid(pid, NULL, 0));
}
}
This is what I suspect was causing the Git test suite to fail in
t9010-svn-fe.sh:
http://bugs.debian.org/678852
Signed-off-by: Anders Kaseorg <andersk@mit.edu>
Reviewed-by: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3cc5d2a6b9 upstream.
This patch fixes a crash seen when large reads have their exchange
aborted by either timing out or being reset. Because the exchange
abort results in the seq pointer being set to NULL, because the
sequence is no longer valid, it must not be dereferenced. This
patch changes the function ft_get_task_tag to return ~0 if it is
unable to get the tag for this reason. Because the get_task_tag
interface provides no means of returning an error, this seems
like the best way to fix this issue at the moment.
Signed-off-by: Mark Rustad <mark.d.rustad@intel.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d0efa8f23a upstream.
SYNCH bit and IV bit of RXCW register are sticky. Before examining these bits,
RXCW should be read twice to filter out one-time false events and have correct
values for these bits. Incorrect values of these bits in link check logic can
cause weird link stability issues if auto-negotiation fails.
Reported-by: Dean Nelson <dnelson@redhat.com>
Signed-off-by: Tushar Dave <tushar.n.dave@intel.com>
Reviewed-by: Bruce Allan <bruce.w.allan@intel.com>
Tested-by: Jeff Pieper <jeffrey.e.pieper@intel.com>
Signed-off-by: Jeff Kirsher <jeffrey.t.kirsher@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b48d966526 upstream.
When we remove a key, we put a key index which was supposed
to tell the fw that we are actually removing the key. But
instead the fw took that index as a valid index and messed
up the SRAM of the device.
This memory corruption on the device mangled the data of
the SCD. The impact on the user is that SCD queue 2 got
stuck after having removed keys.
Reported-by: Paul Bolle <pebolle@tiscali.nl>
Signed-off-by: Emmanuel Grumbach <emmanuel.grumbach@intel.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust filename, context and variable name]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c2ca7d92ed upstream.
This is iwlegacy version of:
commit 342bbf3fee
Author: Johannes Berg <johannes.berg@intel.com>
Date: Sun Mar 4 08:50:46 2012 -0800
iwlwifi: always monitor for stuck queues
If we only monitor while associated, the following
can happen:
- we're associated, and the queue stuck check
runs, setting the queue "touch" time to X
- we disassociate, stopping the monitoring,
which leaves the time set to X
- almost 2s later, we associate, and enqueue
a frame
- before the frame is transmitted, we monitor
for stuck queues, and find the time set to
X, although it is now later than X + 2000ms,
so we decide that the queue is stuck and
erroneously restart the device
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: adjust filename, function and variable names]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit efd821182c upstream.
On rt2x00_dmastart() we increase index specified by Q_INDEX and on
rt2x00_dmadone() we increase index specified by Q_INDEX_DONE. So entries
between Q_INDEX_DONE and Q_INDEX are those we currently process in the
hardware. Entries between Q_INDEX and Q_INDEX_DONE are those we can
submit to the hardware.
According to that fix rt2x00usb_kick_queue(), as we need to submit RX
entries that are not processed by the hardware. It worked before only
for empty queue, otherwise was broken.
Note that for TX queues indexes ordering are ok. We need to kick entries
that have filled skb, but was not submitted to the hardware, i.e.
started from Q_INDEX_DONE and have ENTRY_DATA_PENDING bit set.
From practical standpoint this fixes RX queue stall, usually reproducible
in AP mode, like for example reported here:
https://bugzilla.redhat.com/show_bug.cgi?id=828824
Reported-and-tested-by: Franco Miceli <fmiceli@plan.ceibal.edu.uy>
Reported-and-tested-by: Tom Horsley <horsley1953@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b94e52f626 upstream.
some people report atl1c could cause system hang with following
kernel trace info:
---------------------------------------
WARNING: at.../net/sched/sch_generic.c:258 dev_watchdog+0x1db/0x1d0()
...
NETDEV WATCHDOG: eth0 (atl1c): transmit queue 0 timed out
...
---------------------------------------
This is caused by netif_stop_queue calling when cable Link is down.
So remove netif_stop_queue, because link_watch will take it over.
Signed-off-by: xiong <xiong@qca.qualcomm.com>
Signed-off-by: Cloud Ren <cjren@qca.qualcomm.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 88ca518b0b upstream.
intel_ips driver spews the warning message
"ME failed to update for more than 1s, likely hung"
at each second endlessly on HP ProBook laptops with IronLake.
As this has never worked, better to blacklist the driver for now.
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Matthew Garrett <mjg@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f8cdddb8d6 upstream.
Don't validate interface combinations on a stopped
interface. Otherwise we might end up being able to
create a new interface with a certain type, but
won't be able to change an existing interface
into that type.
This also skips some other functions when
interface is stopped and changing interface type.
Signed-off-by: Michal Kazior <michal.kazior@tieto.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5a21d489fd upstream.
1. Do not allocate memory for buffers from emergency pools, unless
absolutely required. Do not warn about and do not retry non-essential
failed allocations.
2. Do not check the amount of free pages left on every single page
write, but wait until one map is completely populated and then check.
3. Set maximum number of pages for read buffering consistently, instead
of inadvertently depending on the size of the sector type.
4. Fix copyright line, which I missed when I submitted the hibernation
threading patch.
5. Dispense with bit shifting arithmetic to improve readability.
6. Really recalculate the number of pages required to be free after all
allocations have been done.
7. Fix calculation of pages required for read buffering. Only count in
pages that do not belong to high memory.
Signed-off-by: Bojan Smojver <bojan@rexursive.com>
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dbd4fcaf8d upstream.
The netlink commands and attributes, along with the socket structure
definitions need to be exported.
Signed-off-by: Samuel Ortiz <sameo@linux.intel.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8d657eb3b4 upstream.
This can be trivially triggered from userspace by passing in something unexpected.
kernel BUG at fs/locks.c:1468!
invalid opcode: 0000 [#1] SMP
RIP: 0010:generic_setlease+0xc2/0x100
Call Trace:
__vfs_setlease+0x35/0x40
fcntl_setlease+0x76/0x150
sys_fcntl+0x1c6/0x810
system_call_fastpath+0x1a/0x1f
Signed-off-by: Dave Jones <davej@redhat.com>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 91f68c89d8 upstream.
Commit 080399aaaf ("block: don't mark buffers beyond end of disk as
mapped") exposed a bug in __getblk_slow that causes mount to hang as it
loops infinitely waiting for a buffer that lies beyond the end of the
disk to become uptodate.
The problem was initially reported by Torsten Hilbrich here:
https://lkml.org/lkml/2012/6/18/54
and also reported independently here:
http://www.sysresccd.org/forums/viewtopic.php?f=13&t=4511
and then Richard W.M. Jones and Marcos Mello noted a few separate
bugzillas also associated with the same issue. This patch has been
confirmed to fix:
https://bugzilla.redhat.com/show_bug.cgi?id=835019
The main problem is here, in __getblk_slow:
for (;;) {
struct buffer_head * bh;
int ret;
bh = __find_get_block(bdev, block, size);
if (bh)
return bh;
ret = grow_buffers(bdev, block, size);
if (ret < 0)
return NULL;
if (ret == 0)
free_more_memory();
}
__find_get_block does not find the block, since it will not be marked as
mapped, and so grow_buffers is called to fill in the buffers for the
associated page. I believe the for (;;) loop is there primarily to
retry in the case of memory pressure keeping grow_buffers from
succeeding. However, we also continue to loop for other cases, like the
block lying beond the end of the disk. So, the fix I came up with is to
only loop when grow_buffers fails due to memory allocation issues
(return value of 0).
The attached patch was tested by myself, Torsten, and Rich, and was
found to resolve the problem in call cases.
Signed-off-by: Jeff Moyer <jmoyer@redhat.com>
Reported-and-Tested-by: Torsten Hilbrich <torsten.hilbrich@secunet.com>
Tested-by: Richard W.M. Jones <rjones@redhat.com>
Reviewed-by: Josh Boyer <jwboyer@redhat.com>
[ Jens is on vacation, taking this directly - Linus ]
--
Stable Notes: this patch requires backport to 3.0, 3.2 and 3.3.
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 41002f8dd5 upstream.
We were accidentally losing one bit in the configuration register on
device initialization. It was reported to freeze one specific system
right away. Properly preserve all bits we don't explicitly want to
change in order to prevent that.
Reported-by: Stevie Trujillo <stevie.trujillo@gmail.com>
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c4686c71a9 upstream.
Commit d640113fe8 introduced a regression on SMP
systems where the processor core with ACPI id zero is disabled
(typically should be the case because of hyperthreading).
The regression got spread through stable kernels.
On 3.0.X it got introduced via 3.0.18.
Such platforms may be rare, but do exist.
Look out for a disabled processor with acpi_id 0 in dmesg:
ACPI: LAPIC (acpi_id[0x00] lapic_id[0x10] disabled)
This problem has been observed on a:
HP Proliant BL280c G6 blade
This patch restricts the introduced workaround to platforms
with nr_cpu_ids <= 1.
Signed-off-by: Thomas Renninger <trenn@suse.de>
Signed-off-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fea9f718b3 upstream.
There is a bug in the below scenario for !CONFIG_MMU:
1. create a new file
2. mmap the file and write to it
3. read the file can't get the correct value
Because
sys_read() -> generic_file_aio_read() -> simple_readpage() -> clear_page()
which causes the page to be zeroed.
Add SetPageUptodate() to ramfs_nommu_expand_for_mapping() so that
generic_file_aio_read() do not call simple_readpage().
Signed-off-by: Bob Liu <lliubbo@gmail.com>
Cc: Hugh Dickins <hughd@google.com>
Cc: David Howells <dhowells@redhat.com>
Cc: Geert Uytterhoeven <geert@linux-m68k.org>
Cc: Greg Ungerer <gerg@uclinux.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4bf2bba375 upstream.
If page migration cannot charge the temporary page to the memcg,
migrate_pages() will return -ENOMEM. This isn't considered in memory
compaction however, and the loop continues to iterate over all
pageblocks trying to isolate and migrate pages. If a small number of
very large memcgs happen to be oom, however, these attempts will mostly
be futile leading to an enormous amout of cpu consumption due to the
page migration failures.
This patch will short circuit and fail memory compaction if
migrate_pages() returns -ENOMEM. COMPACT_PARTIAL is returned in case
some migrations were successful so that the page allocator will retry.
Signed-off-by: David Rientjes <rientjes@google.com>
Acked-by: Mel Gorman <mgorman@suse.de>
Cc: Minchan Kim <minchan@kernel.org>
Cc: Kamezawa Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Cc: Rik van Riel <riel@redhat.com>
Cc: Andrea Arcangeli <aarcange@redhat.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit dbf0e4c725 upstream.
Quite a few ASUS computers experience a nasty problem, related to the
EHCI controllers, when going into system suspend. It was observed
that the problem didn't occur if the controllers were not put into the
D3 power state before starting the suspend, and commit
151b612847 (USB: EHCI: fix crash during
suspend on ASUS computers) was created to do this.
It turned out this approach messed up other computers that didn't have
the problem -- it prevented USB wakeup from working. Consequently
commit c2fb8a3fa2 (USB: add
NO_D3_DURING_SLEEP flag and revert 151b612847) was merged; it
reverted the earlier commit and added a whitelist of known good board
names.
Now we know the actual cause of the problem. Thanks to AceLan Kao for
tracking it down.
According to him, an engineer at ASUS explained that some of their
BIOSes contain a bug that was added in an attempt to work around a
problem in early versions of Windows. When the computer goes into S3
suspend, the BIOS tries to verify that the EHCI controllers were first
quiesced by the OS. Nothing's wrong with this, but the BIOS does it
by checking that the PCI COMMAND registers contain 0 without checking
the controllers' power state. If the register isn't 0, the BIOS
assumes the controller needs to be quiesced and tries to do so. This
involves making various MMIO accesses to the controller, which don't
work very well if the controller is already in D3. The end result is
a system hang or memory corruption.
Since the value in the PCI COMMAND register doesn't matter once the
controller has been suspended, and since the value will be restored
anyway when the controller is resumed, we can work around the BIOS bug
simply by setting the register to 0 during system suspend. This patch
(as1590) does so and also reverts the second commit mentioned above,
which is now unnecessary.
In theory we could do this for every PCI device. However to avoid
introducing new problems, the patch restricts itself to EHCI host
controllers.
Finally the affected systems can suspend with USB wakeup working
properly.
Reference: https://bugzilla.kernel.org/show_bug.cgi?id=37632
Reference: https://bugzilla.kernel.org/show_bug.cgi?id=42728
Based-on-patch-by: AceLan Kao <acelan.kao@canonical.com>
Signed-off-by: Alan Stern <stern@rowland.harvard.edu>
Tested-by: Dâniel Fraga <fragabr@gmail.com>
Tested-by: Javier Marcet <jmarcet@gmail.com>
Tested-by: Andrey Rahmatullin <wrar@wrar.name>
Tested-by: Oleksij Rempel <bug-track@fisher-privat.net>
Tested-by: Pavel Pisa <pisa@cmp.felk.cvut.cz>
Acked-by: Bjorn Helgaas <bhelgaas@google.com>
Acked-by: Rafael J. Wysocki <rjw@sisk.pl>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2d4f4f3384 upstream.
This bug has been present ever since data-check was introduce
in 2.6.16. However it would only fire if a data-check were
done on a degraded array, which was only possible if the array
has 3 or more devices. This is certainly possible, but is quite
uncommon.
Since hot-replace was added in 3.3 it can happen more often as
the same condition can arise if not all possible replacements are
present.
The problem is that as soon as we submit the last read request, the
'r1_bio' structure could be freed at any time, so we really should
stop looking at it. If the last device is being read from we will
stop looking at it. However if the last device is not due to be read
from, we will still check the bio pointer in the r1_bio, but the
r1_bio might already be free.
So use the read_targets counter to make sure we stop looking for bios
to submit as soon as we have submitted them all.
This fix is suitable for any -stable kernel since 2.6.16.
Reported-by: Arnold Schulz <arnysch@gmx.net>
Signed-off-by: NeilBrown <neilb@suse.de>
[bwh: Backported to 3.2: no doubling of conf->raid_disks; we don't have
hot-replace support]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6ef1b512f4 upstream.
fill_result_tf() grabs the taskfile flags from the originating qc which
sas_ata_qc_fill_rtf() promptly overwrites. The presence of an
ata_taskfile in the sata_device makes it tempting to just copy the full
contents in sas_ata_qc_fill_rtf(). However, libata really only wants
the fis contents and expects the other portions of the taskfile to not
be touched by ->qc_fill_rtf. To that end store a fis buffer in the
sata_device and use ata_tf_from_fis() like every other ->qc_fill_rtf()
implementation.
Reported-by: Praveen Murali <pmurali@logicube.com>
Tested-by: Praveen Murali <pmurali@logicube.com>
Signed-off-by: Dan Williams <dan.j.williams@intel.com>
Signed-off-by: James Bottomley <JBottomley@Parallels.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 476a7eeb60 upstream.
Commit 300bab9770 (hwspinlock/core: register a bank of hwspinlocks in a
single API call, 2011-09-06) introduced 'hwspin_lock_register_single()'
to register numerous (a bank of) hwspinlock instances in a single API,
'hwspin_lock_register()'.
At which time, 'hwspin_lock_register()' accidentally passes 'local IDs'
to 'hwspin_lock_register_single()', despite that ..._single() requires
'global IDs' to register hwspinlocks.
We have to convert into global IDs by supplying the missing 'base_id'.
Signed-off-by: Shinya Kuribayashi <shinya.kuribayashi.px@renesas.com>
[ohad: fix error path of hwspin_lock_register, too]
Signed-off-by: Ohad Ben-Cohen <ohad@wizery.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 596fd46268 upstream.
We don't need to open code the divide function, just use div_u64 that
already exists and do the same job. While this is a straightforward
clean up, there is more to that, the real motivation for this.
While building on a cross compiling environment in armel, using gcc
4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5), I was getting the following build
error:
ERROR: "__aeabi_uldivmod" [drivers/mtd/nand/nandsim.ko] undefined!
After investigating with objdump and hand built assembly version
generated with the compiler, I narrowed __aeabi_uldivmod as being
generated from the divide function. When nandsim.c is built with
-fno-inline-functions-called-once, that happens when
CONFIG_DEBUG_SECTION_MISMATCH is enabled, the do_div optimization in
arch/arm/include/asm/div64.h doesn't work as expected with the open
coded divide function: even if the do_div we are using doesn't have a
constant divisor, the compiler still includes the else parts of the
optimized do_div macro, and translates the divisions there to use
__aeabi_uldivmod, instead of only calling __do_div_asm -> __do_div64 and
optimizing/removing everything else out.
So to reproduce, gcc 4.6 plus CONFIG_DEBUG_SECTION_MISMATCH=y and
CONFIG_MTD_NAND_NANDSIM=m should do it, building on armel.
After this change, the compiler does the intended thing even with
-fno-inline-functions-called-once, and optimizes out as expected the
constant handling in the optimized do_div on arm. As this also avoids a
build issue, I'm marking for Stable, as I think is applicable for this
case.
Signed-off-by: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Acked-by: Nicolas Pitre <nico@linaro.org>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 5167e8d541 upstream.
Thanks to Charles Wang for spotting the defects in the current code:
- If we go idle during the sample window -- after sampling, we get a
negative bias because we can negate our own sample.
- If we wake up during the sample window we get a positive bias
because we push the sample to a known active period.
So rewrite the entire nohz load-avg muck once again, now adding
copious documentation to the code.
Reported-and-tested-by: Doug Smythies <dsmythies@telus.net>
Reported-and-tested-by: Charles Wang <muming.wq@gmail.com>
Signed-off-by: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Andrew Morton <akpm@linux-foundation.org>
Link: http://lkml.kernel.org/r/1340373782.18025.74.camel@twins
[ minor edits ]
Signed-off-by: Ingo Molnar <mingo@kernel.org>
[bwh: Backported to 3.2: adjust filenames, context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8cd578b6e2 upstream.
Not paying attention to the value being set is a bad thing because it
means that we'll not set the hardware up to reflect what was requested.
Not setting the hardware up to reflect what was requested means that the
caller won't get the results they wanted.
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 8bea2bd37d upstream.
The host controller port status register supports CAS (Cold Attach
Status) bit. This bit could be set when USB3.0 device is connected
when system is in Sx state. When the system wakes to S0 this port
status with CAS bit is reported and this port can't be used by any
device.
When CAS bit is set the port should be reset by warm reset. This
was not supported by xhci driver.
The issue was found when pendrive was connected to suspended
platform. The link state of "Compliance Mode" was reported together
with CAS bit. This link state was also not supported by xhci and
core/hub.c.
The CAS bit is defined only for xhci root hub port and it is
not supported on regular hubs. The link status is used to force
warm reset on port. Make the USB core issue a warm reset when port
is in ether the 'inactive' or 'compliance mode'. Change the xHCI driver
to report 'compliance mode' when the CAS is set. This force warm reset
on the root hub port.
This patch should be backported to stable kernels as old as 3.2, that
contain the commit 10d674a82e "USB: When
hot reset for USB3 fails, try warm reset."
Signed-off-by: Stanislaw Ledwon <staszek.ledwon@linux.intel.com>
Signed-off-by: Sarah Sharp <sarah.a.sharp@linux.intel.com>
Acked-by: Andiry Xu <andiry.xu@amd.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ac1534a55d upstream.
When a device is added to the system at runtime the AMD
IOMMU driver initializes the necessary data structures to
handle translation for it. But it forgets to change the
per-device dma_ops to point to the AMD IOMMU driver. So
mapping actually never happens and all DMA accesses end in
an IO_PAGE_FAULT. Fix this.
Reported-by: Stefan Assmann <sassmann@redhat.com>
Signed-off-by: Joerg Roedel <joerg.roedel@amd.com>
[bwh: Backported to 3.2:
- Adjust context
- Use global iommu_pass_through; there is no per-device pass_through]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f2f12b6fc0 upstream.
The iommu_shutdown callback is not initialized when the AMD
IOMMU driver runs in passthrough mode. Fix that by moving
the callback initialization before the check for
passthrough mode.
Signed-off-by: Shuah Khan <shuah.khan@hp.com>
Signed-off-by: Joerg Roedel <joerg.roedel@amd.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6d93592807 upstream.
Sometimes, warnings about ioctls to partition happen often enough that they
form majority of the warnings in the kernel log and users complain. In some
cases warnings are about ioctls such as SG_IO so it's not good to get rid of
the warnings completely as they can ease debugging of userspace problems
when ioctl is refused.
Since I have seen warnings from lots of commands, including some proprietary
userspace applications, I don't think disallowing the ioctls for processes
with CAP_SYS_RAWIO will happen in the near future if ever. So lets just
stop warning for processes with CAP_SYS_RAWIO for which ioctl is allowed.
CC: Paolo Bonzini <pbonzini@redhat.com>
CC: James Bottomley <JBottomley@parallels.com>
CC: linux-scsi@vger.kernel.org
Acked-by: Paolo Bonzini <pbonzini@redhat.com>
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
[bwh: Backported to 3.2: use ENOTTY, not ENOIOCTLCMD]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f2ebd422f7 upstream.
kvm_set_irq() has an internal buffer of three irq routing entries, allowing
connecting a GSI to three IRQ chips or on MSI. However setup_routing_entry()
does not properly enforce this, allowing three irqchip routes followed by
an MSI route to overflow the buffer.
Fix by ensuring that an MSI entry is added to an empty list.
Signed-off-by: Avi Kivity <avi@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b92946e291 upstream.
There're several reasons that the vectors need to be validated:
- Return error when caller provides vectors whose num is greater than UIO_MAXIOV.
- Linearize part of skb when userspace provides vectors grater than MAX_SKB_FRAGS.
- Return error when userspace provides vectors whose total length may exceed
- MAX_SKB_FRAGS * PAGE_SIZE.
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 01d6657b38 upstream.
Current the SKBTX_DEV_ZEROCOPY is set unconditionally after
zerocopy_sg_from_iovec(), this would lead NULL pointer when macvtap
fails to build zerocopy skb because destructor_arg was not
initialized. Solve this by set this flag after the skb were built
successfully.
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 02ce04bb3d upstream.
When get_user_pages_fast() fails to get all requested pages, we could not use
kfree_skb() to free it as it has not been put in the skb fragments. So we need
to call put_page() instead.
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4ef67ebedf upstream.
As the skb fragment were pinned/built from user pages, we should
account the page instead of length for truesize.
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3afc9621f1 upstream.
This patch fixes the offset calculation when building skb:
- offset1 were used as skb data offset not vector offset
- reset offset to zero only when we advance to next vector
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: Michael S. Tsirkin <mst@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 685f50f918 upstream.
Don't allocate the legacy idmapper tables until we actually need
them.
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Reviewed-by: Jeff Layton <jlayton@redhat.com>
[bwh: Backported to 3.2: adjust context in nfs_idmap_delete()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit d073e9b541 upstream.
Instead of pre-allocating the storage for all the strings, we can
significantly reduce the size of that table by doing the allocation
when we do the downcall.
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
Reviewed-by: Jeff Layton <jlayton@redhat.com>
[bwh: Backported to 3.2: adjust context in nfs_idmap_delete()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 90481622d7 upstream.
hugetlbfs_{get,put}_quota() are badly named. They don't interact with the
general quota handling code, and they don't much resemble its behaviour.
Rather than being about maintaining limits on on-disk block usage by
particular users, they are instead about maintaining limits on in-memory
page usage (including anonymous MAP_PRIVATE copied-on-write pages)
associated with a particular hugetlbfs filesystem instance.
Worse, they work by having callbacks to the hugetlbfs filesystem code from
the low-level page handling code, in particular from free_huge_page().
This is a layering violation of itself, but more importantly, if the
kernel does a get_user_pages() on hugepages (which can happen from KVM
amongst others), then the free_huge_page() can be delayed until after the
associated inode has already been freed. If an unmount occurs at the
wrong time, even the hugetlbfs superblock where the "quota" limits are
stored may have been freed.
Andrew Barry proposed a patch to fix this by having hugepages, instead of
storing a pointer to their address_space and reaching the superblock from
there, had the hugepages store pointers directly to the superblock,
bumping the reference count as appropriate to avoid it being freed.
Andrew Morton rejected that version, however, on the grounds that it made
the existing layering violation worse.
This is a reworked version of Andrew's patch, which removes the extra, and
some of the existing, layering violation. It works by introducing the
concept of a hugepage "subpool" at the lower hugepage mm layer - that is a
finite logical pool of hugepages to allocate from. hugetlbfs now creates
a subpool for each filesystem instance with a page limit set, and a
pointer to the subpool gets added to each allocated hugepage, instead of
the address_space pointer used now. The subpool has its own lifetime and
is only freed once all pages in it _and_ all other references to it (i.e.
superblocks) are gone.
subpools are optional - a NULL subpool pointer is taken by the code to
mean that no subpool limits are in effect.
Previous discussion of this bug found in: "Fix refcounting in hugetlbfs
quota handling.". See: https://lkml.org/lkml/2011/8/11/28 or
http://marc.info/?l=linux-mm&m=126928970510627&w=1
v2: Fixed a bug spotted by Hillf Danton, and removed the extra parameter to
alloc_huge_page() - since it already takes the vma, it is not necessary.
Signed-off-by: Andrew Barry <abarry@cray.com>
Signed-off-by: David Gibson <david@gibson.dropbear.id.au>
Cc: Hugh Dickins <hughd@google.com>
Cc: Mel Gorman <mgorman@suse.de>
Cc: Minchan Kim <minchan.kim@gmail.com>
Cc: Hillf Danton <dhillf@gmail.com>
Cc: Paul Mackerras <paulus@samba.org>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2: adjust context to apply after commit
c50ac05081 'hugetlb: fix resv_map leak in
error path', backported in 3.2.20]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1d526fc91b upstream.
Currently the value reported for max_batch_time is really the
value of min_batch_time.
Reported-by: Russell Coker <russell@coker.com.au>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 96dcadc2fd upstream.
Adding rate limit on `Lock reclaim failed` messages since it could fill
up system logs
Signed-off-by: William Dauchy <wdauchy@gmail.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: add the 'NFS:' prefix at the same time]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6ead629b27 upstream.
I keep getting the following messages on the log buffer:
[ 2167.097507] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2281.331305] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2281.332539] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2329.876605] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2329.877354] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2462.280756] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
[ 2615.651689] ieee80211 phy0: brcms_c_dotxstatus: INTERMEDIATE but not AMPDU
From the code comment I understand that this something that can -
and does, quite frequently - happen.
Signed-off-by: Eldad Zack <eldad@fogrefinery.com>
Acked-by: Franky Lin<frankyl@broadcom.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 620c231c7a upstream.
scripts/depmod.sh checks for the output of '-V' expecting that it has
module-init-tools in it. It's a hack to prevent users from using
modutils instead of module-init-tools, that only works with 2.4.x
kernels. This however prints an annoying warning for kmod tool, that is
currently replacing module-init-tools.
Rather than putting another check for kmod's version, just remove it
since users of 2.4.x kernel are unlikely to upgrade to 3.x, and if they
do, let depmod fail in that case because they should know what they are
doing.
Signed-off-by: Lucas De Marchi <lucas.demarchi@profusion.mobi>
Acked-by: WANG Cong <amwang@redhat.com>
Acked-By: Kay Sievers <kay.sievers@vrfy.org>
Signed-off-by: Michal Marek <mmarek@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1c8ecf80fd upstream.
With base on latest findings, RC6p seems to be respondible for RC6-related
issues on Sandy Bridge platform. To work-around those issues, the previous
solution was to completely disable RC6 on Sandy Bridge for the past few
releases, even if plain RC6 was not giving any issues.
What this patch does is preventing RC6p from being enabled on Sandy Bridge
even if users enable RC6 via a kernel parameter. So it won't change the
defaults in any way, but will ensure that if users do enable RC6 manually
it won't break their machines by enabling this extra state.
Proper fix for this (enabling specific RC6 states according to the GPU
generation) were proposed for the -next kernel, but we are too late in the
release process now to pick such changes.
Acked-by: Keith Packard <keithp@keithp.com>
Signed-off-by: Eugeni Dodonov <eugeni.dodonov@intel.com>
Signed-off-by: Jesse Barnes <jbarnes@virtuousgeek.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 0fde0a8cfd upstream.
Fix:
BUG: sleeping function called from invalid context at kernel/workqueue.c:2547
in_atomic(): 1, irqs_disabled(): 0, pid: 629, name: wpa_supplicant
2 locks held by wpa_supplicant/629:
#0: (rtnl_mutex){+.+.+.}, at: [<c08b2b84>] rtnl_lock+0x14/0x20
#1: (&trigger->leddev_list_lock){.+.?..}, at: [<c0867f41>] led_trigger_event+0x21/0x80
Pid: 629, comm: wpa_supplicant Not tainted 3.3.0-0.rc3.git5.1.fc17.i686
Call Trace:
[<c046a9f6>] __might_sleep+0x126/0x1d0
[<c0457d6c>] wait_on_work+0x2c/0x1d0
[<c045a09a>] __cancel_work_timer+0x6a/0x120
[<c045a160>] cancel_delayed_work_sync+0x10/0x20
[<f7dd3c22>] rtl8187_led_brightness_set+0x82/0xf0 [rtl8187]
[<c0867f7c>] led_trigger_event+0x5c/0x80
[<f7ff5e6d>] ieee80211_led_radio+0x1d/0x40 [mac80211]
[<f7ff3583>] ieee80211_stop_device+0x13/0x230 [mac80211]
Removing _sync is ok, because if led_on work is currently running
it will be finished before led_off work start to perform, since
they are always queued on the same mac80211 local->workqueue.
Bugzilla: https://bugzilla.redhat.com/show_bug.cgi?id=795176
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Larry Finger <Larry.Finger@lwfinger.net>
Acked-by: Hin-Tak Leung <htl10@users.sourceforge.net>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fdf5af0daf upstream.
Denys Fedoryshchenko reported that SYN+FIN attacks were bringing his
linux machines to their limits.
Dont call conn_request() if the TCP flags includes SYN flag
Reported-by: Denys Fedoryshchenko <denys@visp.net.lb>
Signed-off-by: Eric Dumazet <eric.dumazet@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fab363b5ff upstream.
There isn't locking setting STRIPE_DELAYED and STRIPE_PREREAD_ACTIVE bits, but
the two bits have relationship. A delayed stripe can be moved to hold list only
when preread active stripe count is below IO_THRESHOLD. If a stripe has both
the bits set, such stripe will be in delayed list and preread count not 0,
which will make such stripe never leave delayed list.
Signed-off-by: Shaohua Li <shli@fusionio.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3be324a94d upstream.
This enable the driver for everything that look like
a laptop and is from vendor "SAMSUNG ELECTRONICS CO., LTD.".
Note that laptop supported by samsung-q10 seem to have a different
vendor strict.
Also remove every log output until we know that we have a SABI interface
(except if the driver is forced to load, or debug is enabled).
Keeping a whitelist of laptop with a model granularity is something that can't
work without close vendor cooperation (and we don't have that).
Signed-off-by: Corentin Chary <corentincj@iksaif.net>
Acked-by: Greg Kroah-Hartman <gregkh@suse.de>
Signed-off-by: Matthew Garrett <mjg@redhat.com>
[bwh: Backported to 3.2:
- Adjust context
- Drop changes relating to ACPI video]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 332a2e1244 upstream.
We already use them for openat() and friends, but fchdir() also wants to
be able to use O_PATH file descriptors. This should make it comparable
to the O_SEARCH of Solaris. In particular, O_PATH allows you to access
(not-quite-open) a directory you don't have read persmission to, only
execute permission.
Noticed during development of multithread support for ksh93.
Reported-by: ольга крыжановская <olga.kryzhanovska@gmail.com>
Cc: Al Viro <viro@zeniv.linux.org.uk>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 863555be0c upstream.
Use rcu_dereference_protected to tell rcu that the ft_lport_lock
is held during ft_lport_create. This resolved "suspicious RCU usage"
warnings when debugging options are turned on.
Signed-off-by: Mark Rustad <mark.d.rustad@intel.com>
Tested-by: Ross Brattain <ross.b.brattain@intel.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9ab4233dd0 upstream.
Otherwise the code races with munmap (causing a use-after-free
of the vma) or with close (causing a use-after-free of the struct
file).
The bug was introduced by commit 90ed52ebe4 ("[PATCH] holepunch: fix
mmap_sem i_mutex deadlock")
Cc: Hugh Dickins <hugh@veritas.com>
Cc: Miklos Szeredi <mszeredi@suse.cz>
Cc: Badari Pulavarty <pbadari@us.ibm.com>
Cc: Nick Piggin <npiggin@suse.de>
Signed-off-by: Andy Lutomirski <luto@amacapital.net>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
[bwh: Backported to 3.2:
- Adjust context
- madvise_remove() calls vmtruncate_range(), not do_fallocate()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 48f8b64129 upstream.
The intent here was clearly to set result to true if the 0x40000000 flag
was set. But instead there was a | vs & typo and we always set result
to true.
Artem: check the spec at
wiki.laptop.org/images/5/5c/88ALP01_Datasheet_July_2007.pdf
and this fix looks correct.
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Artem Bityutskiy <artem.bityutskiy@linux.intel.com>
Signed-off-by: David Woodhouse <David.Woodhouse@intel.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2dfd06036b upstream.
Ocfs2 uses kiocb.*private as a flag of unsigned long size. In
commit a11f7e6 ocfs2: serialize unaligned aio, the unaligned
io flag is involved in it to serialize the unaligned aio. As
*private is not initialized in init_sync_kiocb() of do_sync_write(),
this unaligned io flag may be unexpectly set in an aligned dio.
And this will cause OCFS2_I(inode)->ip_unaligned_aio decreased
to -1 in ocfs2_dio_end_io(), thus the following unaligned dio
will hang forever at ocfs2_aiodio_wait() in ocfs2_file_aio_write().
Signed-off-by: Junxiao Bi <junxiao.bi@oracle.com>
Acked-by: Jeff Moyer <jmoyer@redhat.com>
Signed-off-by: Joel Becker <jlbec@evilplan.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 3e5d3c35a6 upstream.
The unaligned io flag is set in the kiocb when an unaligned
dio is issued, it should be cleared even when the dio fails,
or it may affect the following io which are using the same
kiocb.
Signed-off-by: Junxiao Bi <junxiao.bi@oracle.com>
Signed-off-by: Joel Becker <jlbec@evilplan.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit ec01d738a1 upstream.
When the server doesn't advertise CAP_LARGE_READ_X, then MS-CIFS states
that you must cap the size of the read at the client's MaxBufferSize.
Unfortunately, testing with many older servers shows that they often
can't service a read larger than their own MaxBufferSize.
Since we can't assume what the server will do in this situation, we must
be conservative here for the default. When the server can't do large
reads, then assume that it can't satisfy any read larger than its
MaxBufferSize either.
Luckily almost all modern servers can do large reads, so this won't
affect them. This is really just for older win9x and OS/2 era servers.
Also, note that this patch just governs the default rsize. The admin can
always override this if he so chooses.
Reported-by: David H. Durgee <dhdurgee@acm.org>
Signed-off-by: Jeff Layton <jlayton@redhat.com>
Signed-off-by: Steven French <sfrench@w500smf.(none)>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b6305567e7 upstream.
While we are resolving directory modifications in the
tree log, we are triggering delayed metadata updates to
the filesystem btrees.
This commit forces the delayed updates to run so the
replay code can find any modifications done. It stops
us from crashing because the directory deleltion replay
expects items to be removed immediately from the tree.
Signed-off-by: Chris Mason <chris.mason@fusionio.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 149ddd83a9 ]
This ensures that bridges created with brctl(8) or ioctl(2) directly
also carry IFLA_LINKINFO when dumped over netlink. This also allows
to create a bridge with ioctl(2) and delete it with RTM_DELLINK.
Signed-off-by: Thomas Graf <tgraf@suug.ch>
Signed-off-by: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit d189634eca ]
/proc/net/ipv6_route reflects the contents of fib_table_hash. The proc
handler is installed in ip6_route_net_init() whereas fib_table_hash is
allocated in fib6_net_init() _after_ the proc handler has been installed.
This opens up a short time frame to access fib_table_hash with its pants
down.
Move the registration of the proc files to a later point in the init
order to avoid the race.
Tested :-)
Signed-off-by: Thomas Graf <tgraf@suug.ch>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 954fba0274 ]
Bogdan Hamciuc diagnosed and fixed following bug in netpoll_send_udp() :
"skb->len += len;" instead of "skb_put(skb, len);"
Meaning that _if_ a network driver needs to call skb_realloc_headroom(),
only packet headers would be copied, leaving garbage in the payload.
However the skb_realloc_headroom() must be avoided as much as possible
since it requires memory and netpoll tries hard to work even if memory
is exhausted (using a pool of preallocated skbs)
It appears netpoll_send_udp() reserved 16 bytes for the ethernet header,
which happens to work for typicall drivers but not all.
Right thing is to use LL_RESERVED_SPACE(dev)
(And also add dev->needed_tailroom of tailroom)
This patch combines both fixes.
Many thanks to Bogdan for raising this issue.
Reported-by: Bogdan Hamciuc <bogdan.hamciuc@freescale.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Tested-by: Bogdan Hamciuc <bogdan.hamciuc@freescale.com>
Cc: Herbert Xu <herbert@gondor.apana.org.au>
Cc: Neil Horman <nhorman@tuxdriver.com>
Reviewed-by: Neil Horman <nhorman@tuxdriver.com>
Reviewed-by: Cong Wang <xiyou.wangcong@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 5ee31c6898 ]
In the transmit path of the bonding driver, skb->cb is used to
stash the skb->queue_mapping so that the bonding device can set its
own queue mapping. This value becomes corrupted since the skb->cb is
also used in __dev_xmit_skb.
When transmitting through bonding driver, bond_select_queue is
called from dev_queue_xmit. In bond_select_queue the original
skb->queue_mapping is copied into skb->cb (via bond_queue_mapping)
and skb->queue_mapping is overwritten with the bond driver queue.
Subsequently in dev_queue_xmit, __dev_xmit_skb is called which writes
the packet length into skb->cb, thereby overwriting the stashed
queue mappping. In bond_dev_queue_xmit (called from hard_start_xmit),
the queue mapping for the skb is set to the stashed value which is now
the skb length and hence is an invalid queue for the slave device.
If we want to save skb->queue_mapping into skb->cb[], best place is to
add a field in struct qdisc_skb_cb, to make sure it wont conflict with
other layers (eg : Qdiscc, Infiniband...)
This patchs also makes sure (struct qdisc_skb_cb)->data is aligned on 8
bytes :
netem qdisc for example assumes it can store an u64 in it, without
misalignment penalty.
Note : we only have 20 bytes left in (struct qdisc_skb_cb)->data[].
The largest user is CHOKe and it fills it.
Based on a previous patch from Tom Herbert.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Reported-by: Tom Herbert <therbert@google.com>
Cc: John Fastabend <john.r.fastabend@intel.com>
Cc: Roland Dreier <roland@kernel.org>
Acked-by: Neil Horman <nhorman@tuxdriver.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 16b0dc29c1 ]
Trying to "modprobe dummy numdummies=30000" triggers :
INFO: rcu_sched self-detected stall on CPU { 8} (t=60000 jiffies)
After this splat, RTNL is locked and reboot is needed.
We must call cond_resched() to avoid this, even holding RTNL.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit cd8f76c0a0 ]
As soon as hardware is notified of a transmit, we no longer can assume
skb can be dereferenced, as TX completion might have freed the packet.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Sathya Perla <sathya.perla@emulex.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 5ff0feac88 ]
The newer flavors of Yukon II use a different method for receive
checksum offload. This is indicated in the driver by the SKY2_HW_NEW_LE
flag. On these newer chips, the BMU_ENA_RX_CHKSUM should not be set.
The driver would get incorrectly toggle the bit, enabling the old
checksum logic on these chips and cause a BUG_ON() assertion. If
receive checksum was toggled via ethtool.
Reported-by: Kirill Smelkov <kirr@mns.spb.ru>
Signed-off-by: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 4399a4df98 ]
Commit 081b1b1bb2 (l2tp: fix l2tp_ip_sendmsg() route handling) added
a race, in case IP route cache is disabled.
In this case, we should not do the dst_release(&rt->dst), since it'll
free the dst immediately, instead of waiting a RCU grace period.
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: James Chapman <jchapman@katalix.com>
Cc: Denys Fedoryshchenko <denys@visp.net.lb>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit 20e2a86485 ]
When NetLabel is not enabled, e.g. CONFIG_NETLABEL=n, and the system
receives a CIPSO tagged packet it is dropped (cipso_v4_validate()
returns non-zero). In most cases this is the correct and desired
behavior, however, in the case where we are simply forwarding the
traffic, e.g. acting as a network bridge, this becomes a problem.
This patch fixes the forwarding problem by providing the basic CIPSO
validation code directly in ip_options_compile() without the need for
the NetLabel or CIPSO code. The new validation code can not perform
any of the CIPSO option label/value verification that
cipso_v4_validate() does, but it can verify the basic CIPSO option
format.
The behavior when NetLabel is enabled is unchanged.
Signed-off-by: Paul Moore <pmoore@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
[ Upstream commit cc9b17ad29 ]
We need to validate the number of pages consumed by data_len, otherwise frags
array could be overflowed by userspace. So this patch validate data_len and
return -EMSGSIZE when data_len may occupies more frags than MAX_SKB_FRAGS.
Signed-off-by: Jason Wang <jasowang@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 7deabca0ac upstream.
We can stall RCU processing on SMP platforms if a CPU sits in its idle
loop for a long time. This happens because we don't call irq_enter()
and irq_exit() around generic_smp_call_function_interrupt() and
friends. Add the necessary calls, and remove the one from within
ipi_timer(), so that they're all in a common place.
Signed-off-by: Russell King <rmk+kernel@arm.linux.org.uk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1df2ae31c7 upstream.
Add sanity checks when loading sparing table from disk to avoid accessing
unallocated memory or writing to it.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit adee11b208 upstream.
Check provided length of partition table so that (possibly maliciously)
corrupted partition table cannot cause accessing data beyond current buffer.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 858faa57dd upstream
backported for linux-3.2.y, linux-3.3.y, linux-3.4.y
add_virtual_intf() needs to return an ERR_PTR(), instead of NULL,
on errors, otherwise cfg80211 will crash.
Reported-by: Johannes Berg <johannes@sipsolutions.net>
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6e1c39c6b0 upstream.
The recent fix for power-map controls (commit b0791dda81) caused
regressions on some other HP laptops. They have fixed pins but these
pins are exposed as jack-detectable. Thus the driver tries to control
the power-map dynamically per jack detection where it never gets on.
This patch adds the check of connection and it assumes the no jack
detection is available for fixed pins no matter what pin capability
says.
BugLink: http://bugs.launchpad.net/bugs/1013183
Reported-by: Luis Henriques <luis.henriques@canonical.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit b0239faaf8 upstream.
If CONFIG_DM_DEBUG_SPACE_MAPS is enabled and memory is fragmented and a
sufficiently-large metadata device is used in a thin pool then the space
map checker will fail to allocate the memory it requires.
Switch from kmalloc to vmalloc to allow larger virtually contiguous
allocations for the space map checker's internal count arrays.
Reported-by: Vivek Goyal <vgoyal@redhat.com>
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 62662303e7 upstream.
If CONFIG_DM_DEBUG_SPACE_MAPS is enabled and dm_sm_checker_create()
fails, dm_tm_create_internal() would still return success even though it
cleaned up all resources it was supposed to have created. This will
lead to a kernel crash:
general protection fault: 0000 [#1] SMP DEBUG_PAGEALLOC
...
RIP: 0010:[<ffffffff81593659>] [<ffffffff81593659>] dm_bufio_get_block_size+0x9/0x20
Call Trace:
[<ffffffff81599bae>] dm_bm_block_size+0xe/0x10
[<ffffffff8159b8b8>] sm_ll_init+0x78/0xd0
[<ffffffff8159c1a6>] sm_ll_new_disk+0x16/0xa0
[<ffffffff8159c98e>] dm_sm_disk_create+0xfe/0x160
[<ffffffff815abf6e>] dm_pool_metadata_open+0x16e/0x6a0
[<ffffffff815aa010>] pool_ctr+0x3f0/0x900
[<ffffffff8158d565>] dm_table_add_target+0x195/0x450
[<ffffffff815904c4>] table_load+0xe4/0x330
[<ffffffff815917ea>] ctl_ioctl+0x15a/0x2c0
[<ffffffff81591963>] dm_ctl_ioctl+0x13/0x20
[<ffffffff8116a4f8>] do_vfs_ioctl+0x98/0x560
[<ffffffff8116aa51>] sys_ioctl+0x91/0xa0
[<ffffffff81869f52>] system_call_fastpath+0x16/0x1b
Fix the space map checker code to return an appropriate ERR_PTR and have
dm_sm_disk_create() and dm_tm_create_internal() check for it with
IS_ERR.
Reported-by: Vivek Goyal <vgoyal@redhat.com>
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 25d7cd6faa upstream.
Cleanup the shadow table before destroying the transaction manager.
Reference: leak was identified with kmemleak when running
test_discard_random_sectors in the thinp-test-suite.
Signed-off-by: Mike Snitzer <snitzer@redhat.com>
Signed-off-by: Alasdair G Kergon <agk@redhat.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 9f846a16d2 upstream.
Especially vesafb likes to map everything as uc- (yikes), and if that
mapping hangs around still while we try to map the gtt as wc the
kernel will downgrade our request to uc-, resulting in abyssal
performance.
Unfortunately we can't do this as early as readon does (i.e. as the
first thing we do when initializing the hw) because our fb/mmio space
region moves around on a per-gen basis. So I've had to move it below
the gtt initialization, but that seems to work, too. The important
thing is that we do this before we set up the gtt wc mapping.
Now an altogether different question is why people compile their
kernels with vesafb enabled, but I guess making things just work isn't
bad per se ...
v2:
- s/radeondrmfb/inteldrmfb/
- fix up error handling
v3: Kill #ifdef X86, this is Intel after all. Noticed by Ben Widawsky.
v4: Jani Nikula complained about the pointless bool primary
initialization.
v5: Don't oops if we can't allocate, noticed by Chris Wilson.
v6: Resolve conflicts with agp rework and fixup whitespace.
This is commit e188719a28 in drm-next.
Backport to 3.5 -fixes queue requested by Dave Airlie - due to grub
using vesa on fedora their initrd seems to load vesafb before loading
the real kms driver. So tons more people actually experience a
dead-slow gpu. Hence also the Cc: stable.
Reported-and-tested-by: "Kilarski, Bernard R" <bernard.r.kilarski@intel.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Dave Airlie <airlied@redhat.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 055d3747db upstream.
commit 58c54fcca3
md/raid10: handle further errors during fix_read_error better.
in 3.1 added "r10_sync_page_io" which takes an IO size in sectors.
But we were passing the IO size in bytes!!!
This resulting in bio_add_page failing, and empty request being sent
down, and a consequent BUG_ON in scsi_lib.
[fix missing space in error message at same time]
This fix is suitable for 3.1.y and later.
Reported-by: Christian Balzer <chibi@gol.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 1850753d2e upstream.
In ops_run_io(), the call to md_wait_for_blocked_rdev will decrement
nr_pending so we lose the reference we hold on the rdev.
So atomic_inc it first to maintain the reference.
This bug was introduced by commit 73e92e51b7
md/raid5. Don't write to known bad block on doubtful devices.
which appeared in 3.0, so patch is suitable for stable kernels since
then.
Signed-off-by: majianpeng <majianpeng@gmail.com>
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 6c0544e255 upstream.
In chunk_aligned_read() we are adding data_offset before calling
is_badblock. But is_badblock also adds data_offset, so that is bad.
So move the addition of data_offset to after the call to
is_badblock.
This bug was introduced by commit 31c176ecdf
md/raid5: avoid reading from known bad blocks.
which first appeared in 3.0. So that patch is suitable for any
-stable kernel from 3.0.y onwards. However it will need minor
revision for most of those (as the comment didn't appear until
recently).
Signed-off-by: majianpeng <majianpeng@gmail.com>
Signed-off-by: NeilBrown <neilb@suse.de>
[bwh: Backported to 3.2: ignored missing comment]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit fc448a18ae upstream.
If a RAID10 has an odd number of chunks - as might happen when there
are an odd number of devices - the last chunk has no pair and so is
not mirrored. We don't store data there, but when recovering the last
device in an array we retry to recover that last chunk from a
non-existent location. This results in an error, and the recovery
aborts.
When we get to that last chunk we should just stop - there is nothing
more to do anyway.
This bug has been present since the introduction of RAID10, so the
patch is appropriate for any -stable kernel.
Reported-by: Christian Balzer <chibi@gol.com>
Tested-by: Christian Balzer <chibi@gol.com>
Signed-off-by: NeilBrown <neilb@suse.de>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 2f584a146a upstream.
Since we are taking a registers, this should never have been an sldi.
Talking to paulus offline, this is the correct fix.
Was introduced by:
commit 19ccb76a19
Author: Paul Mackerras <paulus@samba.org>
Date: Sat Jul 23 17:42:46 2011 +1000
Talking to paulus, this shouldn't be a literal.
Signed-off-by: Michael Neuling <mikey@neuling.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bc1d770291 upstream.
We have a bug report where the kernel hits a warning in the cpumask
code:
WARNING: at include/linux/cpumask.h:107
Which is:
WARN_ON_ONCE(cpu >= nr_cpumask_bits);
The backtrace is:
cpu_cmd
cmds
xmon_core
xmon
die
xmon is iterating through 0 to NR_CPUS. I'm not sure why we are still
open coding this but iterating above nr_cpu_ids is definitely a bug.
This patch iterates through all possible cpus, in case we issue a
system reset and CPUs in an offline state call in.
Perhaps the old code was trying to handle CPUs that were in the
partition but were never started (eg kexec into a kernel with an
nr_cpus= boot option). They are going to die way before we get into
xmon since we haven't set any kernel state up for them.
Signed-off-by: Anton Blanchard <anton@samba.org>
Signed-off-by: Benjamin Herrenschmidt <benh@kernel.crashing.org>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit c9fe573a65 upstream.
In sound/soc/codecs/tlv320aic3x.c
data = snd_soc_read(codec, AIC3X_PLL_PROGA_REG);
snd_soc_write(codec, AIC3X_PLL_PROGA_REG,
data | (pll_p << PLLP_SHIFT));
In the above code, pll-p value is OR'ed with previous value without
clearing it. Bug is not seen if pll-p value doesn't change across
Sampling frequency.
However on some platforms (like AM335x EVM-SK), pll-p may have different
values across different sampling frequencies. In such case, above code
configures the pll with a wrong value.
Because of this bug, when a audio stream is played with pll value
different from previous stream, audio is heard as differently(like its
stretched).
Signed-off-by: Hebbar, Gururaja <gururaja.hebbar@ti.com>
Signed-off-by: Mark Brown <broonie@opensource.wolfsonmicro.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 4b5ebccc40 upstream.
When receiving an "individually addressed" action frame, the
receiver is required to return it to the sender. mac80211
gets this wrong as it also returns group addressed (mcast)
frames to the sender. Fix this and update the reference to
the new 802.11 standards version since things were shuffled
around significantly.
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit bed3d9c0b7 upstream.
commit 7a532fe713
ath9k_hw: fix interpretation of the rx KeyMiss flag
This commit used the rx key miss indication to detect packets that were
passed from the hardware without being decrypted, however it seems that
this bit is not only undefined in the static WEP case, but also for
dynamically allocated WEP keys. This caused a regression when using
WEP-LEAP.
This patch fixes the regression by keeping track of which key indexes
refer to CCMP keys and only using the key miss indication for those.
Reported-by: Stanislaw Gruszka <sgruszka@redhat.com>
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit f03ba7e9a2 upstream.
After association, STA will go through eapol handshake with WPS
enabled AP. It's observed that WPS handshake fails with some 11n
AP. The reason for the failure is that the eapol packet is sent
via 11n frame aggregation.
The eapol packet should be sent directly without 11n aggregation.
This patch fixes the problem by adding WPS session control while
dequeuing Tx packets for transmission.
Signed-off-by: Stone Piao <piaoyun@marvell.com>
Signed-off-by: Avinash Patil <patila@marvell.com>
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
[bwh: Backported to 3.2: reformat the if-statement per earlier
upstream commit c65a30f35f]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 925839243d upstream.
Currently we check the sequence number of last packet received
against start_win. If a sequence hole is detected, start_win is
updated to next sequence number.
Since the rx sequence number is initialized to 0, a corner case
exists when BA setup happens immediately after association. As
0 is a valid sequence number, start_win gets increased to 1
incorrectly. This causes the first packet with sequence number 0
being dropped.
Initialize rx sequence number as 0xffff and skip adjusting
start_win if the sequence number remains 0xffff. The sequence
number will be updated once the first packet is received.
Signed-off-by: Stone Piao <piaoyun@marvell.com>
Signed-off-by: Avinash Patil <patila@marvell.com>
Signed-off-by: Kiran Divekar <dkiran@marvell.com>
Signed-off-by: Bing Zhao <bzhao@marvell.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 32587371ad upstream.
Fix a regression introduced by 7eaceaccab ("block: remove per-queue
plugging"). In that patch, Jens removed the whole mm_unplug_device()
function, which used to be the trigger to make umem start to work.
We need to implement unplugging to make umem start to work, or I/O will
never be triggered.
Signed-off-by: Tao Guo <Tao.Guo@emc.com>
Cc: Neil Brown <neilb@suse.de>
Cc: Jens Axboe <axboe@kernel.dk>
Cc: Shaohua Li <shli@kernel.org>
Acked-by: NeilBrown <neilb@suse.de>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
commit 047fe36052 upstream.
Dave Jones reported a kernel BUG at mm/slub.c:3474! triggered
by splice_shrink_spd() called from vmsplice_to_pipe()
commit 35f3d14dbb (pipe: add support for shrinking and growing pipes)
added capability to adjust pipe->buffers.
Problem is some paths don't hold pipe mutex and assume pipe->buffers
doesn't change for their duration.
Fix this by adding nr_pages_max field in struct splice_pipe_desc, and
use it in place of pipe->buffers where appropriate.
splice_shrink_spd() loses its struct pipe_inode_info argument.
Reported-by: Dave Jones <davej@redhat.com>
Signed-off-by: Eric Dumazet <edumazet@google.com>
Cc: Jens Axboe <axboe@kernel.dk>
Cc: Alexander Viro <viro@zeniv.linux.org.uk>
Cc: Tom Herbert <therbert@google.com>
Tested-by: Dave Jones <davej@redhat.com>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
[bwh: Backported to 3.2:
- Adjust context in vmsplice_to_pipe()
- Update one more call to splice_shrink_spd(), from skb_splice_bits()]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
2012-07-12 04:31:59 +01:00
866 changed files with 11356 additions and 5399 deletions
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
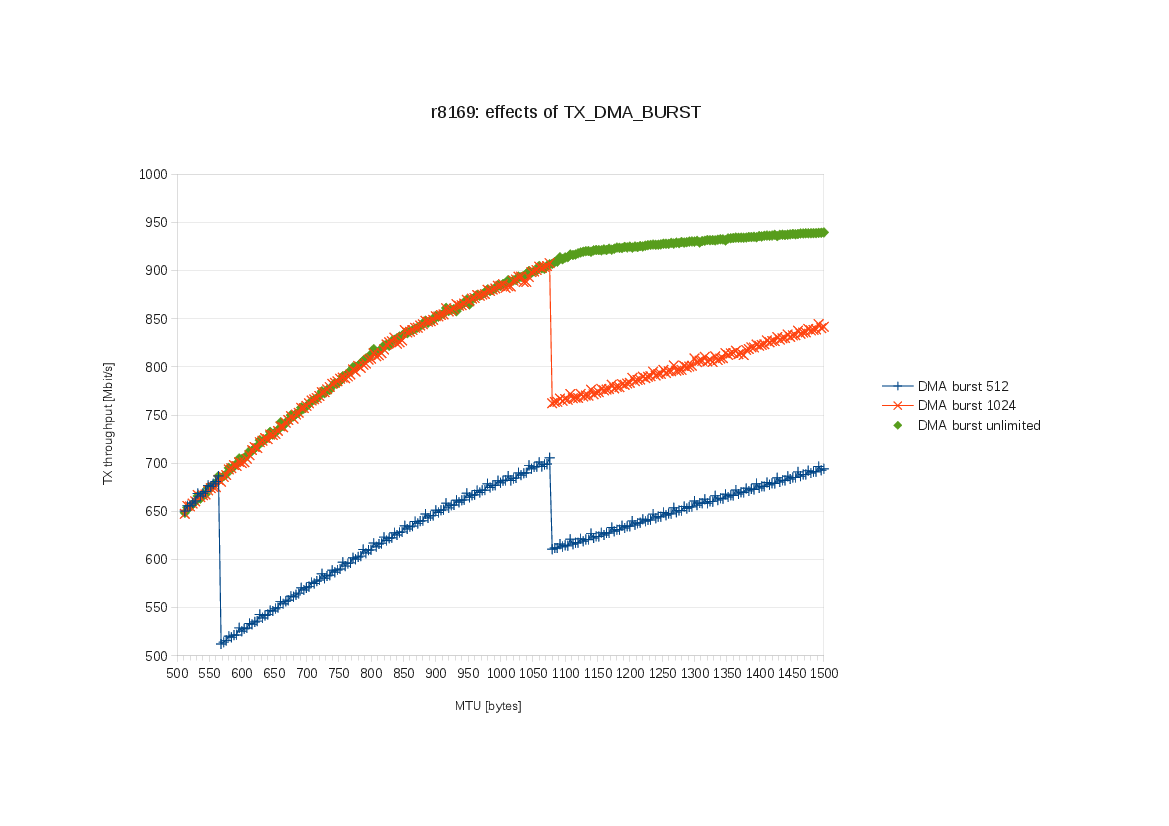{kind=link}